8.2 Planning for OES Cluster Services
This section describes the requirements for installing and using Cluster Services on Open Enterprise Server (OES) servers.
IMPORTANT:For information about designing your cluster and cluster environment, see Section 8.0, Clustering and High Availability.
8.2.1 Cluster Administration Requirements
You use different credentials to install and set up the cluster and to manage the cluster. This section describes the tasks performed and rights needed for those roles.
Cluster Installation Administrator
Typically, a tree administrator user installs and sets up the first cluster in a tree, which allows the schema to be extended. However, the tree administrator can extend the schema separately, and then set up the necessary permissions for a container administrator to install and configure the cluster.
NOTE:If the eDirectory administrator user name or password contains special characters (such as $, #, and so on), some interfaces in iManager and YaST might not handle the special characters. If you encounter problems, try escaping each special character by preceding it with a backslash (\) when you enter credentials.
eDirectory Schema Administrator
A tree administrator user with credentials to do so can extend the eDirectory schema before a cluster is installed anywhere in a tree. Extending the schema separately allows a container administrator to install a cluster in a container in that same tree without needing full administrator rights for the tree.
IMPORTANT:It is not necessary to extend the schema separately if the installer of the first cluster server in the tree has the eDirectory rights necessary to extend the schema.
Container Administrator
After the schema has been extended, the container administrator (or non-administrator user) needs the following eDirectory rights to install OES Cluster Services:
-
Attribute Modify rights on the NCP Server object of each node in the cluster.
-
Object Create rights on the container where the NCP Server objects are.
-
Object Create rights where the cluster container will be.
For instructions, see Assigning Install Rights for Container Administrators or Non-Administrator Users.
NCS Proxy User
During the cluster configuration, you must specify an NCS Proxy User. This is the user name and password that Cluster Services uses when the cluster management tools exchange information with eDirectory.
Cluster Services supports the OES Common Proxy User enablement feature of eDirectory. The proxy user is represented in eDirectory as a User object named OESCommonProxy_<server_name>.<context>. If the OES Common Proxy user is enabled in eDirectory when you configure a node for the cluster, the default NCS Proxy User is set to use the server’s OES Common Proxy User. You can alternatively specify the LDAP Admin user or another administrator user.
The specified NCS Proxy User for the node is automatically assigned as a member in the <cluster_name>_MGT_GRP.<context> group that resides in the Cluster object container, such as clus1_MGT_GRP.ncs.novell. The group accommodates the server-specific NCS Proxy Users that you assign when you configure each node for the cluster. Members are added to the group as you configure each node for a cluster. Each member of the group has the necessary rights for configuring the cluster and cluster resources and for exchanging information with eDirectory.
For example, Figure 8-2 shows that an OES Common Proxy User has been assigned as the NCS Proxy User for each node in a four-node cluster. The nodes are named avalon, camelot, excalibur, and cornwall. The context is novell.
Figure 8-2 Members of the NCS Management Group for a Cluster
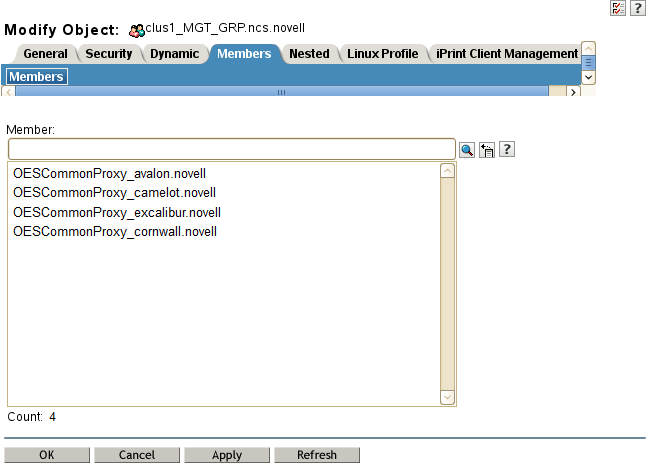
IMPORTANT:You can modify this default administrator user name or password for the user name assigned as the NCS Proxy User after the install by following the procedure in Moving a Cluster, or Changing the Node IP Addresses, LDAP Servers, or Administrator Credentials for a Cluster.
