Process Manager User's Guide
CHAPTER 2
This chapter attempts to make the abstract concepts of Chapter 1 more concrete by, first of all, examining runtime flow mechanics (as implemented by the Integration Manager Process Server), then by showing how various use cases and design patterns can be implemented in Process Designer.
An understanding of the Process Server's basic execution algorithm in fundamental to understanding how to design a process.
The Process Server (or runtime engine) executes a process instance in the following manner.
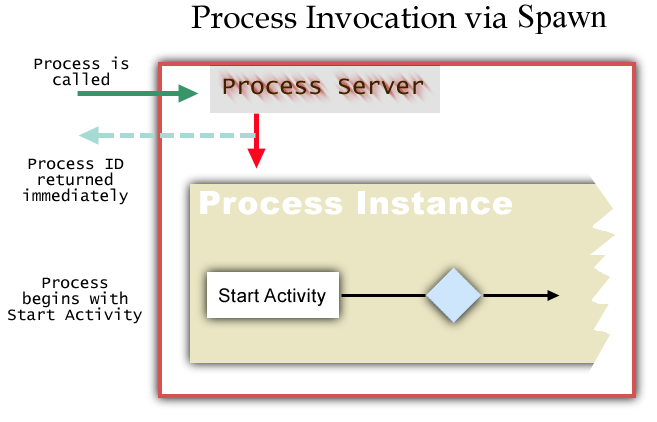
If the process was called asynchronously via a Spawn event, the Process server—upon instantiating a new process—returns a ProcessID (a "return receipt") to the caller immediately. Otherwise, if the process was invoked with a Call, it is assumed that the caller will block until the process finishes.
The Process Server determines which of the process model's activities constitute start activities.
The input data to the process (one or more message parts) are mapped to the start activities.
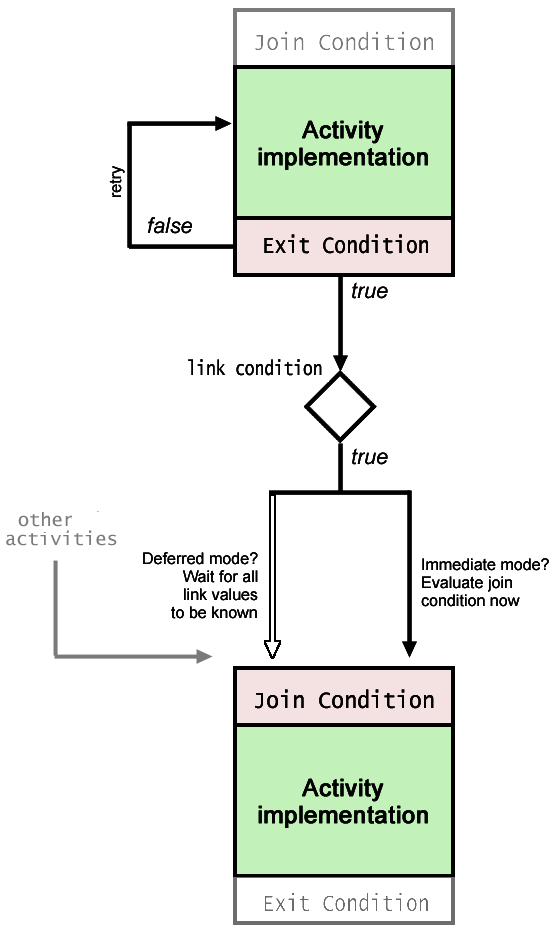
Whenever any activity (whether it is a start activity or not) finishes, the Process Server consults the exit condition of the activity and evaluates the associated XPath expression. If the exit condition evaluates to false, the activity is executed again (with the same input as before). Execution repeats until a timeout occurs, or the exit condition is true, whichever occurs first. See diagram below.
If the exit condition of a completed activity is true, the Process Server determines which control links (if any) are connected to the outbound side of the activity, and the transition conditions of those control links are evaluated.
For each control link whose transition condition was true, the Process Server evaluates the join condition of the link target. This evaluation takes place once, after all link conditions have been evaluated, if the join is in Deferred Mode (the default). If the join mode is Immediate, the join condition is evaluated multiple times: once each time a link's truth value has been computed. (In others words, as soon as a link condition has been evaluated—if even if the value is false—the engine will evaluate the join condition.)
If the join condition evaluates to true, the target activity fires; otherwise it does not.
NOTE: Regardless of synchronization mode (Immediate/Deferred), the target of a join will not fire until and unless the join condition is, at some point, true.
