2.1 Retain Planning and Design Best Practices
There are so many variables that impact performance and design that no single document could adequately cover them. Instead, this document mostly discusses concepts so that the reader can apply them their needs. This document has four major sections:
-
Retain Architecture
-
Hardware Design
-
Retain Configuration
-
Backing Up Retain
This document's intent is to provide insight into how Retain works so you know how to design your system. It will provide some guidelines and best practices; however, it does not attempt to make hardware recommendations or provide specifications of such. It is anticipated that the reader will understand how Retain works, how the various hardware components play a role, and be able to make hardware decisions based on that understanding. Again, no two systems are alike, so one size does not fit all. And, keep in mind, Retain's minimum system requirements are MINIMUMS. Retain will work with those minimums; but, if performance is a priority, then read on and apply these concepts to your specific situation.
2.1.1 Retain Architecture
Retain can run on a bare metal server or on a VM running Windows Server or SuSE Linux. For backup purposes and flexibility, we recommend running it on a VM.
Retain consists of four major components:
-
Server
-
Worker
-
Indexer
-
Database
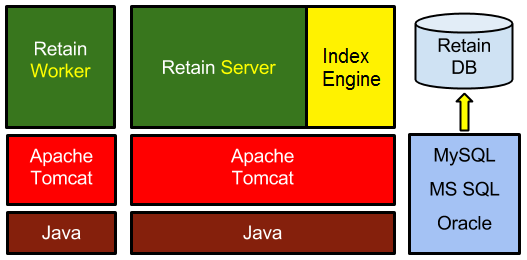
Server
The Server is where the archive system is configured and maintained. It is responsible for storing, indexing, searching, and reading archived items.
Worker
The Worker is the component that interfaces with the messaging host/mail server containing the messages you are archiving. It retrieves the messages and passes them onto the Retain Server. A worker does just one job at a time. Multiple jobs can be queued up for a worker, but it is up to you to make sure not so many jobs are given to a worker that it takes longer than a day for the worker to complete them all.
Indexer
The indexer scans the messages and attachments to make them searchable, indexing each word and some phrases. When a user performs a search in his/her Retain mailbox, the list of messages returned is coming from the indexer, not the database. Understanding that difference helps you make decisions on memory configuration choices for Tomcat (which powers the indexer) and for the database. The index process is the most memory intensive (I.E. uses the most memory) part of Retain.
Database
The database stores most of the Retain configuration as well as the message metadata, which is information about the messages being store (subject, sender, recipients, links to attachments, indexed state of messages, folder location of the message, etc). When a user logs in to his/her Retain mailbox, the list of folders and their messages are being retrieved from the database.
2.1.2 Retain is Modular
Retain is modular so components and agent software can be installed on different servers to better meet the needs of your system.
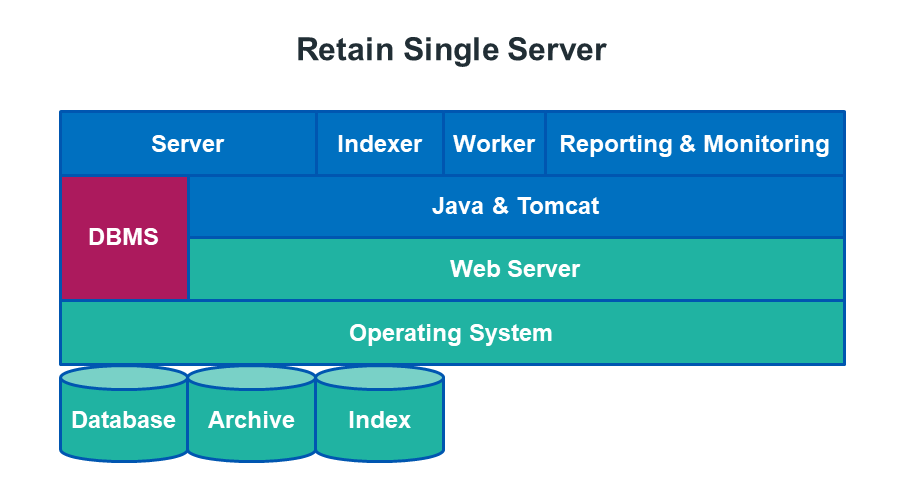
Small All in One Systems
For a proof of concept or a system that is small, a few hundred users, an all-in-one Retain system is recommended.
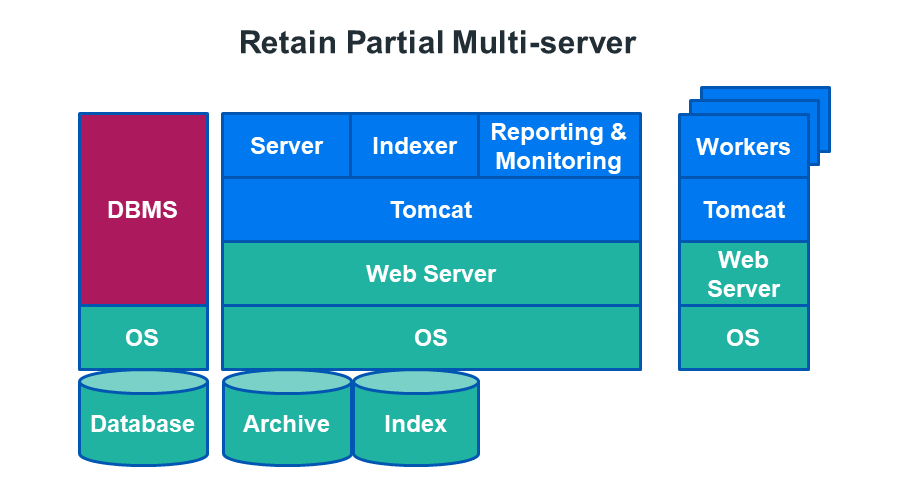
Partial Multi-server Systems
A larger system that already has a dedicated database server and several post offices may connect Retain to the existing database server and install multiple worker agents on other server(s). We recommend one worker agent per post office.