Consider the following caveats for the three proxy user options:
OES Common Proxy User
If you specify the OES Common Proxy user for a cluster and later disable the Common Proxy user feature in eDirectory, the LDAP Admin user is automatically assigned to the <cluster_name>_MGT_GRP.<context> group, and the OES Common Proxy user is automatically removed from the group.
If an OES Common Proxy User is renamed, moved, or deleted in eDirectory, eDirectory takes care of the changes needed to modify the user information in the <cluster_name>_MGT_GRP.<context> group.
If a cluster node is removed from the tree, the OES Common Proxy User for that server is one of the cluster objects that needs to be deleted from eDirectory.
For information about enabling or disabling the OES Common Proxy User, see the OES 2018 SP2: Installation Guide. For caveats and troubleshooting information for the OES Common Proxy user, see the OES 2018 SP2: Planning and Implementation Guide.
LDAP Admin User
If you specify the LDAP Admin user as the NCS Proxy User, you typically continue using this identity while you set up the cluster and cluster resources. After the cluster configuration is completed, you create another user identity to use for NCS Proxy User, and grant that user sufficient administrator rights as specified in Cluster Administrator or Administrator-Equivalent User.
Another Administrator User
You can specify an existing user name and password to use for the NCS Proxy User. Cluster Services adds this user name to the <cluster_name>_MGT_GRP.<context> group.
Cluster Administrator or Administrator-Equivalent User
After the install, you can add other users (such as the tree administrator) as administrator equivalent accounts for the cluster by configuring the following for the user account:
-
Give the user the Supervisor right to the Server object of each of the servers in the cluster.
-
Linux-enable the user account with Linux User Management (LUM).
-
Make the user a member of a LUM-enabled administrator group that is associated with the servers in the cluster.
8.2.6 Software Requirements for Cluster Services
Ensure that your system meets the following software requirements for installing and managing Cluster Services:
Open Enterprise Server 2018 SP2
Cluster Services for Linux supports Open Enterprise Server 2018 SP2. OES Cluster Services is one of the OES Services patterns.
We recommend having uniform nodes in the cluster. The same release version of OES must be installed and running on each node in the cluster.
Mixed-mode clusters with different operating system platforms are supported during rolling cluster upgrades or conversions for the following scenarios:
|
Upgrading from |
See: |
|---|---|
|
OES 11 SP2 or later |
|
|
NetWare 6.5 SP8 |
OES 2015 SP1: Novell Cluster Services NetWare to Linux Conversion Guide |
Cluster Services
Cluster Services is required for creating and managing clusters and shared resources on your OES servers. OES Cluster Services is one of the OES Services patterns on OES 2018 SP2.
NetIQ eDirectory 9.2.1
NetIQ eDirectory is required for managing the Cluster object and Cluster Node objects for Cluster Services. eDirectory must be installed and running in the same tree where you create the cluster. eDirectory can be installed on any node in the cluster, on a separate server, or in a separate cluster. You can install an eDirectory master replica or replica in the cluster, but it is not required to do so for Cluster Services.
For information about using eDirectory, see NetIQ eDirectory Administration Guide.
IMPORTANT:Because the cluster objects and their settings are stored in eDirectory, eDirectory must be running and working properly whenever you modify the settings for the cluster or the cluster resources.
In addition, ensure that your eDirectory configuration meets the following requirements:
eDirectory Tree
All servers in the cluster must be in the same eDirectory tree.
eDirectory Context
If you are creating a new cluster, the eDirectory context where the new Cluster object will reside must be an existing context. Specifying a new context during the Cluster Services configuration does not create a new context.
Cluster Object Container
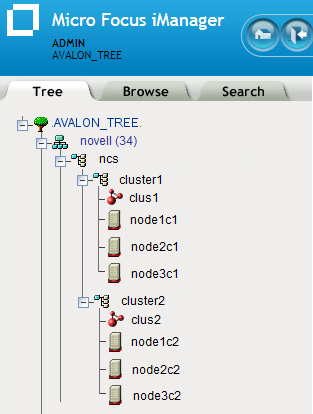
We recommend that the Cluster object and all of its member Server objects and Storage objects be located in the same OU context. Multiple Cluster objects can co-exist in the same eDirectory container. In iManager, use > to create a container for the cluster before you configure the cluster.
