75.2 CIM-Schema
Die Elemente des Meta-Schemas sind Klassen, Eigenschaften und Methoden. Das Meta-Schema unterstützt außerdem Bezeichnungen und Verknüpfungen als Klassentypen und Verweise als Eigenschaftstypen.
Klassen können in einer Verallgemeinerungshierarchie angeordnet werden, die Teiltypbeziehungen zwischen Klassen darstellt. Die Verallgemeinerungshierarchie ist ein zielgerichtetes Diagramm auf Stammbasis, das keine Mehrfachvererbung unterstützt.
Eine reguläre Klasse enthält möglicherweise Skalar- oder Array-Eigenschaften eines beliebigen spezifischen Typs, beispielsweise "Boolesch", "Ganzzahl" und "Zeichenkette". Sie kann keine eingebetteten Klassen oder Verweise auf andere Klassen enthalten.
Eine Verknüpfung ist eine spezielle Klasse, die mehrere Verweise enthält. Sie stellt eine Beziehung zwischen mehreren Objekten dar. Aufgrund der Art der Definition von Verknüpfungen kann eine Beziehung zwischen Klassen eingerichtet werden, ohne dass eine der verwandten Klassen davon betroffen ist. Dies bedeutet, dass eine zusätzliche Verknüpfung die Schnittstelle der verwandten Klassen nicht betrifft. Nur Verknüpfungen können Verweise haben.
Das Schemafragment in folgender Abbildung zeigt die Beziehungen zwischen einigen CIM-Objekten, die von ZENworks 7 Desktop Management verwendet werden.

Die Abbildung zeigt, wie das CIM-Schema einem relationalen DBMS-Schema zugeordnet wird. Die Klassen werden mit dem Klassennamen als Feldüberschrift angezeigt. Die Verknüpfungen werden innerhalb der Linien zwischen zwei Klassen beschrieben.
Die Vererbungshierarchie dieses Schemafragments wird in folgender Abbildung des CIM 2.2-Schemas dargestellt. Die Verweise vom Typ "Ref" sind fett ausgezeichnet. Jeder Teiltyp einer Verknüpfung schränkt dabei den Typ des Verweises ein.
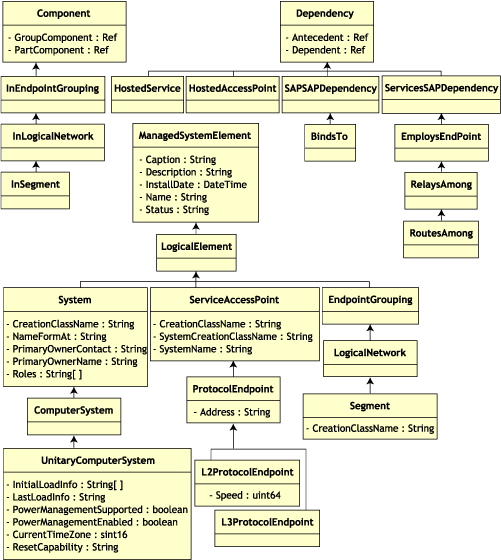
75.2.1 Zuordnung von CIM zum relationalen Schema
CIM ist ein Objektmodell mit Klassen, Vererbung und Polymorphismus. Die erzeugte Zuordnung zu einem relationalen Schema behält diese Funktionen in vollem Umfang bei. Die folgenden zwei Aspekte sind Bestandteil der relationalen Zuordnung:
-
Logisches Schema: Das logische Schema definiert, wie die Daten zu Anwendungen (vergleichbar mit einer API) angezeigt werden. Das Ziel ist, dass das logische Schema ungeachtet der zugrunde liegenden Datenbank das gleiche bleibt, damit die Anwendungssoftware unverändert auf jeder unterstützten Datenbank ausgeführt werden kann. Obwohl SQL der Standard ist, kann dieses Ziel nicht vollständig erreicht werden. Der Anwendungssoftware müssen weitere Informationen zur verwendeten Datenbank vorliegen. Diese Informationen können abstrahiert und in einem kleinen Bereich des Anwendungscode isoliert werden.
