2.2 Cluster Services NLMs
The installation process installs the following NetWare Cluster Services NetWare Loadable Module™ (NLM™) programs on each network server in the cluster:
Figure 2-2 Novell Cluster Services NLMs
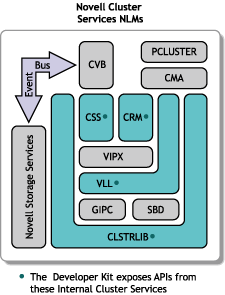
2.2.1 Cluster Configuration Library
The cluster configuration library (CLSTRLIB.NLM) provides the interface between NCS and eDirectory. The cluster configuration library (running on the master node) uses eDirectory to access all cluster configuration information, including the cluster attributes, protocols, properties, policies, and settings. The master node then stores this information in its local internal memory so that the NCS NLMs located on the node can correctly perform their operations in accordance with the eDirectory settings.
Additionally, the master node transmits this information to all nodes in the cluster so that each has its own copy. As changes are made to the cluster settings in eDirectory, the cluster configuration library accesses these modifications, updating its local version of the information (as well as the versions stored locally on the other nodes in the cluster).
2.2.2 Group Membership Protocols
The group interprocess protocol (GIPC—pronounced “gypsy”) NLM tracks cluster membership changes. In essence, GIPC runs the cluster's group membership protocols. Events that affect group membership include a node joining the cluster or nodes leaving the cluster (due to node failure or planned departure).
To handle the group membership protocols, GIPC runs the following set of micro-protocols on the cluster master node:
-
Panning—Filters messages to the current epoch
-
Heartbeat—Generates point-to-point “heartbeat” messages (see Heartbeat Settings in Section 2.1.1, Cluster Container).
-
Sequencer—Enforces sequencing of multicasts and membership changes
-
Membership—Maintains “stable” membership information
-
Censustaker—Generates unstable membership reports by monitoring heartbeat messages
-
Group Anchor—Communicates group membership information to the slave nodes in the upper layer modules
Once a cluster is activated, the cluster master node uses the GIPC protocols to keep an accurate account of which nodes are currently part of the cluster. The membership protocol keeps track of the current cluster membership, whereas the heartbeat protocol generates a sequence of heartbeat messages between the slave nodes in the cluster and the master node. The censustaker monitors the node heartbeat responses to detect nodes joining and leaving the cluster.
The censustaker protocol sometimes generates a report to the membership protocol describing its understanding of the current membership status. For example, if the censustaker does not receive a heartbeat message from one of the nodes (before the time expires as specified in the Tolerance setting), the censustaker protocol issues a report stating that the node has left the cluster. This report is considered unstable until all nodes in the cluster have accepted it.
The membership protocol uses the censustaker and sequencer protocols to reach an agreement between all of the nodes on this membership view. The group anchor protocol communicates theses status events to the upper layer modules. The sequencer protocol ensures that each node receives these event notifications, and that each node receives them in the same order.
The sequencer protocol does this in such a way to ensure that all nodes in the cluster have the exact same understanding of the cluster membership. Once the nodes agree on the proposed membership status, the proposed membership view is accepted as actual.
If for some reason the master node fails during this process, a new master is elected to sequence these events and ensure an accurate view of the cluster membership.
2.2.3 Split-Brain Detector
If nodes in the cluster become isolated from each other such that they can no longer communicate with one another over the LAN, a split-brain scenario can occur in clustered systems that use shared disk subsystems, as discussed in Section 1.1.5, Split Brain Detection. For example, if an Ethernet switch fails between nodes in the cluster, nodes on opposite sides of the switch no longer are able to detect each other. Each side of the cluster assumes that nodes on the other side of the switch have failed and tries to activate their resources.
As a result, each side tries to load the other side's applications and to mount their data volumes, causing data corruption. As part of its membership protocols, NetWare Cluster Services uses its Split Brain Detector (SBD) to make sure that split-brain conditions are detected and dealt with properly so that no data corruption can occur.
The SBD relies on the clustered node connection to the shared disks as an alternate communication channel. NCS creates a special dedicated partition on the shared disk that contains a history of each node's view of the cluster membership.
Each node in the cluster has its own portion of this partition where it records its version of the cluster membership history. The node has read/write privileges to its section of the partition, but has read rights to only those portions belonging to the other nodes. When a membership change occurs, the SBD examines this partition for any inconsistencies between the membership histories recorded by the different nodes.
