2.2 Apache Kafka
Apache Kafka is a distributed publish-subscribe messaging system that enables passing of messages from one system to another, while handling large volumes of data. Kafka can be enabled on a single Appliance Primary Server or can be run as a cluster on one or more Appliance servers that can span multiple data centers . Each server in the cluster is called a broker. Kafka is run as a cluster to ensure high availability of its services by replicating Kafka topics or messages to multiple Kafka brokers. Kafka requires ZooKeeper to co-ordinate between the servers within the Kafka cluster.
Apache Kafka is pre-packaged in the ZENworks 2020 virtual appliance build but will be in a disabled state. Using the ZMAN utility, you need to enable Kafka and it related services on an Appliance server. For more information on enabling Kafka, see Enabling Kafka.
In the Vertica data migration workflow, Apache Kafka is required to sync data with Vertica, after the bulk data migration process. When Vertica is enabled, the ZENworks server will continue to send data to the existing RDBMS. After bulk data migration, if any data is added or modified in the RDBMS, Kafka syncs these changes with Vertica at an interval of every 10 to 15 minutes.
For more information on Kafka, see Kafka Reference Guide.
2.2.1 Kafka Change Data Capture Workflow
The following diagram is a graphical representation of the Kafka workflow:
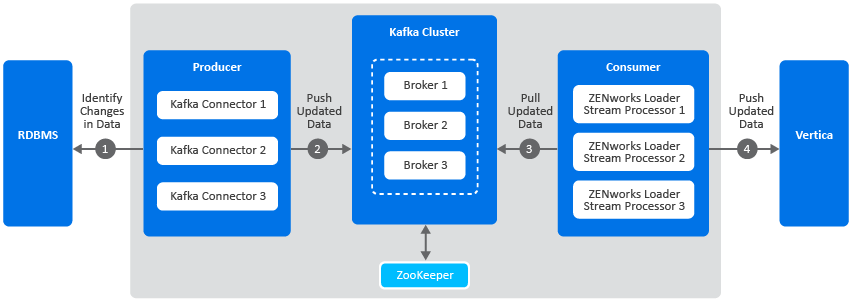
A description of each component in this architecture is as follows:
-
Kafka Cluster: A group of servers or nodes that are connected to each other to achieve a common objective is a cluster. Each of the servers or nodes in the cluster, will have one instance of Kafka broker running.
-
Kafka Broker: One or more servers that are added in a Kafka cluster are called brokers.
-
Apache ZooKeeper: Kafka uses ZooKeeper to manage and co-ordinate between brokers. It notifies Kafka Producers and Consumers of any broker failures.
-
Kafka Producers: The processes that publish messages to Kafka brokers. In this case, Kafka connectors are created as soon as Kafka is enabled. These connectors are created for each table in the RDBMS database and is responsible for identifying changes in these tables and publishing them to Kafka.
-
Kafka Consumers: A service that reads data from Kafka brokers. In this case, the ZENworks loader stream processors subscribes to data from Kafka and passes this information to the Vertica database.
The Kafka workflow is as follows:
-
The Kafka connectors (Kafka producer) identifies changes in the respective RDBMS database tables.
-
These changes are published to a topic within a Kafka broker. Kafka maintains messages as categories and these categories are called topics. To modify the interval at which the Kafka connector identifies changes in the RDBMS tables and publishes this data to Kafka, you can update the connector-configs.xml file (available at etc/opt/novell/zenworks) and run the zman srkccn command to re-configure the connectors. For more information on this command, see Maintaining Kafka Connect.
The topics are further broken down into partitions for speed and scalability. These partitions are replicated across multiple brokers, which is used for fault tolerance. The replicas are created based on the replication count specified while enabling the Kafka cluster. Each message within a partition is maintained in a sequential order, which is identified as an offset, also known as a position.
-
The ZENworks loader stream processors (consumers) subscribe to a topic, Kafka offers the current offset of the topic to the consumer and saves the offset in the ZooKeeper cluster.
-
The ZENworks loader stream processor receives the message and processes it to the Vertica database and the Kafka broker receives an acknowledgment of the processed message.
Kafka also uses a Schema Registry, which is a separate entity that producers and consumers talk to, for sending and retrieving schemas that describe the data models for the messages.
For more information on the Kafka Architecture, see the Confluent docs.