When the target activity of any link has finished executing, the cycle begins again at Step 5 above. Execution continues until there is nothing to do (i.e., the truth values of all end-activity exit conditions are known).
The following graphic shows typical process-startup mechanics for a process instance that has been invoked via spawn. (That is, the caller has elected to invoke the process in a "fire and forget" manner.)

The runtime engine needs to know which activities a given process model will use, how they are linked together, what the data mappings are between them, etc. All of this information must be specified at design time in a process graph. You will use the Process Design to do this.
The Process Designer is a visual editing environment for creating graphical representations of processes, and for specifying data relationships between activities in a process. The tools that allow you to do this involve a combination of point-and-click layout tools plus text-based property sheets, which operate like non-modal dialogs. In addition to these GUI features (which are unique to the Process Designer), you have Integration Manager's standard menu commands, navigator frame, multi-document content frame, and output frame, just as you'd use when creating Integration Manager components and services. In other words, the Process Designer runs entirely within Integration Manager.
The Process Designer view of a simple two-activity process looks like:
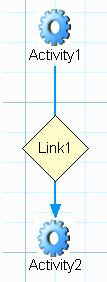
The activity icons, in this case, represent Integration Manager Components. A link connects the two activities. The fact that the link icon is diamond-shaped means a custom transition condition has been specified for the link. (Links without custom conditions have no diamond icon and just show the word "Link".)
We say that Activity1, in this diagram, is the Source Activity, whereas Activity2 is the Target Activity.
Just looking at this graph, it's not apparent whether Activity1 has a custom exit condition; whether a retry protocol applies to either activity; whether a mapping policy (such as Last Writer Wins) applies on the input to Activity2; and so on—to say nothing of how message parts are actually mapped from one activity to the other. The graph depicts control-flow relationships in a clear, direct, intuitive fashion, yet seems to hide data-related information.
Data-link information is available via a non-modal (and dockable) Object Properties palette containing tabs for component-, message-, and UI-based information, as shown below.
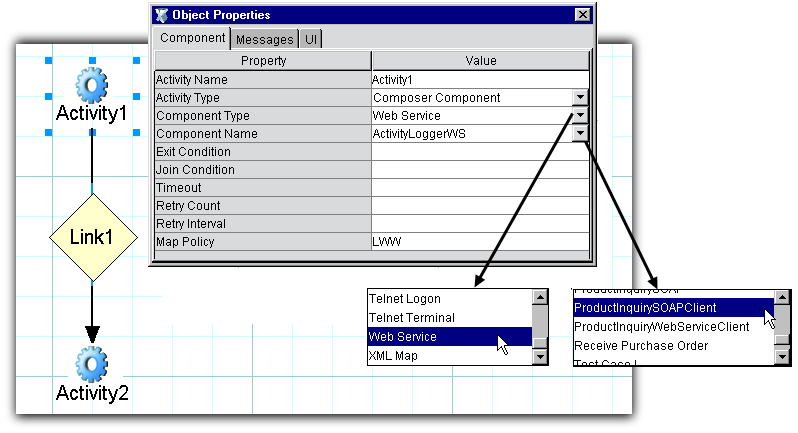
Notice that in this graph, Activity1 has focus (as indicated by the handles around its periphery), and therefore the Object Properties panel (or "property sheet") displays information appropriate to Activity1. If one were to give Activity2 focus (by clicking on it with the mouse), the Object Properties panel would update to show information specific to that activity. Likewise, clicking on Link1 would cause the panel to show information specific to the link. These panel updates happen in real time, automatically, so that information is available for any graph element at any time. The information is not simply read-only, however. The fields in the Object Properties panel are where you specify data-related and activity-level attribute values.
In the Component tab (shown here), you can view activity-level information: the activity name and type, the type of Component (in this case, a Web Service), the Component's name, its Exit and Join conditions (if any), retry information, and map policy. Some of these values can be set using dropdown menus already populated with correct choices, as shown above. Others are text fields where you can type values directly into the panel.
By clicking on the Messages tab, you can view data-related information for the activity that has focus.
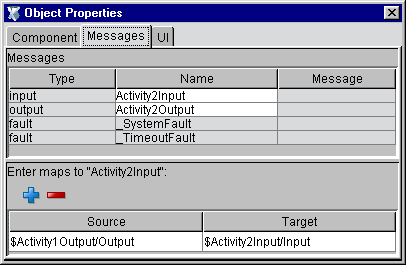
The top part of this panel shows the process-specific name for the activity's input and output messages as well as the concrete Type and Message descriptions given in the WSDL for the service (i.e., the activity's implementation). In other words, the Type and Message fields are automatically filled out with values taken from the WSDL portType segment.
