2.8 Clustering
This section includes the following topics:
2.8.1 Clustering an Application Server
A cluster is a collection of application server nodes that provide a set of services. The purpose of a cluster is to increase performance and reliability of applications. In general, a cluster provides three key benefits for enterprise applications:
-
High availability
-
Scalability (more capacity)
-
Load balancing
High availability means that an application is reliable and available for a high percentage of the time that it is deployed. Clusters provide high availability because the same application is running on all nodes. If one node fails, the application is still running on other nodes. The Identity Manager User Application benefits from higher availability when running in a cluster. In addition, the Identity Manager User Application supports HTTP session replication and session failover. This means that if a session is in process on a node and that node fails, the session can be resumed on another server in the cluster without intervention.
For more information about JBoss clusters, see the JBoss wiki page for High availability and clustering services.
JGroups Cluster Groups
The JGroups communications module provides communications among groups that share a common name, multicast address, and multicast port. JGroups is installed with JBoss, but it can also be used without JBoss. The User Application includes a JGroups module in the User Application WAR to support caching in a cluster environment.
JBoss Cluster
JBoss clusters are implemented by JBoss using the JGroups communications module. The configuration of JGroups and session replication is defined by JBoss and depends on the version of JBoss you are using. See the JBoss Administration Guide for more detailed information on configuring JBoss clusters.
User Application Cluster Group
The Identity Manager User Application uses an additional cluster group solely to coordinate User Application caches in a clustered environment on either JBoss or WebSphere clusters.
The User Application cluster group is independent of the two JBoss cluster groups and does not interact with them. By default, the User Application cluster group and the two JBoss groups use different group names, multicast addresses, and multicast ports, so no reconfiguration is necessary.
By default, this cluster group uses a UUID name to minimize the risk of conflicts with other cluster groups that users might add to their servers. The default name is c373e901aba5e8ee9966444553544200. By default, the group uses multicast address 228.8.8.8 and runs on port 45654. This cluster isn't configured using a JBoss service file. Instead, the configuration settings are located in the directory and can be configured using the User Application administration features. If you are familiar with JGroups and JBoss clustering, you can adjust the User Application cluster configuration using this interface. Changes to the cluster configuration only take effect for a server node when that node is restarted.
User Application cluster group settings are shared by any Identity Manager application that shares the directory configuration. The purpose of the local settings option in the User Application administration interface is to allow an administrator to remove a node from a cluster, or change the membership of servers in a cluster. For example, you can disable clustering globally, then enable it locally for a subset of your servers sharing the directory configuration.
2.8.2 Things to Do Before Installing the User Application
This section provides information that you should be aware of before you install the User Application, and describes tasks that you should perform before installing the User Application.
This section includes the following topics:
About Multiple Clusters on the Same Network
If you have more than one cluster running on a network, you must separate the clusters to prevent performance problems and anomalous behavior. You accomplish this by ensuring that each cluster uses a different partition name, multicast address, and multicast port. Even if you are not running multiple clusters on the same network, it’s a good idea to specify a unique partition name for the cluster, rather than using the default partition.
The following are important points:
-
The cluster must have a unique cluster partition name and multicast address.
For JBoss, specify the cluster partition name and multicast address by editing the JBoss startup script (start-jboss.bat or start-jboss.sh for Windows or Linux, respectively) supplied with the User Application. You need to modify the JBoss startup scripts for your servers to start JBoss with a -D flag and set the jboss.partition.name and jboss.partition.udpGroup system properties (see Configuring the Workflow Engine).
-
The cluster must use a unique multicast port.
For JBoss, specify the port to use by editing the mcast_port attribute in the JBoss server deploy\cluster-services.xml file.
For JBoss, you can find instructions about running more than one cluster on a network by using your browser to view Two Clusters Same Network.
