3.1 Data and Parameters in NLMs
The following information describes alignment of data and passing C parameters.
3.1.1 Data Alignment
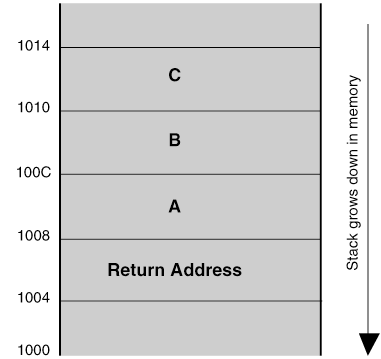
Data alignment describes data that is within the boundaries that are associated with each data type. Each data type, BYTE, WORD, LONG, and DOUBLE have rules where their starting addresses should begin. These rules are summarized in the following table.
A variable that does not fit in these boundaries is not aligned. For example, a LONG is four bytes, and should start on an address that is a multiple of four. If it does not start on the correct boundary, it spans boundaries, as shown in the following figure.
Figure 3-1 Aligned vs. Unaligned Data
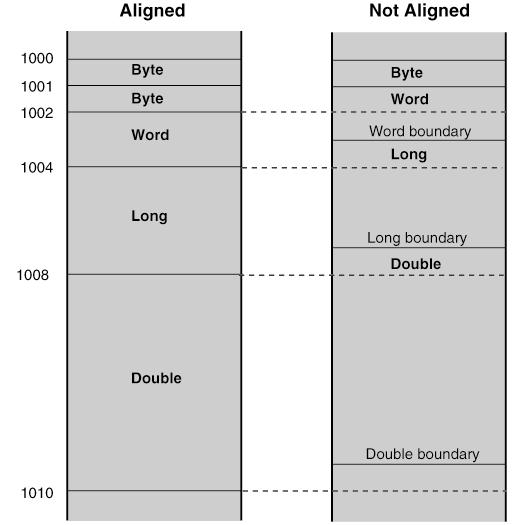
One place where alignment problems are common is in structure definitions. For example, the structure
struct {
LONG A,
BYTE B,
WORD C,
LONG D
} BadStruct;
is a poorly-designed structure because the placement of B in the structure causes C and D to cross long boundaries (they are not long-aligned). This is shown in the following figure.
Figure 3-2 Poorly Aligned Structure
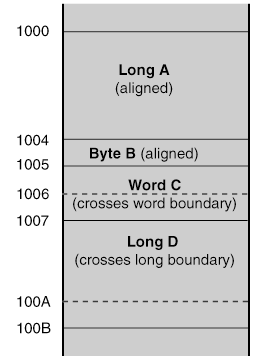
To solve the alignment problem (and to speed up the NLM), you can arrange the structure fields as follows:
struct {
LONG A,
LONG D,
WORD C,
BYTE B,
} GoodStruct;
As shown in the following figure, this is a well-designed structure because it does not have alignment problems. The fact that B is not on a long boundary is not an issue; BYTEs do not need to be long aligned because a byte can never cross a boundary as a WORD or a LONG can.
Figure 3-3 Well-Aligned Structure
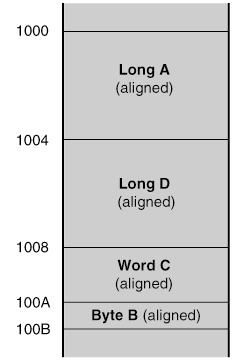
3.1.2 C Parameter Ordering
When C calls a function, it places the function parameters on the stack in the reverse order that they appear in the call. (The rightmost parameter is the first parameter that C pushes on the stack.) For example, when C issues the call
MyFunc(A, B, C);
it places the parameters on the stack in the order of C, B, and A, as shown in the following figure.
Figure 3-4 Parameter Ordering