The lower part of the panel is where you can specify exactly which Source message parts map to which Target message parts (using XPath). The above graphic applies to Activity2 in the previous flow graph and shows how input to Activity2 will be composed. The Source XPath, in this case, specifies that the Output message part from Activity1 will be mapped directly to Activity2's Input part. This means that when Activity2 fires, it will use as its input the Activity1 output. Obviously, this is a simple case. There could potentially be many intricate XPath mappings from Activity1's output message parts to Activity2's input parts.
The Object Properties panel will be discussed in greater detail later. For now, it's enough that you know that the Object Properties panel is where you can specify:
Activity type (Web Service Send, Web Service Receive, Integration Manager Component, Subprocess, or Synchronize Subprocesses)
Map policy (or overwrite policy) for situations where data from multiple incoming sources map to the same target message part(s)
XPath-to-XPath mappings of data from source message parts to target message parts
Because the WSFL model attempts to "granulate" flow logic at the level of links and joins (rather than aggregating flow decision-making into higher-level constructs like "XOR-split"), it's not always obvious how one can specify conditional branches and other common control-flow patterns using a WSFL-based approach (as followed by Integration Manager Process Manager). Nevertheless, it is possible to model virtually any kind of flow logic you can imagine using the Integration Manager Process Designer.
This section looks at some of the more common flow idioms and how they can be implemented with the Process Designer.
Many workflow experts are accustomed to thinking in terms of branch logic as well as join logic. We will consider branching patterns in this section and join patterns in the next.
WSFL has no built-in notion of conditional branching per se, which means activities cannot, on their own, decide which link(s) to use when there is more than one link on the outbound side of an activity. Instead, the decision of which link to follow is determined by the links themselves. But no individual link can "know" what the transition conditions of other, parallel links might be. A link can only decide whether its path should be followed, based on the output of the previous activity.
Nevertheless, this flow-constraint mechanism is sufficient to model a conditional branch. For example:
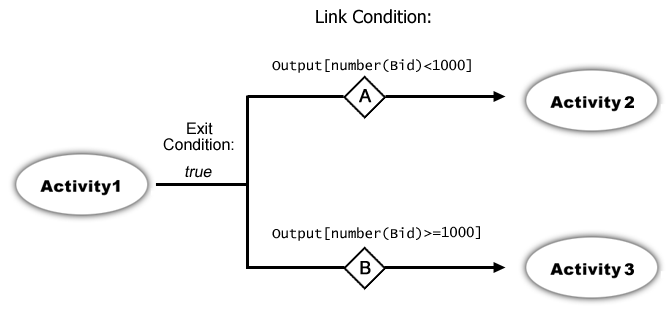
In this scenario, Activity1 produces output containing bid information from a company. The link condition at A says that link A will be followed if /Bid is less than 1000. The condition at B says that link B will be followed if /Bid is greater than or equal to 1000. Clearly, if one link is followed, the other one will not be; so this represents an exclusive-OR split (or XOR split)—a conditional branch.
The AND-split case (where every outgoing link is always followed) represents default behavior in Process Manager models.
An AND split, as defined here, is the case where every outgoing link will fire its target activity. This just means that every link has a value of true.
There may be cases where an activity with multiple outgoing links could (depending on the output data) fire any number of target activities. For example, "Fire Activity 1 if such-and-so is true; also Fire Activity 2 if this-and-such is true; also Fire Activity 3 if so-and-so is true." The number of activities that might actually fire at runtime could be zero, one, two, or three.
Again, this case is easily handled by distributed link logic. Every link can "look at" the source activity's output and apply suitable XPath logic in order to arrive at a decision of whether to fire/not fire. In the end, the appropriate number of target activities fire.
It's possible to combine the above patterns to handle complex cases such as "Traverse links A, B, and C always, but traverse D conditionally and traverse E only if D wasn't followed." To implement the case just stated, you would:
Set a condition on D (using suitable XPath) of "if this node value is exactly such-and-such, fire the target activity."
Set a condition on E of "if [the same node that was tested in D] isn't exactly such-and-such, fire the target."
In pseudocode, the net result (in terms of the links that will fire their target activities) is:
(A AND B AND C) AND (D OR E)
Other complex cases are possible as well. But before getting involved too deeply in compound branching strategies, it's important to step back and understand why such complex constructions are best avoided altogether.
