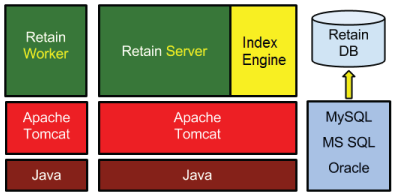
3.1 Retain Architecture
Retain can run on
-
Stand-alone server hardware
Or
-
A Virtual Machine hosted on a Windows or SuSE Linux supported hypervisor.
This is the best-practice recommendation for backup purposes and flexibility.
Retain must have these four components:
-
Server
-
Worker
-
Indexer
-
Database