-
Physisches Schema: Das physische Schema definiert, wie die Daten in der Datenbank strukturiert werden. Das Schema ist wegen der Struktur von SQL und RDBMS spezifisch für eine Datenbank. In diesem Dokument wird das physische Schema nur allgemein beschrieben.
Eine Tabelle in der Datenbank stellt jede Klasse in der CIM-Hierarchie dar. Eine Spalte des entsprechenden Typs in der Tabelle stellt jede nicht vererbte Eigenschaft in der Klasse dar. Jede Tabelle hat außerdem einen Primärschlüssel, "id$". Hierbei handelt es sich um eine 64-Bit-Ganzzahl, die eine Instanz eindeutig bezeichnet. Eine Instanz einer CIM-Klasse wird durch eine Zeile in jeder Tabelle dargestellt, die einer Klasse in der jeweiligen Vererbungshierarchie entspricht. Jede Zeile hat den gleichen Wert für "id$".
Jede CIM-Klasse wird außerdem durch eine Ansicht dargestellt, die "id$" verwendet, um Zeilen aus den verschiedenen Tabellen in der Vererbungshierarchie miteinander zu verbinden. So ergibt sich eine Zusammensetzung der Eigenschaften (vererbte und lokale) für eine Instanz dieser Klasse. Die Ansicht enthält außerdem eine zusätzliche Spalte, "class$" vom Typ "Ganzzahl", die den Typ der tatsächlichen Klasse (ohne übergeordnete Elemente) der Instanz darstellt.
Verknüpfungen werden auf die gleiche Art und Weise zugeordnet wie reguläre Klassen, und zwar mit einer Verweiseigenschaft, die von einer Spalte mit dem Feld "id$" der referenzierten Objektinstanz dargestellt wird. Somit können Verknüpfungen verbunden werden, indem eine Verbindung zwischen dem Verweisfeld in der Verknüpfung und dem Feld "id$" in der referenzierten Tabelle erstellt wird.
Die folgende Abbildung veranschaulicht eine Standardabfrage mit dieser Zuordnung:
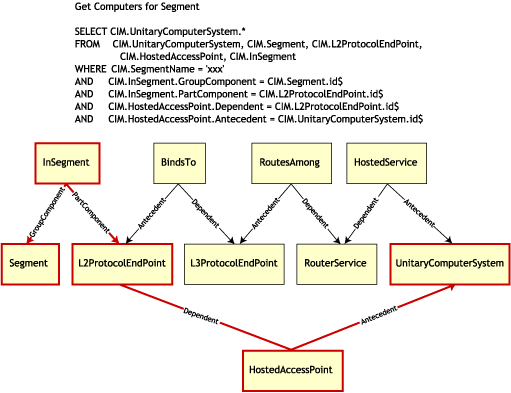
Diese Abfrage sucht alle Computer, die mit einem bestimmten Netzwerksegment verbunden sind. Die betreffenden Klassen und Beziehungen werden durch Rahmen hervorgehoben.
Folgende Themen beschreiben die beiden Schematypen:
75.2.2 Logisches Schema
Das logische Schema ist das Datenbankschema, das von den Benutzern der Datenbank und dem Anwendungsprogramm angezeigt werden kann. Das Schema besteht aus gespeicherten Prozeduren und Ansichten. Die zugrunde liegenden Tabellen können von der Anwendung nicht angezeigt werden.
ZENworks 7 Desktop Management-Inventarkomponenten verwenden JDBC, um SQL-Anweisungen in den RDBMS auszuführen und RDBMS-Datentypen in Java-Datentypen umzuwandeln (und umgekehrt). Die Verwendung von JDBC mit gespeicherten Prozeduren und Ansichten bietet eine Abstraktionsebene, die den Anwendungscode von der zugrunde liegenden Datenbank-Technologie sowie Änderungen des physischen Schemas isoliert.
