Kafka Reference Guide
1.0 Overview
Apache Kafka is a distributed publish-subscribe messaging system that enables passing of messages from one system to another, while handling large volumes of data. Kafka can be enabled on a single Linux or Appliance Primary Server or can be run as a cluster on one or more Linux or Appliance servers that can span multiple data centers. Each server in the cluster is called a broker. Kafka is run as a cluster to ensure high availability of its services by replicating Kafka topics or messages to multiple Kafka brokers. Kafka requires ZooKeeper to co-ordinate between the servers within the Kafka cluster. For more information on ZooKeeper, see Managing ZooKeeper in the ZENworks Primary Server and Satellite Reference
In ZENworks, Apache Kafka is required for the following components:
-
Vertica: For more information, see ZENworks Vertica Guide
-
Antimalware: For more information, see ZENworks Endpoint Security Antimalware Reference
You can enable Apache Kafka either through the ZENworks Control Center or by using the ZMAN utility.
1.1 Kafka Change Data Capture Workflow
The following diagram is a graphical representation of the Kafka workflow:
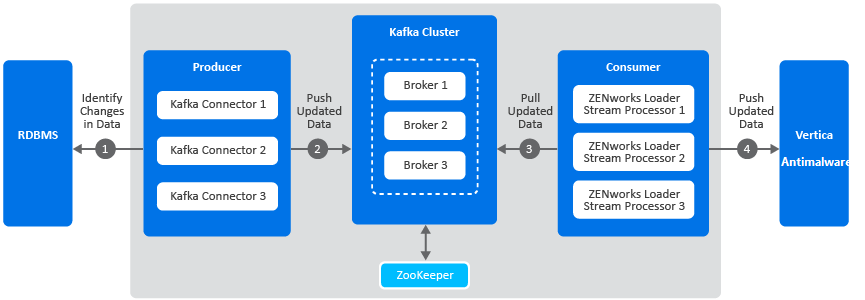
A description of each component in this architecture is as follows:
-
Kafka Cluster: A group of servers or nodes that are connected to each other to achieve a common objective is a cluster. Each of the servers or nodes in the cluster, will have one instance of Kafka broker running.
-
Kafka Broker: One or more servers that are added in a Kafka cluster are called brokers.
-
Apache ZooKeeper: Kafka uses ZooKeeper to manage and co-ordinate between brokers. It notifies Kafka Producers and Consumers of any broker failures.
-
Kafka Producers: The processes that publish messages to Kafka brokers. In this case, Kafka connectors are created as soon as Kafka is enabled. These connectors are created for each table in the RDBMS database and is responsible for identifying changes in these tables and publishing them to Kafka.
-
Kafka Consumers: A service that reads data from Kafka brokers. In this case, the ZENworks loader stream processors subscribes to data from Kafka and passes this information to the Vertica or the Antimalware database.
The Kafka workflow is as follows:
-
The Kafka connectors (Kafka producer) identifies changes in the respective RDBMS database tables.
-
These changes are published to a topic within a Kafka broker. Kafka maintains messages as categories and these categories are called topics. To modify the interval at which the Kafka connector identifies changes in the RDBMS tables and publishes this data to Kafka, you can update the connector-configs.xml file (available at etc/opt/microfocus/zenworks) and run the zman srkccn command to re-configure the connectors. For more information on this command, see Maintaining Kafka Connect.
The topics are further broken down into partitions for speed and scalability. These partitions are replicated across multiple brokers, which is used for fault tolerance. The replicas are created based on the replication count specified while enabling the Kafka cluster. Each message within a partition is maintained in a sequential order, which is identified as an offset, also known as a position.
-
The ZENworks loader stream processors (consumers) subscribe to a topic, Kafka offers the current offset of the topic to the consumer and saves the offset in the ZooKeeper cluster.
-
The ZENworks loader stream processor receives the message and processes it to the Vertica or the Antimalware database and the Kafka broker receives an acknowledgment of the processed message.