For example, Figure 8-3 shows an example where all clusters are configured in the ncs organizational unit. Within the container, each cluster is in its own organizational unit, and the Server objects for the nodes are in the same container as the Cluster object:
Figure 8-3 Same Container for Cluster Object and Server Objects
If the servers in the cluster are in separate eDirectory containers, the user that administers the cluster must have rights to the cluster server containers and to the containers where any cluster-enabled pool objects are stored. You can do this by adding trustee assignments for the cluster administrator to a parent container of the containers where the cluster server objects reside. For more information, see eDirectory Rights
in the NetIQ eDirectory Administration Guide.
Renaming a pool involves changing information in the Pool object in eDirectory. If Server objects for the cluster nodes are in different containers, you must ensure that the shared pool is active on a cluster node that has its NCP server object in the same context as the Pool object of the pool you are going to rename. For information about renaming a shared pool, see Renaming a Clustered NSS Pool .
Cluster Objects Stored in eDirectory
Table 8-1 shows the cluster objects that are automatically created and stored in eDirectory under the Cluster object ( ) after you create a cluster:
) after you create a cluster:
Table 8-1 Cluster Objects
|
Icon |
eDirectory Object |
|---|---|
|
|
Master_IP_Address_Resource |
|
|
Cluster Node object (servername) |
|
|
Resource Template objects. There are 11 default templates:
|



For example, Figure 8-4 shows the 13 default eDirectory objects that are created in the Cluster container as viewed from the Tree view in iManager:
Figure 8-4 Tree View of the Default eDirectory Objects in the Cluster
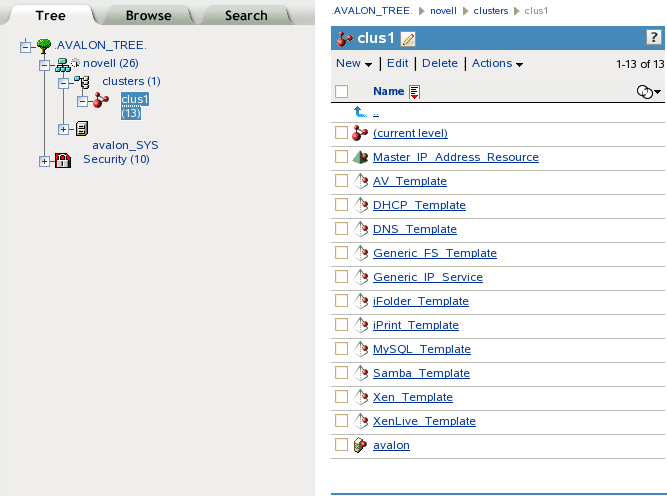
Table 8-2 shows the cluster objects that are added to eDirectory when you add nodes or create cluster resources:
Table 8-2 Cluster Resource Objects
|
Icon |
eDirectory Object |
|---|---|
|
|
Cluster Node object (servername) |
|
|
NSS Pool Resource object (poolname_SERVER) |
|
|
Resource object |

Table 8-3 shows the cluster objects that are added to eDirectory when you add nodes or create cluster resources in a Business Continuity Cluster, which is made up of OES Cluster Services clusters:
Table 8-3 BCC Cluster Resource Objects
|
Icon |
eDirectory Object |
|---|---|
|
|
BCC NSS Pool Resource object |
|
|
BCC Resource Template object |
|
|
BCC Resource object |



LDAP Server List
If eDirectory is not installed on a node, it looks to the LDAP server list for information about which LDAP server to use. As a best practice, you should list the LDAP servers in the following order:
-
Local to the cluster
-
Closest physical read/write replica
For information about configuring a list of LDAP servers for the cluster, see Changing the Administrator Credentials or LDAP Server IP Addresses for a Cluster.
SLP
SLP (Service Location Protocol) is a required component for Cluster Services on Linux when you are using NCP to access file systems on cluster resources. NCP requires SLP for the ncpcon bind and ncpcon unbind commands in the cluster load and unload scripts. For example, NCP is needed for NSS volumes and for NCP volumes on Linux POSIX file systems.
SLP is not automatically installed when you select Cluster Services. SLP is installed as part of the eDirectory configuration during the OES installation. You can enable and configure SLP on the eDirectory Configuration - NTP & SLP page. For information, see Specifying SLP Configuration Options
in the OES 2018 SP2: Installation Guide.
When the SLP daemon (slpd) is not installed and running on a cluster node, any cluster resource that contains the ncpcon bind command goes comatose when it is migrated or failed over to the node because the bind cannot be executed without SLP.