In programming, complexity is a sign that a procedure or a block of code needs to be factored into smaller logical units. In Java code, conditionals involving many ANDs and ORs chained together are rare, because usually the desired actions can be carried out in a single switch/case block or a series of if/elses with simple conditions. If data dependencies are too complex to allow this, the dependencies themselves need to be broken out in such a way that the logic can be made simple. Data entanglements shouldn't be allowed to dictate tangled logic.
U.S. income-tax law provides many good examples of tangled logic involving complex data dependencies. The Internal Revenue Service must nevertheless produce tax forms that mere human beings can fill out correctly every year. They do this by, first of all, factoring out major dependencies into subject groupings, each with its own dedicated form (or "Schedule"). Within each form, there are major subdivisions (parts) that group calculations. The major parts are broken down, finally, into simple if/else statements. Some of the if/else statements point to other Schedules that must be completed before the if/else can be evaluated. (Each of those Schedules is a series of if/else statements grouped into parts.) Obviously, each tax form could, in theory, present all of its if/else logic in a single compound expression at the top of the form. But such a single-statement procedure wouldn't be human-readable.
Complex branch requirements should be a signal to you that the model you're creating needs to be factored into simpler logical units.
Link logic determines whether a target activity can be fired; not whether it actually will fire. The final decision as to whether an activity fires rests with the join condition.
In Deferred Mode (the default), no join condition can be evaluated—and therefore no join activity can be fired—until the truth value of every one of the activity's incoming links is known. When all link values are known, the join condition is evaluated. Only if the join condition is true can the target activity then fire.
In Immediate Mode, the join condition is evaluated every time a link's truth value is determined by the runtime engine. So if there are four inbound links to a target activity, it is possible that the activity's join condition will be evaluated four separate times. As soon as it is clear that the join condition is true (and can't change), the target activity is invoked.
NOTE: As explained in the previous chapter, join logic is the only logic touchpoint in the process model where XPath is not used. Links and exit conditions have access to upstream data and base their decision-making on XPath evaluations. The join condition knows only the truth values of incoming links; it does not use XPath and is not data-driven.
A join condition tends to look something like:
(Link1 OR Link2)
This is a simple non-exclusive OR condition. It means the join is true if one link or both links are true.
An exclusive-OR condition (i.e., the condition is true if one and only one link is true) would look like:
(Link1 AND NOT Link2) OR (NOT Link1 AND Link2)
In this case, either link could fire the activity, but if both links were true the activity would not fire. For this condition to work as intended, the join mode would have to be Deferred.
You can think of join conditions as a mechanism for deciding how many (and which precise combinations of) link values it takes to fire a target activity. This is important, because links have no way of knowing whether other (sibling) links exist, or which siblings evaluated to true. This knowledge exists only at the join.
On occasion, you may find that you want to iterate on a given activity until a certain condition is met. For example, you may have some kind of batch operation to do. Your normal inclination might be to draw a link from a target back to one of its sources. But this kind of control flow (reentrant flow) is not allowed in WSFL, nor in the Process Designer. If you attempt to create a cyclic graph, you will see the following alert:

Iteration of an activity must be done by the implementation of the activity (or by the implementation of the calling activity) rather than at the process-logic level.
The reason looping is not allowed in a process model is that it opens the door to any number of ill-defined situations that would be difficult to manage. For example, consider the control-flow graph shown below, which has a loop-link from D back to B. The runtime engine must make some difficult decisions:
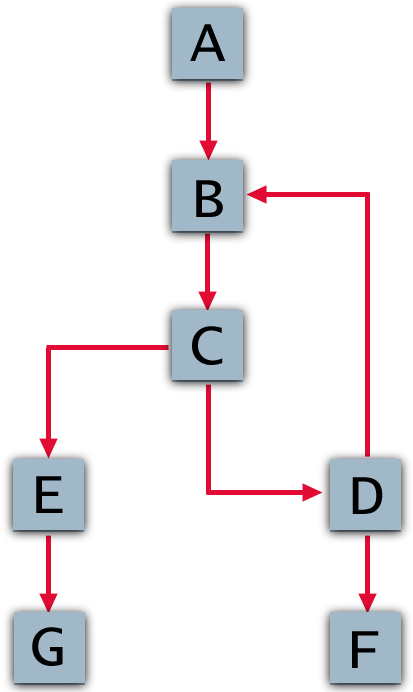
B is a join node with input from two activities: A and D. In Deferred Mode, B must wait for both incoming links to have truth values before its join condition can evaluate. But since D requires the prior execution of B and C, it can't execute unless D executes. The model hangs while B waits for D to execute. The join at B would only work in Immediate mode.