Kafka also uses a Schema Registry, which is a separate entity that producers and consumers talk to, for sending and retrieving schemas that describe the data models for the messages.
For more information on the Kafka Architecture, see the Confluent docs.
2.0 Enabling Kafka on a Single Server
This section explains the procedure to enable Kafka in the zone and to configure a single server with the Kafka service. You can enable Kafka on a single server in either of the following ways:
2.1 Prerequisites
Before enabling Kafka in the zone, you need to make a note of the following requirement:
-
As Kafka requires client authentication to be enabled in the certificate, if you are using an external CA certificate, ensure that client authentication is enabled.
-
Ensure that you have already added a Linux or an Appliance server to the zone.
-
You need to first configure the Kafka cluster and then add a Kafka broker to the zone. Before adding a Kafka broker, ensure that the following prerequisites are met:
-
The Kafka cluster should already be configured.
-
The broker or server that is to be added to the cluster should not already be added to the cluster.
-
The server should be accessible and should have a specific host name. If a server has multiple host names, then the command to add the Kafka broker might fail.
-
As Kafka requires Client Authentication to be enabled in the certificate, if you are using an external CA certificate, ensure that Client Authentication is enabled in the Extended Key Usage (EKU) parameter of the server certificate.
-
2.2 Using ZENworks Control Center
-
In ZENworks Control Center (ZCC), navigate to .
-
Click .
-
Select a Linux Primary Server or an Appliance server in which Kafka should be enabled.
The Kafka service will be enabled and the first broker will be added to the Kafka cluster. To add more brokers to the cluster, see Adding Servers to the Kafka Cluster.
2.3 Using the ZMAN Utility
-
Configure the Kafka Cluster: Execute the following command:
zman server-role-kafka-configure-cluster (zman srkcc)
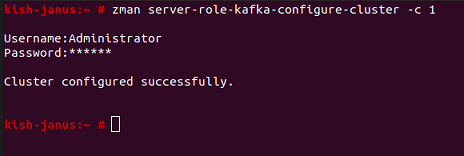
While running this command, you need to specify the replication count. If the values for the remaining parameters are not specified, then the default values are considered. The parameters are:
-
-c --replication count: This ensures that messages remain available when a server in the cluster fails.Specify the number of copies to be maintained for each topic. For a single node cluster, this count can be set as 1.
-
-l --logRetentionBytes: Specify the maximum permissible size of the log, beyond which, the existing data is overwritten with the new data. By default the log size is unlimited.
-
-t --zkSessionTimeout: Specify the ZooKeeper session timeout (in milliseconds), which is the maximum time that the server waits to establish a connection to ZooKeeper. If the server fails to signal a heartbeat to ZooKeeper within this specified time period, then the server is considered to be dead. A heartbeat request helps identify if the server is still connected to the Kafka cluster. The default value is 30000 milliseconds.
-
-r --retainDetectedLogsDuration: Specify the maximum time to retain deleted logs. The default value is 86400000 milliseconds (1 day).
-
-p --logCleanupPolicy: Specify the default cleanup policy for segments that exceed the maximum permissible retention window. The possible values are Delete and Compact. The default value is Delete. The Delete policy will remove old segments when the retention time or size limit has reached. The Compact policy will enable log compaction on the topic, which ensures that Kafka will always retain at least the last known value for each message key within the log of data for a single topic partition.
-
-s --schemaregistryport: Specify the port on which the Schema Registry is running. The default value is 8081.
-
-k --kafkaport: Specify the port on which Kafka listens. The default value is 9093.
-
-x --connectport: Specify the port on which Kafka connect listens. The default value is 8083.
