2.1 Datensynchronisierung
Die Datensynchronisierung bildet die Grundlage für die Automatisierung von Geschäftsprozessen. In ihrer einfachsten Form ist die Datensynchronisierung die Weitergabe von Daten von dem Speicherort, an dem ein Datenelement geändert wird, an andere Speicherorte, an denen es benötigt wird. Wenn beispielsweise die Telefonnummer eines Mitarbeiters im Personalsystem einer Firma geändert wird, wird die Änderung idealerweise automatisch in allen anderen Systemen übernommen, in denen die Telefonnummer gespeichert ist.
Die Funktionen von Identity Manager gehen über die Synchronisierung von Identitätsdaten hinaus. Identity Manager kann alle Arten von Daten synchronisieren, die in der verbundenen Anwendung oder im Identitätsdepot gespeichert sind.
Die Datensynchronisierung wird einschließlich der Passwortsynchronisierung durch die fünf Basiskomponenten der Identity Manager-Lösung ermöglicht: das Identitätsdepot, die Metaverzeichnis-Engine, die Treiber, der Remote Loader und die verbundenen Anwendungen. Diese Komponenten sind im folgenden Diagramm abgebildet.
Abbildung 2-2 Identity Manager-Architekturkomponenten
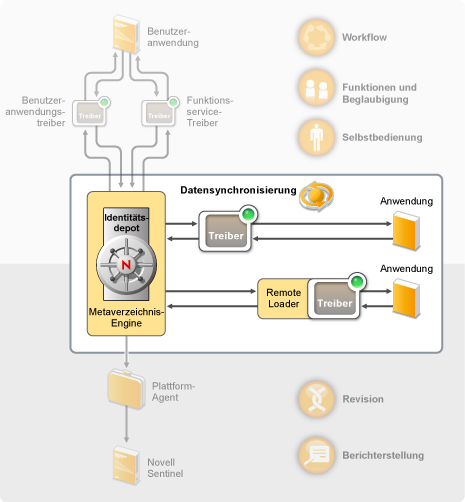
In den folgenden Abschnitten finden Sie Beschreibungen dieser Komponenten und Erläuterungen der Konzepte, die Sie verstehen sollten, um in Ihrer Organisation eine erfolgreiche Datensynchronisierung zwischen verschiedenen Systemen durchführen zu können:
2.1.1 Komponenten
Identitätsdepot: Das Identitätsdepot dient als Metaverzeichnis der Daten, die zwischen Anwendungen synchronisiert werden sollen. Zum Beispiel werden Daten, die von einem PeopleSoft-System nach Lotus Notes synchronisiert werden, zuerst zum Identitätsdepot hinzugefügt, bevor sie an das Lotus Notes-System gesendet werden. Außerdem werden im Identitätsdepot Identity Manager-spezifische Informationen gespeichert, z. B. Treiberkonfigurationen, Parameter und Richtlinien. Für das Identitätsdepot wird Novell eDirectory™ verwendet.
Metaverzeichnis-Engine: Wenn im Identitätsdepot oder in einer verbundenen Anwendung Daten geändert werden, verarbeitet die Metaverzeichnis-Engine die Änderungen. Bei Ereignissen, die im Identitätsdepot auftreten, verarbeitet die Engine die Änderungen und sendet über den Treiber Befehle an die Anwendung. Bei Ereignissen, die in der Anwendung auftreten, empfängt die Engine die Änderungen vom Treiber, verarbeitet diese und sendet Befehle an das Identitätsdepot. Die Metaverzeichnis-Engine wird auch als Identity Manager-Engine bezeichnet.
Treiber: Treiber stellen eine Verbindung zu den Anwendungen her, deren Identitätsinformationen Sie verwalten möchten. Ein Treiber hat zwei grundlegene Aufgaben: 1) das Melden von Datenänderungen (Ereignissen) in der Anwendung an die Metaverzeichnis-Engine sowie 2) das Ausführen von Datenänderungen (Befehlen), die von der Metaverzeichnis-Engine an die Anwendung gesendet werden.