Synchronizing Application Server Clocks
You must synchronize the clocks of the servers in a User Application cluster. If server clocks are not synchronized, sessions might time out early, causing HTTP session failover to not work properly. There are many time synchronization methods available. The method that you use depends on the needs of your organization. One common approach is to use the Network Time Protocol (NTP). For a discussion of using the xNTP protocol for time synchronization, see Time Synchronization using Extended Network Time Protocol (xntp).
Avoiding Multiple Browser Logins from the Same Browser Window in a Cluster
We do not recommend using multiple logins across browser tabs or browser sessions on the same host. Some browsers share cookies across tabs and processes, so using multiple logins might cause problems with HTTP session failover (in addition to risking unexpected authentication functionality if multiple users share a computer).
About the User Application Database
When you install the User Application using the User Application installation program, you designate an existing version of a supported database to use (for example, MySQL, Oracle or Microsoft SQL Server). The database is used to store User Application data and User Application configuration information.
When the User Application is installed in a cluster environment, all nodes in the JBoss cluster must access the same database instance. The User Application uses standard JDBC calls to access and update the database. The User Application uses a JDBC data source bound to the JNDI tree to open a connection to the database.
When you install the User Application into a JBoss cluster by using the User Application installation program, the data source is installed for you. The installation program creates a data source file named IDM-ds.xml, and places this file in the deploy directory (for example, server/IDM/deploy). The installation program also places the appropriate JDBC driver for the database specified during installation in the lib directory (for example, /server/IDM/lib). For more information about setting up the User Application database for a cluster, see Specifying the User Application Database.
NOTE:By default, MySQL sets the maximum number of connections to 100. This number might be too small to handle the workflow request load in a cluster. If the number is too small, you might see the following exception:
(java.sql.SQLException: Data source rejected establishment of connection, message from server: "Too many connections.")
To increase the maximum number of connections, set the max_connections variable in my.cnf to a number greater than 100.
2.8.3 Installing the User Application to a JBoss Cluster
To install the User Application to a cluster, use the User Application installation program to install the User Application to each node in the cluster (see the Roles Based Provisioning Module Installation Guide). This section provides notes that are specific to installing the User Application to a cluster.
This section includes the following topics:
About the Server Configuration
JBoss comes with three different ready-to-use server configurations: , and . Clustering is only enabled in the all configuration. A cluster-service.xml file in the /deploy folder describes the configuration for the default cluster partition. When you install the User Application and indicate to the installation program that you want to install into a cluster, the installation program makes a copy of the configuration, names the copy IDM (this is the default; the installation program allows you to change the name), and installs the User Application into the this configuration.
Specifying the User Application Database
All nodes in the JBoss cluster must access the same database instance. When you use the User Application installation program, you are prompted to specify the database name, host and port:
Figure 2-3 Specifying the Database Host and Port
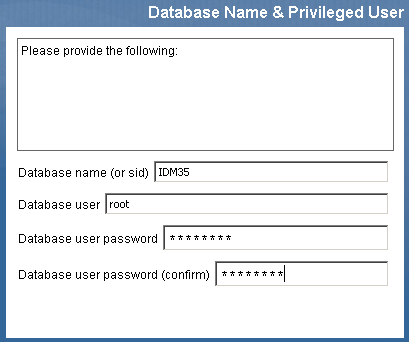
Make sure that you specify the same database parameters each time you install the User Application to a cluster node.
Selecting the Cluster (all) Option
When you use the User Application installation program, you are prompted to specify the IDM configuration:
Figure 2-4 Specifying the Cluster (all) Option and Engine ID

Select the option.
Configuring the Workflow Engine
Workflow engine clustering works independently of the User Application cache framework. There are several steps that you must perform to ensure that the workflow engine works correctly in a cluster environment.
-
All servers in the cluster need to be pointing to the same database.
When you install the User Application to the cluster using the User Application installation program (see Installing the User Application to a JBoss Cluster), you accomplish this by specifying the IP address or host name of the server on which the database for the User Application is installed.
-
Each server in the cluster needs to be started with a unique engine-id.