The SLP daemon (slpd) must also be installed and running on all nodes in the cluster when you manage the cluster or cluster resources.
NCP Server re-registers cluster resource virtual NCP servers with SLP based on the setting for the eDirectory advertise-life-time (n4u.nds.advertise-life-time) parameter. The parameter is set by default to 3600 seconds (1 hour) and has a valid range of 1 to 65535 seconds.
You can use the ndsconfig set command to set the n4u.nds.advertise-life-time parameter. To reset the parameter in a cluster, perform the following tasks on each node of the cluster:
-
Log in to the node as the root user, then open a terminal console.
-
Take offline all of the cluster resources on the node, or cluster migrate them to a different server. At a command prompt, enter
cluster offline <resource_name> or cluster migrate <resource_name> <target_node_name>
-
Modify the eDirectory SLP advertising timer parameter (n4u.nds.advertise-life-time), then restart ndsd and slpd. At a command prompt, enter
ndsconfig set n4u.nds.advertise-life-time=<value_in_seconds> rcndsd restart rcslpd restart -
Bring online all of the cluster resources on the node, or cluster migrate the previously migrated resources back to this node.
cluster online <resource_name> or cluster migrate <resource_name> <node_name>
-
Repeat the previous steps on the other nodes in the cluster.
OpenSLP stores the registration information in cache. You can configure the SLP Directory Agents to preserve a copy of the database when the SLP daemon (slpd) is stopped or restarted. This allows SLP to know about registrations immediately when it starts.
For more information about configuring and managing SLP, see Configuring OpenSLP for eDirectory
in the NetIQ eDirectory Administration Guide.
iManager 3.2.1
iManager is required for configuring and managing clusters on OES.
iManager must be installed on at least one computer in the same tree as the cluster. It can be installed in the cluster or not in the cluster. For information about using iManager, see the iManager documentation website.
For SFCB (Small Footprint CIM Broker) and CIMOM requirements, see SFCB and CIMOM.
For browser configuration requirements, see Web Browser.
Clusters Plug-in for iManager
The Clusters plug-in for iManager provides the Clusters role where you can manage clusters and cluster resources with OES Cluster Services. The plug-in can be used on all operating systems supported by iManager and iManager Workstation.
The following components must be installed in iManager:
-
Clusters (ncsmgmt.rpm)
-
Common code for storage-related plug-ins (storagemgmt.rpm)
If iManager is also installed on the server, these files are automatically installed in iManager when you install OES Cluster Services.
The Clusters plug-in also provides an integrated management interface for OES Business Continuity Clustering (BCC). The additional interface is present only if BCC is installed on the server. See the following table for information about the versions of BCC that are supported. BCC is sold separately from OES. For purchasing information, see the BCC product page.
|
BCC Release |
OES Support |
iManager and Clusters Plug-In |
|---|---|---|
|
BCC 2.6 |
OES 2018 SP1 and later |
NetIQ iManager 3.1 or later Requires the Clusters plug-in for OES 2018 SP2 with the latest patches applied. See the BCC 2.6 Administration Guide. |
|
BCC 2.0 |
OES 11 SP1 |
Novell iManager 2.7.6 or later Requires the Clusters plug-in for OES 11 SP1 with the latest patches applied. |
|
BCC 1.2.2 |
OES 2 SP3 |
Novell iManager 2.7.4 or later Requires the Clusters plug-in for OES 2 SP3 and the OES 2 SP3 April 2011 Scheduled Maintenance patch. |
|
BCC 1.2.1 |
OES 2 SP2 |
Novell iManager 2.7.3 or later Requires the Clusters plug-in in the OES 2 SP2 January 2010 Maintenance patch. |
|
BCC 1.1 SP2 |
NetWare 6.5 SP8 |
Novell iManager 2.7.2 or later Requires the Clusters plug-in released in OES 2 SP1 Linux or NetWare 6.5 SP8, or a later version. See the BCC 1.1 SP2 Administration Guide for NetWare 6.5 SP8. |
Storage-Related Plug-Ins for iManager
In OES 11 and later, the following storage-related plug-ins for iManager share code in common in the storagemgmt.rpm file:
|
Product |
Plug-In |
NPM File |
|---|---|---|
|
Novell Apple Filing Protocol (AFP) |
File Protocols > AFP |
afpmgmt.rpm |
|
Novell CIFS |
File Protocols > CIFS |
cifsmgmt.rpm |
|
Novell Cluster Services |
Clusters |
ncsmgmt.rpm |
|
Novell Distributed File Services |
Distributed File Services |
dfsmgmt.rpm |
|
Novell Storage Services |
Storage |
nssmgmt.rpm |
These additional plug-ins are needed when working with the NSS file system. Ensure that you include the common storagemgmt.rpm plug-in module when installing any of these storage-related plug-ins.