Remote Loader: Die Treiber müssen auf demselben Server installiert und ausgeführt werden wie die Anwendung, zu der sie eine Verbindung herstellen. Wenn sich die Anwendung auf demselben Server wie die Metaverzeichnis-Engine befindet, müssen Sie lediglich den Treiber auf diesem Server installieren. Befindet sich die Anwendung jedoch nicht auf demselben Server wie die Metaverzeichnis-Engine (d. h. sie ist bezogen auf den Engine-Server remote, nicht lokal), müssen Sie den Treiber und den Remote Loader auf dem Server der Anwendung installieren. Der Remote Loader lädt den Treiber und kommuniziert an dessen Stelle mit der Metaverzeichnis-Engine.
Anwendung: Ein System, ein Verzeichnis, eine Datenbank oder ein Betriebssystem, zu dem der Treiber eine Verbindung herstellt. Die Anwendung muss APIs enthalten, die ein Treiber zum Ermitteln und Ausführen von Anwendungsdatenänderungen verwenden kann. Anwendungen werden häufig als verbundene Systeme bezeichnet.
2.1.2 Wichtige Konzepte
Kanäle: Der Datenfluss zwischen dem Identitätsdepot und einem verbundenen System erfolgt durch zwei separate Kanäle. Der Abonnentenkanal ermöglicht den Datenfluss vom Identitätsdepot zu einem verbundenen System. Anders ausgedrückt, das verbundene System abonniert Daten aus dem Identitätsdepot. Der Herausgeberkanal ermöglicht den Datenfluss von einem verbundenen System zum Identitätsdepot. Anders ausgedrückt, das verbundene System veröffentlicht Daten im Identitätsdepot.
Darstellung von Daten: Daten fließen als XML-Dokumente durch einen Kanal. Ein XML-Dokument wird erstellt, wenn eine Änderung im Identitätsdepot oder im verbundenen System auftritt. Das XML-Dokument wird an die Metaverzeichnis-Engine übergeben, die es mit den Filtern und Richtlinien verarbeitet, die dem Kanal des Treibers zugewiesen sind. Nachdem das XML-Dokument vollständig verarbeitet wurde, initiiert die Metaverzeichnis-Engine mithilfe des Dokuments die entsprechenden Änderungen im Identitätsdepot (Herausgeberkanal) bzw. der Treiber initiiert die entsprechenden Änderungen im verbundenen System (Abonnentenkanal).
Datenmanipulation: Wenn ein XML-Dokument durch einen Treiberkanal fließt, wirken sich die dem Kanal zugewiesenen Richtlinien auf die Dokumentdaten aus.
Richtlinien werden für viele Zwecke eingesetzt, z. B. zum Ändern von Datenformaten, zum Zuordnen von Attributen zwischen dem Identitätsdepot und dem verbundenen System, zum bedingungsabhängigen Blockieren des Datenflusses, zum Generieren von Email-Benachrichtigungen und zum Bearbeiten des Datenänderungstyps.
Steuerung des Datenflusses: Filter bzw. Filterrichtlinien steuern den Datenfluss. Filter geben an, welche Datenelemente zwischen dem Identitätsdepot und einem verbundenen System synchronisiert werden. Zum Beispiel werden Benutzerdaten in der Regel zwischen Systemen synchronisiert. Deshalb sind die Benutzerdaten bei den meisten verbundenen Systemen im Filter aufgelistet. Drucker hingegen sind üblicherweise für die meisten Anwendungen nicht von Interesse, daher sind Druckerdaten bei den meisten verbundenen Systemen nicht im Filter aufgeführt.
Bei jeder Beziehung zwischen dem Identitätsdepot und einem verbundenen System sind zwei Filter vorhanden: ein Filter im Abonnentenkanal, der den Datenfluss vom Identitätsdepot zum verbundenen System steuert, und ein Filter im Herausgeberkanal, der den Datenfluss vom verbundenen System zum Identitätsdepot steuert.