You can accomplish this by setting the com.novell.afw.wf.engine-id system property at server startup. For example, if you wanted to start JBoss and assign the engine id ENGINE1 to the workflow engine for that server, you would use the following command:
run.sh -Dcom.novell.afw.wf.engine-id=ENGINE1 (Linux)
run.bat -Dcom.novell.afw.wf.engine-id=ENGINE1 (Windows)
You might want to combine the setting of this system property with the setting of other system properties (see Setting JBoss system properties in the JBoss startup script).
For information about managing running workflows, see Managing Workflows in a Cluster.
Setting JBoss system properties in the JBoss startup script
Each server in the cluster should be started using the same partition name and partition UDP group (see About Multiple Clusters on the Same Network). Each server in the cluster should use a unique engine ID (see Configuring the Workflow Engine).
You can modify your JBoss startup script (start-jboss.bat for Windows, start-jboss.sh for Linux) to specify all of these system properties. This script is located in the directory in which your User Application files are stored. For example, to start a server using the partition name “Example_Partition”, the UDP group “228.3.2.1” and the Engine ID “Engine1” you would add the following to the start-jboss script:
start run.bat -c IDM -Djboss.partition.name=Example_Partition -Djboss.partition.udpGroup=228.3.2.1 -Dcom.novell.afw.wf.engine-id=Engine1
Using the Same Master Key for Each User Application in the Cluster
The Identity Manager User Application encrypts sensitive data (see Section 2.2.7, Encryption of Sensitive User Application Data). A master key is used to access encrypted data. All User Applications in a cluster must use the same master key. Follow these steps to ensure that all User Applications in a cluster use the same master key.
-
Using the User Application installation program, install the User Application to the first node in the cluster.
For information about using the User Application installation program, see “Installing the User Application in the Roles Based Provisioning Module Installation Guide.
When you use the User Application installation program to install the first User Application in a cluster, at the end of the installation you are presented with a new master key for the User Application:
Figure 2-5 Master Key
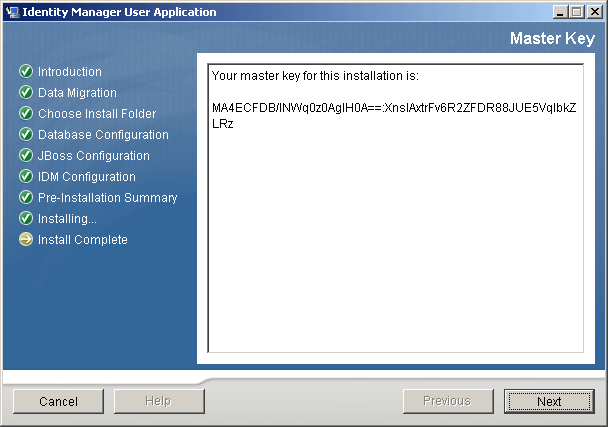
Follow the on-screen instructions to save the master key to a text file.
-
Using the User Application installation program, install the User Application to the other nodes in the cluster.
When you install the User Application to the other nodes in the cluster, the installation program provides a page that you use to import the master key:
Figure 2-6 Pasting Master Key in User Application Installation Program
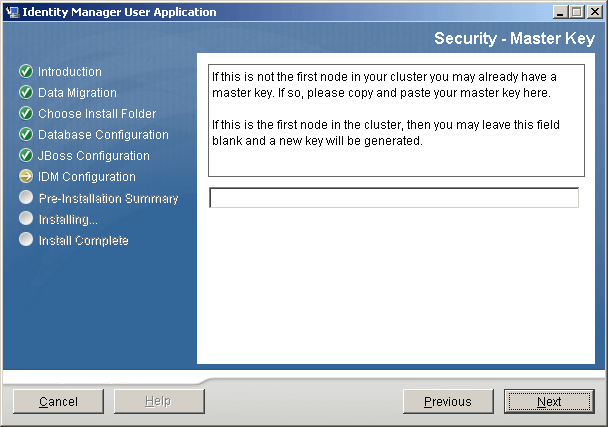
-
Import the master key that you saved to a text file in Step 1.