For example, zman server-role-kafka-configure-cluster -c=1
-
-
Add Kafka brokers: Before adding a broker, ensure that you have read the Prerequisites. Execute the following command:
zman server-role-kafka-add-broker (zman srkab)
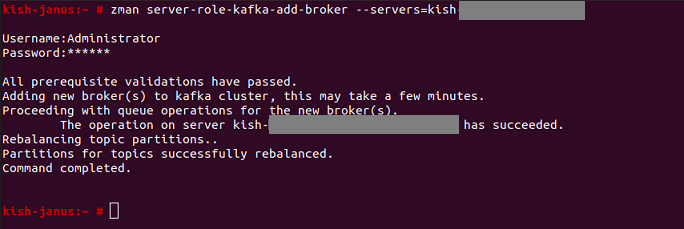
This command adds brokers or servers to the configured Kafka cluster.
NOTE:If you are using an external CA certificate, for Kafka to work as expected, ensure that Client Authentication is enabled in the Extended Key Usage (EKU) parameter of the server certificate or else an error message is displayed. However, if you want to continue to use the existing certificate, execute the command again, using the i=true parameter. Kafka might work with the existing certificate.
The parameters to be specified are:
-
--servers: Specify the appliance server on which Kafka should be enabled. Specify the DNS, GUID or path of the server object (server, server folder or server group) relative to /Devices/Servers.
-
-i --ignorewarning message (optional): As Kafka requires client authentication to be enabled in the certificate, if you are using an external CA certificate, ensure that client authentication is enabled. However, if you want to ignore the error message and continue with the existing certificate, then execute the command again with the option i set as true.
For example: zman server-role-kafka-add-broker --servers=server1.microfocus.com
When this command is executed for a server, the Kafka, Kafka connect and Schema Registry services are enabled and started on the specified server.
For more information on debugging Kafka configuration issues, see Debugging Issues and Log Locations.
You can view the status of the Kafka Cluster configuration by navigating to . For more information on monitoring the Kafka cluster, see Monitoring the Status of the Kafka Cluster.
-
5.0 Monitoring the Status of the Kafka Cluster
You can view the overall configuration status of Kafka in the page in ZCC. For more information, see Viewing the Configuration Status. However, if you want to continuously monitor the status of the Kafka Cluster, see Monitoring Diagnostics.
5.1 Viewing the Configuration Status
To view the configuration status of Kafka, you can navigate to the Getting Started page in ZCC. To navigate to this page, click > .
Each task on this page, includes an icon that indicates the following status:
-
 : the component is successfully configured.
: the component is successfully configured. -
 : the component is ready to be configured.
: the component is ready to be configured. -
 : an error has occurred while configuring the component.
: an error has occurred while configuring the component.
5.2 Monitoring Diagnostics
To monitor the overall health of the Kafka clusters, you need to navigate to the Diagnostics page in ZCC. To navigate to the diagnostics page in ZCC, click in the left pane of ZCC.
The statuses displayed are as follows:
 Up: indicates that all servers are up.
Up: indicates that all servers are up.
 Down: if at least one server is down in the zone, then based on the replication count the relevant status is displayed. For example, the status is displayed as down if at least one server is down in a three node cluster with replication count being 1.
Down: if at least one server is down in the zone, then based on the replication count the relevant status is displayed. For example, the status is displayed as down if at least one server is down in a three node cluster with replication count being 1.
 Warning: if at least one server is down in the zone, then based on the replication factor the relevant status is displayed. For example, the status is displayed as warning if at least one server is down in a three node cluster with replication factor being 2.
Warning: if at least one server is down in the zone, then based on the replication factor the relevant status is displayed. For example, the status is displayed as warning if at least one server is down in a three node cluster with replication factor being 2.
For the Kafka Cluster, the status of the Kafka Brokers, Kafka Connect and the Schema registry are also displayed.
For debugging issues related to the Kafka cluster, see Debugging Issues and Log Locations
NOTE:If client authentication is not enabled for external CA certificates, then the Data Sync Status and Kafka Cluster status will display correct values only if the Diagnostics page is accessed from a server in which the Kafka role is enabled.