Autorisierte Quellen: Die meisten identitätsbezogenen Datenelemente haben einen konzeptionellen Eigentümer. Der Eigentümer eines Datenelements wird als autorisierte Quelle für das Element angesehen. In der Regel darf nur die autorisierte Quelle eines Datenelements Änderungen an dem Datenelement vornehmen.
Zum Beispiel wird das Email-System eines Unternehmens im Allgemeinen als autorisierte Quelle für die Email-Adresse eines Mitarbeiters betrachtet. Wenn ein Administrator des White Pages-Verzeichnis des Unternehmens die Email-Adresse eines Mitarbeiters in diesem System ändert, hat die Änderung keine Auswirkung darauf, ob der Mitarbeiter tatsächlich an die geänderte Adresse gesendete Emails empfängt, da die Änderung im Email-System erfolgen muss, damit sie wirksam ist.
Identity Manager legt autorisierte Quellen für ein Element mithilfe von Filtern fest. Wenn beispielsweise der Filter für die Beziehung zwischen dem PBX-System und dem Identitätsdepot zulässt, dass die Telefonnummer eines Mitarbeiters vom PBX-System in das Identitätsdepot, jedoch nicht vom Identitätsdepot zum PBX-System fließt, ist das PBX-System die autorisierte Quelle für die Telefonnummer. Wenn alle anderen Beziehungen verbundener Systeme zulassen, dass die Telefonnummer vom Identitätsdepot zu den verbundenen Systemen fließt, jedoch nicht in die umgekehrte Richtung, bedeutet dies, dass das PBX-System die einzige autorisierte Quelle für Telefonnummern von Mitarbeitern im Unternehmen ist.
Automatisierte Bereitstellung: Automatisierte Bereitstellung bedeutet, dass Identity Manager neben der reinen Synchronisierung von Datenelementen auch andere Benutzerbereitstellungsaktionen generieren kann.
Zum Beispiel wird in einem typischen Identity Manager-System, bei dem die Personaldatenbank die autorisierte Quelle für die meisten Mitarbeiterdaten ist, durch das Hinzufügen eines Mitarbeiters zur Personaldatenbank die automatische Erstellung eines entsprechenden Kontos im Identitätsdepot veranlasst. Die Erstellung des Kontos im Identitätsdepot veranlasst wiederum die automatische Erstellung eines Email-Kontos für den Mitarbeiter im Email-System. Die zur Bereitstellung des Kontos im Email-System verwendeten Daten werden aus dem Identitätsdepot abgerufen und können den Namen des Mitarbeiters, den Standort, die Telefonnummer usw. umfassen.
Die automatische Bereitstellung von Konten, Zugriffsrechten und Daten kann auf verschiedene Weisen gesteuert werden:
-
Datenelementwerte: Die automatische Erstellung eines Kontos in den Zugriffsdatenbanken für verschiedene Gebäude kann beispielsweise durch einen Wert im Standortattribut eines Mitarbeiters gesteuert werden.
-
Genehmigungsworkflows: Die Erstellung eines Mitarbeiters in der Finanzabteilung kann beispielsweise eine automatische Email an den Abteilungsleiter mit der Anforderung einer Genehmigung für ein neues Mitarbeiterkonto im Finanzsystem veranlassen. Der Abteilungsleiter wird über die Email auf eine Webseite geleitet, auf der er die Anforderung genehmigen oder ablehnen kann. Die Genehmigung kann dann die automatische Erstellung eines Kontos für den Mitarbeiter im Finanzsystem veranlassen.
-
Rollenzuweisungen: Ein Mitarbeiter erhält beispielsweise die Rolle „Buchhalter“. Identity Manager stellt für den Mitarbeiter alle Konten, Zugriffsrechte und Daten bereit, die der Rolle „Buchhalter“ zugewiesen sind. Dies erfolgt über Systemworkflows (ohne menschliches Eingreifen), von Mitarbeitern durchgeführte Genehmigungsabläufe oder eine Kombination aus beidem.