Starting the User Application Cluster Group
After the User Applications in your cluster have been installed, you must enable the cluster in the User Application cluster configuration.
-
Start the first User Application in the cluster.
-
Log in as the User Application administrator.
Don’t start any other servers yet.
-
Click .
The User Application displays the Application Configuration portal.
-
Click .
The page is displayed.
-
Select for the property.
-
Click .
-
Restart the server.
-
If you are using local settings (see Specifying the User Application Cluster Group Caching Configuration), repeat this procedure for each server in the cluster.
2.8.4 Installing the User Application to a WebSphere Cluster
This section outlines the process for installing and starting the User Application on a WebSphere cluster. This section assumes you are an experienced user of the WebSphere Application Server.
-
Install and configure your WebSphere Application Servers and cluster according to manufacturer’s instructions, such as those at the following links:
For information about application server setup, refer to:
-
Install and create a database according to manufacturer’s instructions. Enable the database for UTF-8.
-
Add and configure the database driver on a WebSphere server.
-
Create a JDBC Provider.
-
Create a data source for your relational database.
-
Run the User Application installer to install and configure the User Application on your WAS console system. Directions are in the Roles Based Provisioning Module Installation Guide.
The installer writes the sys-configuration-xmldata.xml file to the directory you choose during installation.
-
In your post-installation tasks, while creating JVM Custom Properties in the WAS console as directed in the Roles Based Provisioning Module Installation Guide, create a new JVM Custom Property for each User Application server in the cluster. Name the Custom Property com.novell.afw.wf.engine-id and give it a unique value. Each User Application server runs a workflow engine, and each engine requires a unique engine ID.
-
Import the directory server certificate authority to the WebSphere keystore.
-
Deploy the IDM WAR file from the WebSphere administration console.
-
Start the application. Access the User Application portal using the context you specified during deployment. The default port for the web container on WebSphere is 9080, or 9443 for the secure port. The URL would look something like this:
http://<server>:9080/IDMProv
2.8.5 Things to Do After Installing the User Application
This section describes User Application cluster configuration actions that you perform after installing the User Application.
This section includes the following topics:
Configuring the User Application Driver for Clustering
Clustering is the only scenario in which the same User Application driver is used by multiple User Applications. The User Application driver stores various kinds of information (such as workflow configuration and cluster information) that is application-specific. Therefore, a single instance of the User Application driver should be not shared among multiple applications.
The User Application stores application-specific data to control and configure the application environment. This includes JBoss application server cluster information and the workflow engine configuration. The only User Applications that should share a single User Application driver instance are those applications that are part of the same JBoss cluster.
In a cluster, the User Application driver must be configured to use the host name or IP address of the dispatcher or load balancer for the cluster. You create the User Application driver when you install the User Application (see the Roles Based Provisioning Module Installation Guide). You configure the User Application driver using iManager.
-
Log into the instance of iManager that manages your Identity Vault.
-
Click the node in the iManager navigation frame.
-
Click .
-
Use the search page to display the Identity Manager Overview for the driver set that contains your User Application driver.
-
Click the round status indicator in the upper right corner of the driver icon:

A menu is displayed that lists commands for starting and stopping the driver, and editing driver properties.
-
Click .
-
In the section, change the parameter to the host name or IP address of the dispatcher.
-
Click .
Specifying the User Application Cluster Group Caching Configuration
Users who are familiar with JGroups and JBoss clustering can modify the cluster group caching configuration, using the User Application administration user interface (see Cache Settings for Clusters). Changes to the cluster configuration only take effect for a server node when the server node is restarted.
In most cases you should use global settings when configuring a cluster. However, global settings present a problem if you need to use TCP, because the IP address of the server must be specified in the JGroups initialization string for each server. You can use local settings to specify a JGroups initialization string by checking for , then typing the JGroups initialization string in the field. For an example of a working JGroups TCP protocol stack, see JGroupsStackTCP.