IMPORTANT:If you use more than one of these plug-ins, you should install, update, or remove them all at the same time to ensure that the common code works for all plug-ins.
Ensure that you uninstall the old version of the plug-ins before you attempt to install the new versions of the plug-in files.
The plug-in files are included on the installation disk. The latest storage-related plug-ins can be downloaded as a single zipped download file from the Micro Focus Downloads website. For information about installing plug-ins in iManager, see Downloading and Installing Plug-in Modules
in the NetIQ iManager Administration Guide.
For information about working with storage-related plug-ins for iManager, see Understanding Storage-Related Plug-Ins
in the OES 2018 SP2: NSS File System Administration Guide for Linux.
SFCB and CIMOM
The Small Footprint CIM Broker (SFCB) replaces OpenWBEM for CIMOM activities in OES 11 and later. SFCB provides the default CIMOM and CIM clients. When you install any OES components that depend on WBEM, SFCB and all of its corresponding packages are installed with the components. For more information, see Section L.0, Small Footprint CIM Broker (SFCB)
.
IMPORTANT:SFCB must be running and working properly whenever you modify the settings for the cluster or the cluster resources.
Port 5989 is the default setting for Secure HTTP (HTTPS) communications. If you are using a firewall, the port must be opened for CIMOM communications. Ensure that the CIMOM broker daemon is listening on port 5989. Log in as the root user on the cluster master node, open a terminal console, then enter the following at the command prompt:
netstat -an |grep -i5989
The Clusters plug-in (and all other storage-related plug-ins) for iManager require CIMOM connections for tasks that transmit sensitive information (such as a user name and password) between iManager and the _admin volume on the OES server that you are managing. Typically, CIMOM is running, so this should be the normal condition when using the server. CIMOM connections use Secure HTTP (HTTPS) for transferring data, and this ensures that sensitive data is not exposed.
IMPORTANT:SFCB is automatically PAM-enabled for Linux User Management (LUM) as part of the OES installation. Users not enabled for LUM cannot use the CIM providers to manage OES. The user name that you use to log in to iManager when you manage a cluster and the BCC cluster must be an eDirectory user name that has been LUM-enabled.
For more information about the permissions and rights needed by the administrator user, see Section 8.2.1, Cluster Administration Requirements.
IMPORTANT:If you receive file protocol errors, it might be because SFCB is not running.
You can use the following commands to start, stop, or restart SFCB:
|
To perform this task |
At a command prompt, enter as the root user |
|---|---|
|
To start SFCB |
rcsfcb start or systemctl start sblim-sfcb.service |
|
To stop SFCB |
rcsfcb stop or systemctl stop sblim-sfcb.service |
|
To check SFCB status |
rcsfcb status or systemctl status sblim-sfcb.service |
|
To restart SFCB |
rcsfcb restart or systemctl restart sblim-sfcb.service |
For more information, see Web Based Enterprise Management using SFCB
in the SUSE Linux Enterprise Server 12 Administration Guide.
OES Credential Store (OCS)
Cluster Services requires OES Credential Store to be installed and running on each node in the cluster.
To check whether the OCS is running properly, do the following:
-
At the command prompt, enter as the root user.
-
Run the following command:
oescredstore -l
Web Browser
For information about supported web browsers for iManager, see System Requirements for iManager Server
in the NetIQ iManager Installation Guide.
The Clusters plug-in for iManager might not operate properly if the highest priority Language setting for your web browser is set to a language other than one of the supported languages in iManager. To view a list of supported languages and codes in iManager, select the tab, click . The language codes are Unicode (UTF-8) compliant.
To avoid display problems, in your web browser, select > > , and then set the first language preference in the list to a supported language. You must also ensure the Character Encoding setting for the browser is set to Unicode (UTF-8) or ISO 8859-1 (Western, Western European, West European).
-
In a Mozilla browser, select > , then select the supported character encoding setting.
-
In an Internet Explorer browser, select > , then select the supported character encoding setting.