C will execute multiple times as part of the B-C-D loop. Each time it executes, the link from C to E is followed (in addition to the C-to-D link) and E will fire repeatedly if its link evaluates to true. Therefore E can unintentionally become part of the loop. To avoid this, the link logic for E's input link would have to "know" about the iteration status of the loop.
If E is executed multiple times, it might trigger G multiple times; therefore, G also has to know about the loop. (And so on, for all activities downstream of E.)
If the loop makes it back to C while before E returns from its first invocation, should a new instance of E be spawned?
When D executes each time through the loop, should it fire F on every cycle?
Even if these issues were resolved, the prospect of testing (then debugging) a model of the above sort could be daunting.
A number of looping paradigms are possible in Process Manager. Some rely on WSFL's inherent retry-on-false-exit-condition mechanism; others delegate looping to activity implementations; and there is a special Process Manager activity to help with asynchronous fan-outs.
While Process Manager does not permit control links to be used for looping, it does allow you to designate an activity's output as the data source to use for input in the event of a retry. This affords a type of looping, since standard WSFL and Process Manager behavior is to try an activity whenever the activity's exit condition is false. By mapping output back to input, the activity can loop on its own output as needed, until an exit condition of true is reached, at which point the looping stops and control proceeds down outgoing links. Diagrammatically, the scenario can be represented this way:
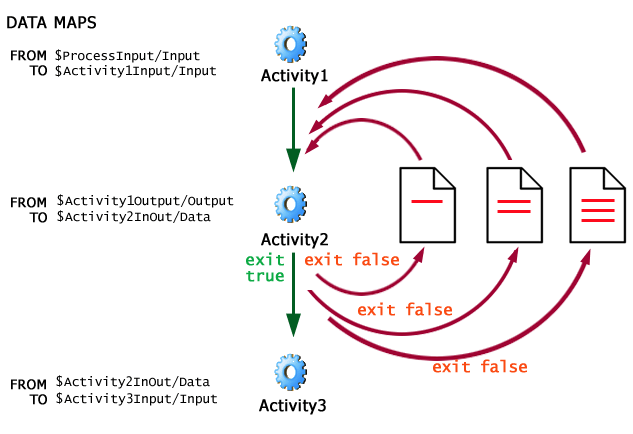
Activity2 has an input message named Activity2InOut and an output message of the same name. If Activity2 exits with an exit condition of false, it reexecutes using Activity2InOut. But Activity2InOut's data was modified on the initial execution of the activity as part of a loop. (Perhaps new info from a database lookup was appended to the Data doc.) In any case, the exit condition on Activity2 might be an XPath expression that inspects a flag value in the output DOM. The flag value would signal the need either to iterate again or break out of the loop.
To implement this kind of mapping requires that you give the loop activity's output and input messages the same name, as shown here:
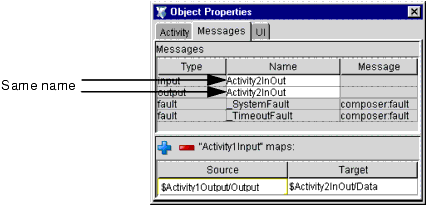
On the first invocation of Activity2, Activity2InOut gets populated with data from Activity1Output/Output. When Activity2 reexecutes due to a false exit condition, Activity2InOut (already populated with data) simply gets fed back in to the activity.
NOTE: When setting up this kind of mapping, do not forget to apply an exit condition (one that will successfully terminate the loop) to the loop activity. Otherwise, an infinite loop can result.
The type of looping described above is useful when an output document containing loop results needs to be built incrementally, with new data added to output on each trip through the loop. But there are also times when work items merely need to be pulled off a queue and processed one at a time (one work item per trip through the loop), with no consolidation, per se, of data for a final output doc.
Imagine that a process has a start activity that produces, as output, a batch of work items. Each item needs to be processed individually by a given application designed for the purpose. This means the processing application must be invoked multiple times (once per work item). A possible process model is shown below.
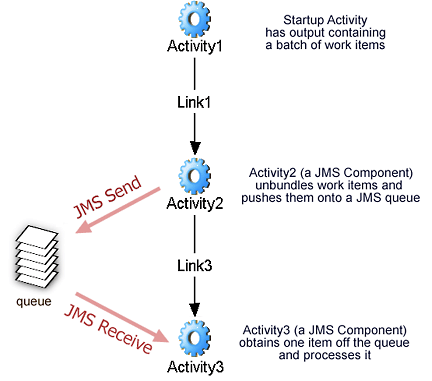
In this scenario, Activities 2 and 3 are Integration Manager JMS Components, but they could also be JDBC Components using a database instead of a queue; the concept can be adapted to other external stores as well. The idea is that Activity2 receives a batch of data (packaged as a WSDL message) as input. Activity2 unbundles (and possibly performs some kind of preprocessing on) the input. It also pushes every work item onto a message queue. Activity3 will inspect that queue.