Berechtigungen: Eine Berechtigung repräsentiert eine Ressource in einem verbundenen System, beispielsweise ein Konto oder eine Gruppenmitgliedschaft. Wenn ein Benutzer die Kriterien erfüllt, die für eine Berechtigung in einem verbundenen System festgelegt wurden, verarbeitet Identity Manager ein Ereignis für den Benutzer, mit dem Ergebnis, dass dem Benutzer Zugriff auf die Ressource gewährt wird. Dies erfordert natürlich, dass alle Richtlinien wirksam sind, damit der Zugriff auf die Ressource möglich ist. Wenn zum Beispiel ein Benutzer die Kriterien für ein Exchange-Konto in Active Directory erfüllt, verarbeitet die Metaverzeichnis-Engine den Benutzer mit den Active Directory-Treiberrichtlinien, die ein Exchange-Konto bereitstellen.
Der Hauptnutzen von Berechtigungen besteht darin, dass Sie die Geschäftslogik für den Zugriff auf eine Ressource in einer Berechtigung statt in mehreren Treiberrichtlinien definieren können. Zum Beispiel können Sie eine Kontoberechtigung definieren, die einem Benutzer in vier verbundenen Systemen ein Konto zur Verfügung stellt. Die Entscheidung, ob für den Benutzer ein Konto bereitgestellt werden soll, wird durch die Berechtigung getroffen, was bedeutet, dass die Richtlinien für die einzelnen vier Treiber die Geschäftslogik nicht enthalten müssen. Stattdessen müssen die Richtlinien nur den Mechanismus für die Gewährung des Kontos liefern. Wenn Sie eine Änderung an der Geschäftslogik vornehmen müssen, führen Sie dies in der Berechtigung aus und nicht in den einzelnen Treibern.
Aufträge: Die meisten Aktionen, die Identity Manager ausführt, erfolgen als Reaktion auf Datenänderungen oder Benutzeranforderungen. Wenn beispielsweise Daten in einem System geändert werden, ändert Identity Manager die entsprechenden Daten in einem anderen System. Wenn ein Benutzer Zugriff auf ein System anfordert, initiiert Identity Manager die entsprechenden Prozesse (Workflows, Ressourcenbereitstellung usw.) für die Gewährung des Zugriffs.
Aufträge ermöglichen Identity Manager das Ausführen von Aktionen, die nicht durch Datenänderungen oder Benutzeranforderungen initiiert werden. Ein Auftrag besteht aus Konfigurationsdaten, die im Identitätsdepot gespeichert sind, und einem entsprechenden Implementierungscode. Identity Manager enthält vordefinierte Aufträge, die Aktionen wie das Starten oder Anhalten von Treibern, das Senden von Email-Benachrichtigungen über ablaufende Passwörter und das Prüfen des Zustands von Treibern ausführen. Sie können auch benutzerdefinierte Aufträge zur Durchführung weiterer Aktionen implementieren. Für einen benutzerdefinierten Auftrag müssen Sie (bzw. ein Entwickler oder Berater) den für die Durchführung der gewünschten Aktionen erforderlichen Code erstellen.
Aufträge: In der Regel werden Änderungen an Daten im Identitätsdepot oder in einer verbundenen Anwendung sofort verarbeitet. Mithilfe von Aufträgen können Sie Aufgaben planen, die an einem bestimmten Datum und zu einer bestimmten Uhrzeit ausgeführt werden sollen. Zum Beispiel wird ein neuer Mitarbeiter eingestellt, der jedoch erst im nächsten Monat bei dem Unternehmen anfängt. Der Mitarbeiter muss zur Personaldatenbank hinzugefügt werden, er soll jedoch erst ab seinem ersten Arbeitstag Zugriff auf die Ressourcen des Unternehmens (Email, Server usw.) erhalten. Ohne die Verwendung eines Auftrags würde der Benutzer den Zugriff sofort erhalten. Wenn Aufträge implementiert sind, wird ein Auftrag erstellt, der die Kontobereitstellung erst am ersten Arbeitstag des Mitarbeiters initiiert.