Die verschiedenen Elemente des logischen Schemas werden in folgenden Abschnitten detailliert behandelt:
Benennung von Schema-Elementen
Es wird empfohlen, die unveränderten CIM-Namen im Datenbankschema zu verwenden. Aufgrund der unterschiedlichen Benennungsschemas können beispielsweise folgende Probleme auftreten:
- Bei den Namen in CIM und SQL wird die Groß-/Kleinschreibung nicht berücksichtigt.
- Alle Datenbanken haben bestimmte reservierte Wortgruppen, die in Anführungszeichen (“ “) eingeschlossen werden müssen, wenn sie als Schema-Elementnamen verwendet werden. In Oracle wird jedoch bei in Anführungszeichen gesetzten Elementen die Groß-/Kleinschreibung beachtet.
- CIM-Klassen vermeiden es, Wörter als Namen zu verwenden, die für SQL reserviert sind.
- CIM-Namen sind in der Länge unbegrenzt und in der Regel lang. Sybase ermöglicht bis zu 128 Zeichen, Oracle hingegen schränkt die Namen auf 30 Zeichen ein.
Die meisten dieser Probleme werden während der Schema-Erstellung folgendermaßen vermieden: Die Groß-/Kleinschreibung von CIM-Namen wird beibehalten, Namen mit mehr als 30 Zeichen werden abgekürzt und alle Namen, die ein Teil der reservierten Wortgruppen sind, werden in Anführungszeichen (" ") eingeschlossen.
Jeder Name mit mehr als 28 Zeichen wird auf einen Stammnamen von höchstens 28 Zeichen abgekürzt, um ein Präfix von zwei Zeichen zuzulassen. Auf diese Weise können alle verknüpften SQL-Schema-Elemente den gleichen Stammnamen verwenden. Der Abkürzungsalgorithmus verkürzt einen Namen, damit dieser mnemonisch, erkennbar und außerdem innerhalb des Bereichs eindeutig ist. Der abgekürzte Name erhält das #-Zeichen als Suffix, um Konflikte mit anderen Namen zu vermeiden. Beachten Sie aber, dass das #-Zeichen in CIM nicht zulässig ist. Wenn bei mehreren Namen innerhalb des gleichen Bereichs die gleiche Abkürzung entsteht, wird eine zusätzliche Stelle angehängt, damit der Name eindeutig wird. Beispiel: AttributeCachingForRegularFilesMin wird abgekürzt auf AttCacForRegularFilesMin#.
Alle abgekürzten Namen werden in die Tabelle der abgekürzten Namen geschrieben, damit ein Programm den echten CIM-Namen ermitteln und den abgekürzten Namen abrufen kann, der mit SQL verwendet wird.
Ansichten sind die Schema-Elemente, die am häufigsten durch Anwendungscode und Abfragen beeinflusst werden. Sie verwenden den gleichen Namen wie die CIM-Klasse, die sie darstellen. Die Klasse CIM.UnitaryComputerSystem wird beispielsweise durch eine Ansicht namens CIM.UnitaryComputerSystem dargestellt.
Gegebenenfalls werden Namen für Indizes und Hilfstabellen erstellt, indem der Klassenname und der Eigenschaftsname (getrennt durch ein $-Zeichen) verknüpft werden. Diese Namen werden in der Regel abgekürzt. Beispiel: NetworkAdapter$NetworkAddresses wird abgekürzt auf NetAdapter$NetAddresses#. Dies wirkt sich nicht nachteilig auf Benutzer des ZENworks 7 Desktop Management-Schemas aus.
Benutzer und Funktionen
In SQL ist ein Benutzer mit dem gleichen Namen wie das Schema der Eigentümer des jeweiligen Schemas, beispielsweise CIM, ManageWise®, ZENworks und andere.
Außerdem gibt es einen MW_DBA-Benutzer, der Datenbank-Verwalterrechte für alle Schema-Objekte hat. Die Funktion MW_Reader hat Nur-Lese-Zugriff auf alle Schema-Objekte und die Funktion MW_Updater hat Lese-/Schreib-Zugriff auf alle Schema-Objekte.