WARNING:If you specify local settings and enter an incorrect configuration in the JGroups initialization string, the cache cluster function might not start. Unless you know how to configure JGroups correctly and understand the protocol stack, you should not use local settings.
Alternatively, you can add a token (for example, “IDM_HOST_ADDR”) to the global settings for the . You can then edit the hosts file on each server in the cluster to specify the IP address for that server.
Configuring Logging in a Cluster
This section includes tips for configuring logging in a cluster. No tips are included for WebSphere or WebLogic.
JBoss Logging
You can configure JBoss for logging in a cluster. To enable logging for clusters, you need to edit the jboss-log4j.xml configuration file, located in the \conf directory for the JBoss server configuration (for example, \server\IDM\conf), and uncomment the section at the bottom that looks like this:
<!-- Clustering logging
-->
- <!--
Uncomment the following to redirect the org.jgroups and
org.jboss.ha categories to a cluster.log file.
<appender name="CLUSTER" class="org.jboss.logging.appender.RollingFileAppender">
<errorHandler class="org.jboss.logging.util.OnlyOnceErrorHandler"/>
<param name="File" value="${jboss.server.home.dir}/log cluster.log"/>
<param name="Append" value="false"/>
<param name="MaxFileSize" value="500KB"/>
<param name="MaxBackupIndex" value="1"/>
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%d %-5p [%c] %m%n"/>
</layout>
</appender>
<category name="org.jgroups">
<priority value="DEBUG" />
<appender-ref ref="CLUSTER"/>
</category>
<category name="org.jboss.ha">
<priority value="DEBUG" />
<appender-ref ref="CLUSTER"/>
</category>
-->
You can find the cluster.log file in the log directory for the JBoss server configuration (for example, \server\IDM\log).
User Application Logging
The User Application logging configuration (see Section 5.1.4, Logging Configuration) is not propagated to all servers in cluster. For example, if you use the Logging administration page on a server in a cluster to set the logging level for com.novell.afw.portal.aggregation to Trace, this setting is not propagated to the other servers in the cluster. You must individually configure the level of logging messages for each server in the cluster.
Managing Workflows in a Cluster
The Identity Manager User Application workflow cluster implementation binds process instances to the engine on which they started. This is done by associating a workflow process instance with an engine-id and is maintained in the cluster database. When a workflow engine is started, it resumes process instances that are assigned to its engine-id. This prevents multiple engines in a cluster from resuming the same process instance. If a workflow engine fails, processes that were running on that engine are automatically resumed on another engine in the cluster.
You can manually reassign processes to other engines in the cluster. For example, an administrator could reassign processes back to a failed workflow engine when the workflow engine is brought back online, or redistribute processes to other engines when an engine is permanently removed from the cluster (see Section 17.2.7, Managing Workflow Processes in a Cluster).
When the workflow engine starts up it checks to see if its engine ID is already in use by another node in the cluster. When this is the case, the workflow engine checks the cluster database to see if the status of the engine is SHUTDOWN or TIMEDOUT. If it is, the workflow engine starts. If the status is STARTING or RUNNING, the workflow engine logs a warning, then waits for a heartbeat time out to occur. If the heartbeat time out occurs, that means that the other workflow engine with the same ID was not shut down properly, so it's safe to start. If the heartbeat timer is updated, that means another workflow engine with the same ID is running in the cluster, so the workflow engine cannot start. You can specify the heartbeat time out (the maximum elapsed time between heartbeats before a workflow engine is considered timed out) by setting the and properties in the User Application (see Configuring the Workflow Cluster).
Checking the Health of the Server
Most loadbalancers or dispatchers provide a healthcheck feature for determining whether an HTTP server is up and listening. The User Application contains a blank page that can be used for configuring HTTP healthchecks on your loadbalancer. The page can be addressed at this URL:
http://<HOSTNAME>/<CONTEXT>/jsps/healthcheck.jsp