4.1 How Archive Jobs Work
When an archive dredge job is running, the work flow follows this pattern.
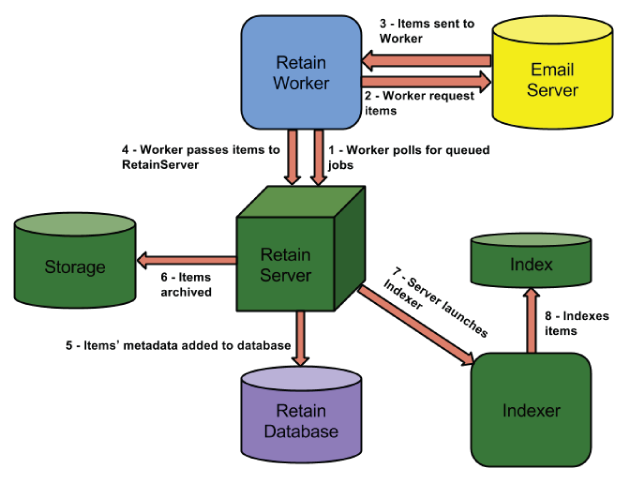
-
The Worker polls the Server every 10 minutes (default) for new queued jobs it may need to run. It launches the job.
-
The Worker connects to the messaging system, logs in to each mailbox, and requests the items in that mailbox based on the settings in the profile.
-
The messaging system responds by sending the items to the Worker.
-
The Worker sends smaller items to the Server. For large items, it sends the item’s metadata and awaits instructions from the Server as to whether the item already exists.
-
If it already exists, the Retain Server notifies the Worker that it does not need to send the item over.
-
If it does not exist, the Retain Server notifies the Worker to send the item.
-
-
The Retain Server updates the Retain database with a record of the item's metadata if a record does not already exist.
-
The Server adds the item to the storage area on disk.
-
The Server launches the indexing process (if it is not already running) to begin the indexing process.
-
The Indexer indexes any items that need to be indexed.