Anwendungsprogramme sollten (abhängig von den jeweiligen Anforderungen) folgendermaßen auf die Datenbank zugreifen: als MW_Reader oder MW_Updater für eine Sybase-Datenbank, MWO_Reader oder MWO_Updater für eine Oracle-Datenbank und als MWM_Reader oder MWM_Updater für eine Datenbank auf MS SQL Server.
Datentypen
CIM-Datentypen werden dem geeignetsten Datentyp zugeordnet, der in der Datenbank enthalten ist. In der Regel erfordert die Java-Anwendung den Typ nicht, da sie JDBC für den Zugriff auf die Daten verwendet.
Java unterstützt keine nicht signierten Typen. Sie sollten also Klassen oder Ganzzahlen der nächsten Größe verwenden, um sie darzustellen. Stellen Sie außerdem sicher, dass beim Lesen oder Schreiben in der Datenbank keine Probleme auftreten. Das Lesen oder Schreiben einer negativen Zahl in einem nicht signierten Feld in der Datenbank kann beispielsweise einen Fehler verursachen.
Zeichenketten in CIM und Java sind Unicode, demnach wird die Datenbank mit dem UTF-8-Zeichensatz erstellt. Durch die Globalisierung treten keine Probleme auf. Dennoch können in Abfragen Probleme mit der Groß-/Kleinschreibung entstehen.
Alle Datenbanken behalten die gespeicherte Schreibweise der Zeichenketten bei. Beim Zugriff auf die Daten während Abfragen wird aber möglicherweise die Groß-/Kleinschreibung nicht beachtet. In ZENworks 7 Desktop Management sind die Komponenten der Inventarabfrage und des Datenexports nicht betroffen, da die abgefragten Daten aus der Datenbank abgerufen werden, bevor sie abgefragt werden, und so automatisch die Groß-/Kleinschreibung beachtet wird.
In CIM werden Zeichenketten möglicherweise mit oder ohne eine maximale Zeichengröße angegeben. Viele Zeichenketten haben keine angegebene Größe, das bedeutet, dass die Größe unbegrenzt sein kann. Aus Gründen der Effizienz werden diese unbegrenzten Zeichenketten einer variablen Zeichenkette mit einer Maximalgröße von 254 Zeichen zugeordnet. CIM-Zeichenketten mit einer Maximalgröße werden variablen Datenbank-Zeichenketten der gleichen Größe zugeordnet. Die Größe in der Datenbank wird in Byte und nicht als Zeichen angegeben, da ein Unicode-Zeichen für das Speichern möglicherweise mehr als ein Byte benötigt.
Ansichten
Jede CIM-Klasse wird in der Datenbank durch eine Ansicht dargestellt, die alle lokalen und vererbten Non-Array-Eigenschaften dieser Klasse enthält. Diese Ansicht erhält die gleiche Bezeichnung wie die CIM-Klasse.
Ansichten können mit einer SELECT-Anweisung abgefragt und mit einer UPDATE-Anweisung aktualisiert werden. Da Ansichten nicht mit den INSERT- und DELETE-Anweisungen verwendet werden können, verwenden Sie die Konstruktor- und Destruktor-Prozeduren.
75.2.3 Physisches Schema
Das physische Schema umfasst Elemente, die für das Implementieren der Datenbank benötigt werden. Das physische Schema ist bei jeder Datenbank unterschiedlich. Standardmäßig besteht ein physisches Schema aus folgenden Elementen:
- Tabellen-Definitionen ’t$xxx’Index-Definitionen ’i$xxx’
- Trigger-Definitionen ’x$xxx’, ’n$xxx’ und ’u$xxx’
- Sequenz-Definitionen (Oracle) ’s$xxx’
- Gespeicherte Prozeduren und Funktionen
Das logische Schema befindet sich in der obersten Ebene des physischen Schemas. Benutzer und Anwendungen müssen das physische Schema nicht kennen.