1.2 Cluster Use Scenarios
During normal NCS operations, each server node is in constant communication with the other nodes. Slave nodes transmit repetitive signals, known heartbeat signals, to the master and the master sends similar messages to the slaves to let them know that it is still active. This continual communication between nodes enables node failure detection. The following example (Figure 1) depicts the events that would take place when a node failure is detected in a cluster of network servers that provide Web services.
Figure 1-1 Maintaining Constant Communication between Cluster Server Nodes
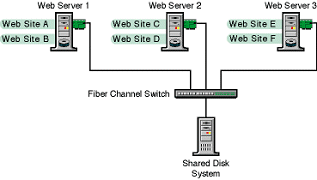
Web Servers 1, 2, and 3 provide their clients Internet access, e-mail, and other information through a number of Web sites hosted by these clustered nodes. Currently, the resources for Web Sites A and B are running on Web Server 1.
Whereas Web Server 1 is currently the preferred node for the cluster resources of Web Site A and Web Site B, these resources also have been configured to run on other nodes in the cluster in the event of a failure. As shown in Figure 2, when Web Server 1 fails, these resources are configured to migrate to the other nodes in the cluster.
Figure 1-2 Migrating to Other Server Nodes Within the Cluster
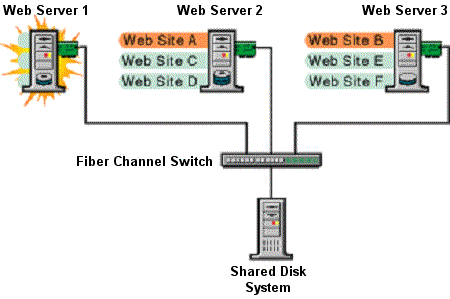
When the resource for Web Site A moves to Web Server 2, its IP address and Web Server doc root volume are re-instantiated (IP address bound and volume mounted) on that server. In this failover example, Web Site B’s IP address and doc root volume are also re-instantiated on Web Server 3.
With NCS, the failover process in this example happens quickly, enabling users to regain access to the Internet, Web site information, and e-mail within seconds. In most cases, users won’t even realize that they lost a connection to these resources because of NCS’ transparent reconnect capabilities.
In this same example, once the problems that caused Web Server 1 to fail are resolved, it can rejoin the cluster. In this instance, if the resources for Web site A and Web site B are configured to failback then these resources will automatically migrate back to Web Server 1. This failback allows Web Server operations to return back to their original state as they existed before Web Server 1 failed.
NetWare Cluster Services also provides manual resource migration capabilities. Network administrators can move applications, Web sites, and other cluster resources to other nodes in the cluster without waiting for a server to fail. This manual migration of resources facilitates scheduled maintenance or upgrades of individual nodes in the cluster.