6.16 Reload Integration
Micro Focus Reload and Micro Focus Retain perform very different functions. Retain is an archiving product whose main feature is the storage of data in one place for later search and retrieval. Reload is a Hot Backup, Quick Restore and Push-Button Disaster Recovery product whose main feature is the storage of instances of GroupWise post offices for the purposes of restoring items to their original location in their original form or providing disaster recovery of domains or post offices.
So, why would you want to integrate Reload and Retain?
-
Reload is very good at moving data efficiently from point A to point B.
-
It copies your post office data in its original form.
-
It can make what is effectively a full backup by moving and storing as little as 12% of the total amount of data in the post office.
-
By having the backed up data available in its original form, it can serve as a data source for Retain.
-
Reload’s backups are available the moment the backup job is complete.
-
-
Retain moves a lot of data and needs strong network links to do so rapidly.
-
An archiving job moving “everything” will move all of the data. This may seem self evident but when you combine Reload with Retain, you can achieve the same thing by moving only 12% of the data.
-
If you don’t integrate them, you will pull data twice over the link – once for Reload, and once for Retain. On top of that, if you don’t have Reload and you only have Retain, you will definitely have to move your data twice.
-
By integrating Reload and Retain, you can centralize your archives and ensure good backups and achieve a single data pull.
-
6.16.5 Retain Settings
The three tasks to configure Retain to work with reload are to assign the reload password for the worker, assign the running jobs to use the Reload integration, (this setting is found in the Jobs configuration page in the Retain management console), and configure the Profile to use the Item store flag for duplicate checking.
Enter the management console, and select Jobs from the Data Collection menu.
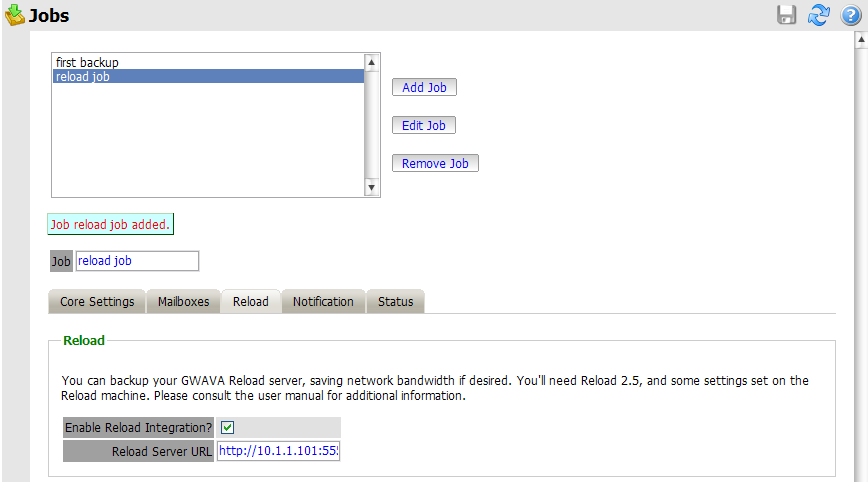
Create or select a job which you desire to use against the Reload system, and select the Reload Tab. You must select the Enable Reload Integration option, as well as supply the correct connection address for the Reload Server URL. (Both IP address and DNS name will work, but DNS is recommended wherever possible.)
Set the rest of the Core Settings, Notification, and Status as you would normally for your Retain system, but note that in the Mailboxes section you MUST assign the mailbox that Reload is backing-up.
Save the changes.
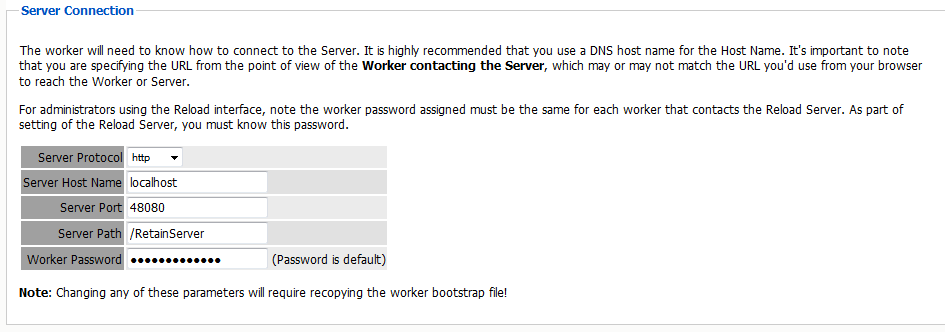
To specify the Reload –Retain password to the worker, open the specified worker in the worker settings page, and click on the Connection tab. Specify the new Worker Password by entering it into the provided field and then click ‘Save changes’ in the top corner of the page. You must re-upload the bootstrap file to the worker after creating a new password. (See the worker section to get instructions on correcting the bootstrap file.)