In this example, the output from Activity2 contains a JMSDestination (in an element inside a message part) representing the location of the queue that Activity3 should operate against. No "work-item count" need be passed to Activity3. (Activity3 has been designed simply to fetch and process one work item.)
Activity3 does the following:
It executes exactly one JMS Receive action. The action either succeeds in pulling a waiting message off the queue or finds that the queue is empty.
If a message is successfully pulled off the queue, its data is processed and the activity exits with an exit condition of false, so that it executes again.
If no message was available (i.e., the JMSMessageID came back empty), the activity exits with condition of true.
The exit condition for Activity3 is based on whether the JMS Receive succeeded. If a message was processed, the exit is false so that Activity3 executes again. If no message was processed (i.e., the activity had nothing to do, because the queue was empty), the condition is true and Activity3 passes control to the next activity in the process flow.
This pattern does not involve a cyclic graph and does not violate WSFL's restriction against backward links, because there is no control link that "points the wrong way"—no reentrancy. Repeated execution of Activity3 occurs because its exit condition is false until a certain criterion is met. The arrows labelled "JMS Send" and "JMS Receive" represent data flow outside the process model. The data do not enter into any message maps.
An alternative to the foregoing strategy is to hide loop behavior within an activity's implementation. For example, you could create a Integration Manager service that uses Execute Component and Repeat While actions to call a given component repeatedly in a while loop. This strategy does not require the Process Server to manage any aspect of loop iteration.
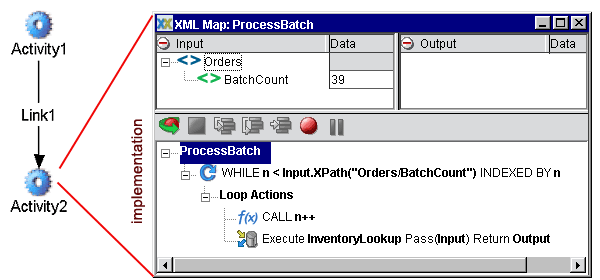
The flow graph is the same as before except that the Integration Manager Component called InventoryLookup is called not by the process engine but by the action model of Activity2, as shown above.
Rather than processing work items one at a time, you might find it advantageous to process them in parallel. Concurrent processing often results in significant performance gains.
The spawning of multiple concurrent processes is called a fan-out. The design pattern looks like this:

The Fan-Out Activity, on receiving a batch of work, unbundles the work items and spawns multiple instances of the appropriate target subprocess: one instance per work item. The subprocess might be called something like "DetermineQuantityOnHand" and the batch might be a collection of SKU numbers. One instance of DetermineQuantityOnHand is created for each SKU number.
Every subprocess instance is invoked via the WSFL-defined spawn mechanism, which means each instance runs in its own thread: i.e., parallel instances execute concurrently and finish whenever they happen to finish.
For this scenario to work, there has to be a "Fan-In" activity that collects output from every subprocess instance and waits until all instances are finished before passing control to the next activity in the process graph. The activity that does this is shown as the Consolidator activity in the above diagram.
As each subprocess instance finishes, it hands data to the merge component, which collects that data and merges it (typically) into one final document. When all subprocess instances have been accounted for, the merge component's exit condition becomes true and control passes to the next point in the graph.
There are two problems with implementing this pattern in a flow graph. The first is that WSFL provides no native mechanism for creating arbitrary numbers of outbound links at runtime. The second is that, even supposing that links could be created in quantities known only at runtime, there is no native provision for specifying the kind of late-binding join logic that would be needed to handle the synchronization.
Fortunately, these problems can be overcome.
One strategy is to hide the fan-out in a component's implementation. Imagine that a component's action model contains a Repeat While loop that iterates over a batch, calling a Process Execute action on each work item. By specifying an execution method of "spawn" in the Process Execute action, every process is launched in its own thread, in fire-and-forget manner. The workhorse process instances (the "fanee processes") can be designed in such a way that they post their results to a database, JMS message queue, or other external store. Synchronization would be handled by a second component (a "consolidator"). The "sync component" could follow either a listener metaphor or a periodic-polling metaphor. If the latter pattern is used, polling could take place in a continuous loop, or (less CPU-intensively) on a timed basis, where the component sleeps between data queries. The listener metaphor, on the other hand, can readily be implemented using a JMS Service.
