2.5 Fault-Tolerant and High-Availability Architectures
To achieve fault tolerance and high availability in your storage architecture, you should consider incorporating one or more of the following technologies:
2.5.1 Multiple Path I/O
Multiple paths (multipathing) between the CPU/server and the disks can help to avoid a single point of failure in the connection between the CPU and the storage device. SUSE Linux Enterprise Server 10 provides automatic path failover with its Linux multipath tools such as Device Mapper - Multipath I/O.
Multipath I/O is available in DAS, NAS server, and SAN storage solutions.
-
In the case of external DAS and NAS server solutions, you can set up separate adapters in the server to attach to separate ports on the storage device.
-
In SAN configurations, the number of paths between the server and the storage disks is more difficult to track manually. Typically, you have at least two host bus adapters in each server. Each adapter connects to your fabric through a different switch for redundancy and performance. Each switch connects to the storage device through separate ports.
For more information, see Managing Multipath I/O for Devices
in the SLES 10 SP3/SP4: Storage Administration Guide.
2.5.2 Software RAIDs
Building fault-tolerant disks can help maximize reliability. You can use RAID 1 (mirroring) to eliminate a single point of failure such as the failure of a physical disk. By using disk duplexing, each disk in the mirror set is on a separate controller. This eliminates another single point of failure such as the failure of a bus.
Data needs to be protected against losses that result from hardware failure. Typically, you need to configure devices with a software or hardware RAID 1 or RAID 5 solution. RAID 1 provides mirroring of the entire storage area. On failure of a single device, the mirror takes over and all data is immediately available to users.
RAID 5 provides striping with parity to allow recovery of data on the failure of a single hard disks. Service is degraded during the recovery, but all data is eventually reconstructed without data loss. Use RAID 5 when you want to optimize file access for a server, while also providing for protection against the loss of a single disk.
For more information, see Managing NSS Software RAID Devices
in the OES 2 SP3: NSS File System Administration Guide for Linux.
SUSE Linux Enterprise Server 10 also provides a Linux software RAID solution for RAIDs 0, 1, and 5. For information, see Managing Software RAIDs with EVMS
in the SLES 10 SP3/SP4: Storage Administration Guide.
2.5.3 Server Clusters
Novell Cluster Services combines two or more servers into a single group, known as a cluster. If one server in the cluster fails, another server automatically recovers the downed server’s resources (applications, services, IP addresses, and volumes) and runs in its place. With Novell Cluster Services, you can configure up to 32 OES 2 Linux servers into a high-availability cluster where resources are dynamically allocated to any server in the cluster.
Resources can be configured to automatically switch in the event of a server failure, or can be moved manually to troubleshoot hardware, balance workloads, or perform maintenance. This frees IT organizations to perform maintenance and upgrades during production hours and eliminates scheduling down time with customer organizations.
In the event of an unplanned failure, any server in the cluster can restart resources from a failed server in the cluster. Typically, the failover occurs transparently to users with seamless access to authorized resources.
High-Availability Clusters
To configure a fault-tolerant Novell Cluster Services solution, a shared disk system is required for each cluster. All servers in the cluster are configured with the IP protocol and are on the same IP subnet in the same eDirectory tree. Additional IP addresses are required for each cluster resource and cluster-enabled volume.
There are three basic ways to share a volume:
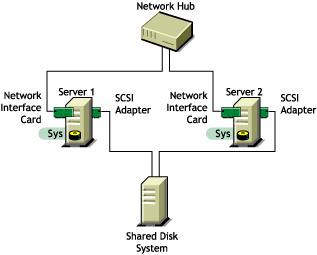
Shared Volume on Direct Attached Storage
For less complex needs, you can create a cluster using a the shared volume on direct attached storage.
Figure 2-1 Example of a Shared Volume Cluster Using Direct Attached Storage
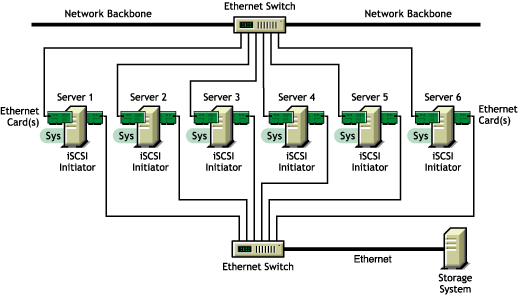
Shared Volume in an iSCSI SAN
A new high-availability solution for shared volume clusters uses iSCSI protocols to connect the servers to the shared volume over commodity Ethernet and TCP/IP networks. Using these standard LAN technologies, iSCSI SANs can be centralized, distributed over multiple geographical locations, or configured as distributed mirrors so that one SAN continues in the event of failure of the other.
For information, see Mass Storage over IP Networks - iSCSI
in the SUSE Linux Enterprise Server 10 Installation and Administration Guide.
Figure 2-2 Example of a Shared Volume Cluster Using an iSCSI SAN
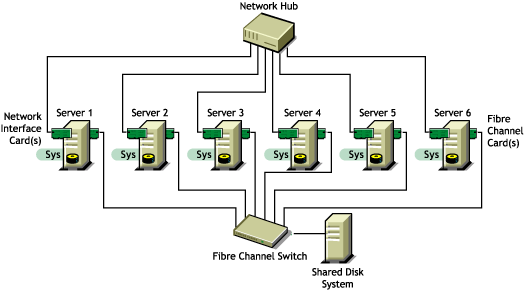
Shared Volume in a Fibre Channel SAN
The Fibre Channel SAN is the conventional method of creating high-availability clusters. For more information, see the OES 2 SP3: Novell Cluster Services 1.8.8 Administration Guide for Linux.
Figure 2-3 Example of a Shared Volume Cluster Using a Fibre Channel SAN
2.5.4 Novell Cluster Services
Novell Cluster Services ensures high availability and manageability of critical network resources including data (volumes), applications, server licenses, and services and provides the ability to tailor a cluster to the specific applications and hardware infrastructure for any organization. The Novell Cluster Services installation program automatically creates a new cluster object in eDirectory and installs Novell Cluster Services software on any servers specified to be part of the cluster. You can configure SANs and shared NSS pools in conjunction with clustered servers to create high availability networks.
Novell Cluster Services management provides remote cluster resources management from any Java-enabled Web browser. Server storage can be dynamically assigned or reassigned on an as-needed basis and administrators are automatically notified of cluster events and cluster state changes.
For information, see the OES 2 SP3: Novell Cluster Services 1.8.8 Administration Guide for Linux and the OES 2 SP3: Novell Cluster Services NetWare to Linux Conversion Guide.