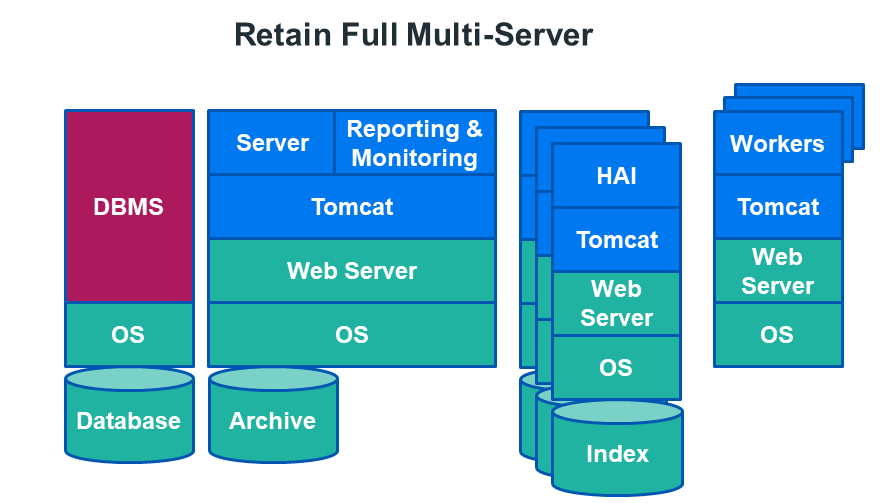
Multi-server System
A very large system that requires high availability for searching the Retain archive can use the High Availability Indexer, requires a separate license and at least a 3 server cluster.
2.1.3 Worker Location
Worker Agents can be installed in three different locations: the Retain server, a worker server and/or the post office server(s). These locations are not mutually exclusive, so you may choose the location that best serves your systems needs.
Retain Server
The Retain server is the default place to place a worker. It is recommended to have a worker on the Retain server at least for troubleshooting purposes. A worker running an archive job will impact performance. If the impact is too large it is recommended to install workers in a different location.
Having the Worker on the Retain Server means that all the items will have to be sent across the network from the post office server the Worker is servicing. See Archive Job Flow
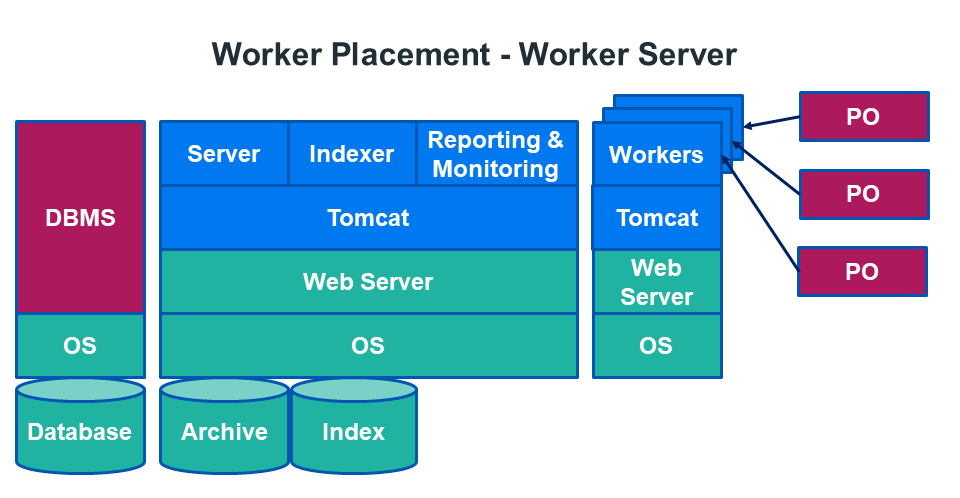
Worker Server
A Worker server is a dedicated server with one or more worker agents installed on it. This frees up resources for the Retain server.
Having the Worker on a dedicated Worker Server means that all the items will have to be sent across the network from the post office server the Worker is servicing. See Archive Job Flow
Post Office Server
A Worker can be installed on a post office server. This frees up resources for the Retain server and reduces network bandwidth requirements.
Having the Worker on a post office server means that only some the items will have to be sent across the network from the post office server the Worker is servicing, because there are many duplicate messages.
As a rule-of-thumb we have noticed that about 20% of messages will be duplicated across the post office server. When the worker contacts the server, the archive is checked to see if the message already exists and if it does the whole message does not need to be sent again. Only the header data is added and the database updated to point these together. See Archive Job Flow