Fan-outs can be modelled in WSFL using a recursive graph. That is, a fan-out can be modelled as a process that calls itself until a suitable number of "fanee" activities has been invoked (at which point the results are accumulated via joins). Diagrammatically, a recursive fan-out process might look like this:
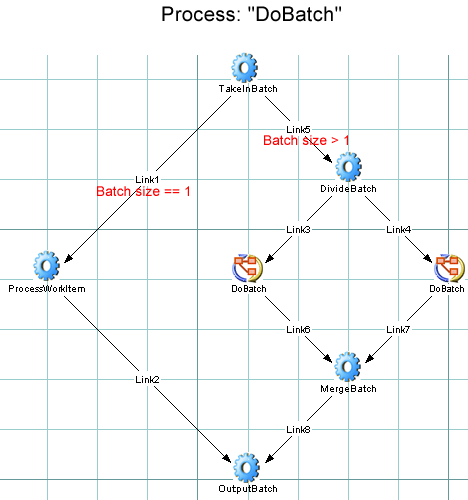
The algorithm can be summarized as:
Take in a batch of work. If the "batch" contains more than one work item, split it into two smaller batches (that is, traverse Link5 shown above) and fire new instances of ourselves using the smaller batches as input. (That is, traverse Link3 and Link4 and fire two new instances of DoBatch.) This recursive invocation of new instances of DoBatch continues until incoming batches are no longer splittable.
If an incoming batch contains exactly one work item, traverse Link1. The target of Link1 is the component (ProcessWorkItem) that actually processes the work item.
The output of the ProcessWorkItem activity is handed to OutputBatch, which does any required post-processing and returns.
When a recursively called DoBatch instance returns, it traverses its outgoing link (Link6 or Link7, whichever applies). A deferred join then occurs at MergeBatch.
The MergeBatch component accumulates data arriving from Link6 and Link7 into one output message, which is sent to OutputBatch. The return/merge/return/merge cycle continues until every processed work item has been accumulated into one consolidated message (document).
Finally, the topmost instance of DoBatch returns the consolidated document.
Note that the link logic at the top of the graph effectively makes the split coming out of TakeInBatch an exclusive-OR split. (This also has the effect of making Link2 and Link8 mutually exclusive.) The algorithm is basically one of "split or work." The ProcessWorkItem activity is not hit until the batch has been split into individual work items (at which point a corresponding number of instances of ProcessWorkItem fire up). The output docs are merged two-by-two, then four-by-four, etc., until the final output of the process is one consolidated document.
This is an example of a well-factored design that uses simple, discrete operations to accomplish a dynamically sized task. The flow can be diagrammed explicitly using ordinary WSFL constructs and hides nothing (other than business logic) in activity-level implementations. All data travels through ordinary data links (no special "off the graph" communication through external stores); all processing is concurrent; and all joins are synchronous.
One of the native Activity types in Integration ManagerProcess Manager is a specialized activity called Synchronize Subprocesses. This activity exists in order to provide "fan-in" capability (synchronization and consolidation of returns from asynchronous subprocesses).
A graph that uses the Synchronize Subprocesses activity will implement the following pattern:
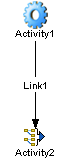
Activity1 is an Integration Manager Component that performs a fan-out by spawning multiple subprocess instances inside a Repeat While loop, as part of the component's implementation. (This can be done via the Process Execute action, which has spawn as well as call modes.) Activity1 constitutes the fan-out. Activity2, the Synchronize Subprocesses activity (which has its own distinct icon), constitutes the fan-in.
When a subprocess is invoked via spawn, the Process Server returns a Flow Instance ID to the caller. Activity1 collects Flow Instance IDs for each subprocess that it invokes and passes the list of IDs to the Synchronize Subprocesses activity.
The Synchronize Subprocesses activity's implementation consists of a Integration Manager XML Map, JDBC, or other Component. This component receives, as input, the list of Flow Instance IDs mentioned above, plus a collation document. The latter is used at runtime to accumulate data returned by "fanee" subprocesses. The Process Server mechanics for this are described in a later chapter, but the key notion is that the fan-in component is notified (called by the runtime engine) each time a fanee returns, and the associated work-item data is added to the collation doc. When every fanee is accounted for, the component exits with a condition of true and its output (a completed batch of work) is mapped forward to the next activity or activities in the model.
Below is a brief recap of key concepts. You should keep these concepts in mind as you create models in Process Designer.
Activities can be of five types:
There are two flavors of Web Service activity. The Web Service Send type handles WSDL Solicit-Response and Notify patterns, whereas the Web Service Receive type handles WSDL Request-Response and One-Way operations.
Synchronize Subprocesses is a specialized type of activity (unique to Process Manager) that provides for synchronization of fan-outs.
A Subprocess is simply any Integration Manager process that is being used as an activity inside a larger process. The use of processes as activities makes possible hierarchical modelling of business workflows.
A process model can coordinate the flow of data and control between a heterogeneous mix of local and offsite applications (including Web Services administered by business partners).
A Start Activity has no inbound links. An End Activity has no outgoing links. All other activities have one or more incoming links and zero or more outgoing links.
Data dependencies between activities are implemented by means of data links. In Process Designer, data links are not drawn by the user; they are created automatically when you map one activity's output message part(s) to another activity's input message part(s).
Time-order dependencies between activities are enforced by means of control links. A control link connects a source activity to a target activity. The link guarantees that the target cannot execute before the source does. A corollary of this is that cyclic graph patterns (where downstream activities have links pointing to upstream activities) is not allowed.
Synchronization of work is accomplished through joins.
Conditional flow of data is under the control of link logic (transition conditions).
Conditional triggering of an activity based on the completion of "feeder" activities is under the control of join logic (join conditions). In Deferred Mode, the join condition is not evaluated until the truth values of all incoming links are known. In Immediate Mode, the join condition evaluates every time a source link evaluates.
Data-overwrites can be controlled through the use of map policies (in cases where two source activities might target the same XPath location in the input to the next activity). The policy can be Last Writer Wins (arrival-order overwrite), First Writer Wins (first mapping is permanent; late data is ignored), and literal map-order.
Retry behavior is under the control of activity exit conditions and/or timeout values. If an exit condition is false, the activity reexecutes using the original input. The activity keeps reexecuting until the exit condition is true or a timeout occurs, whichever comes first.
Link and exit conditions must be specified using XPath. Join conditions cannot use XPath; they are specified via boolean expressions involving link truth values.
The Process Server is the runtime engine that manages the execution of process instances. It persists state information, instance data, etc. at all points in a process's life cycle.
Processes can be monitored and administered (suspended, resumed, etc.) via the Process Server Console.
WSFL defines (and Process Manager supports) lifecycle events spawn, call, suspend, resume, enquire, and terminate.
Suspend, resume, and terminate events can be controlled administratively via the Process Server Console. The enquire event (meant for status queries) is not labelled as such in the console; rather, complete status information is displayed in a Process Status view, available at any time. Spawn and call are under the control of a process's initiator, which might be a SOAP server responding to a request, a component that has executed a Process Execute action, etc.
The key feature of a WSFL-based process model is its reliance on units of work that know nothing about each other's implementation details, yet can interact cooperatively based on known interfaces. In this type of system, the units of work (activities) have no knowledge of—and should need no knowledge of—the context in which they are being used. Everything an activity needs to know is contained in the input message to the activity.
A good process model leverages this principle of separation of interfaces from implementations. This not only makes for efficient code reuse but opens the door to interoperability across technologies, platforms, partners, etc. It also greatly eases troubleshooting, testing, and maintenance.
Characteristics of a well-designed process model include:
A well-factored activity layer. No single activity tries to "do too much." No activity is monolithic in functional requirements.
Every activity has been designed to run standalone, with no special knowledge of its neighbor activities.
Every activity has clear-cut data-input needs and correspondingly clear data-output responsibilities.
Activity-to-activity data dependencies are explicitly described in message mappings.
Business logic is completely hidden inside activity implementations. No business logic is attempted in any message maps.
NOTE: Message mappings between activities should exhibit coarse granularity. Element-level transformations of the underlying XML (i.e., fine-granularity document manipulation) should be done inside activity implementations, not in the process model.
The flow graph is easy to read and comprehend. If a graph starts to grow beyond a handful activities or joins, consider factoring out related activities into subprocesses. A model with dozens of splits, joins, activities, etc., may be extremely difficult to test or debug, whereas if the same model can be factored into three or four subprocesses, each with only three or four activities, the subprocesses can very likely be tested standalone, then combined into a final, unified model that is robust.
Copyright © 2004 Novell, Inc. All rights reserved. Copyright © 1997, 1998, 1999, 2000, 2001, 2002, 2003 SilverStream Software, LLC. All rights reserved. more ...