The following example illustrates how the SBD resolves a split brain that occurs on a three-node cluster:
-
When all four nodes first join the cluster, they each record in their partition that they are at Epoch 1 with nodes A, B, and C as members.
-
A LAN failure blocks the communications with node C and nodes A and B.
-
The SBD examines the shared partition and sees that nodes A and B have both recorded in their partition spaces that they are now at Epoch 2 with nodes A and B as members. Node C has recorded in its partition space that it is also at Epoch 2 with node C as the only member. The SBD determines that this is a split-brain condition because nodes A, B, and C are all at Epoch 2, but their records do not agree on the membership view of the cluster.
When a split-brain is discovered, the SBD shuts down the nodes on one side of the split-brain. This is necessary to prevent potential data corruption that can occur from the two sides trying to mount each other's volumes and run each other's applications. The SBD initiates a tiebreaker algorithm to determine which nodes to shut down:
-
If one side of the split-brain has fewer active nodes, that side is shut down.
-
If both sides have an equal number of active nodes, the side with the master node remains active.
2.2.4 Cluster Resource Manager
The cluster resource manager (CRM) sits above the group membership protocols making sure that, as membership changes occur, cluster resources run on the correct nodes. The CRM on the master node receives an event notification every time a node joins or leaves the cluster enabling it to properly determine whether to load or unload cluster resources on nodes in the cluster.
The master node CRM acts as an event-driven finite state machine that tracks the real-time status of all resources running on the cluster. The state of these cluster resources is distributed from the master node to all the nodes in the cluster. So, if the master node fails, a CRM on a surviving node can become the new master and manage cluster resources.
The following table depicts the various states that the CRM tracks for the cluster resources:
Table 2-1 Cluster Resource States
|
Resource State |
Description |
|---|---|
|
Unassigned |
Not able to run cluster resource since the resources preferred nodes are not currently members of the cluster. |
|
Offline |
Dormant. Editing of the resource’s properties is now allowed. |
|
Loading |
Currently running the load script to activate the resource. |
|
Unloading |
Currently running the unload script to deactivate the resource. |
|
Comatose |
Failed to complete script before timeout occurred. |
|
Running |
Located and running. |
|
Alert |
Resource currently requires manual intervention. |
|
NDS Sync |
Resource is waiting to synchronize with its eDirectory properties. |
|
Quorum Wait |
Resource is waiting to activate until enough nodes join the cluster to meet Quorum Trigger requirements. (See “Quorum Trigger” in Section 2.1.1, Cluster Container.) |
2.2.5 Virtual Interface Architecture Link Layer
The virtual interface architecture link layer (VLL) serves as an interface layer for several other clustering services modules. The GIPC, SBD, and CRM modules interface in the VLL. If the GIPC module stops receiving information from one of the cluster nodes, it notifies the VLL module. The VLL module then contacts the SBD module, which determines if the node is really dead or not, and then informs the CRM of the decision.
2.2.6 Cluster Volume Broker
The cluster volume broker (CVB) tracks the NSS configuration for the cluster. If a change is made to NSS for one server, the CVB ensures that the change is replicated across all the nodes in the cluster.
2.2.7 Cluster System Services
The cluster system services (CSS) module provides an API that any distributed cluster-aware application can use to enable distributed-shared memory and distributed locking. Distributed-shared memory allows cluster-aware applications running across multiple servers to share access to the same data as though the data were on the same physically-shared RAM chips. Distributed locking protects cluster resources by ensuring that if one thread on one node gets a lock then another thread on another node can't get the same lock.
2.2.8 Cluster Services Management Agent
The cluster management agent (CMA) acts as a proxy for ConsoleOne. It's an asynchronous, proprietary protocol that runs between the cluster and the client workstation running ConsoleOne. The CMA interacts with ConsoleOne to facilitate control of the cluster's current state, to configure the cluster's settings stored in eDirectory, and to display the current state of the cluster.
The CMA interacts with the CRM to determine what cluster nodes are active, and to control the current state of the resources, such as migrating a cluster resources to another node or forcing a node to leave the cluster. It also performs SNMP and SMTP mail on NetWare 6.
2.2.9 Cluster Monitor Utility
The cluster monitor (CMON) is a console utility that runs on each node in the cluster, allowing network administrators to view the status of the cluster's nodes.
NOTE:For network services that are enabled using the Cluster Services Developer Kit (such as GroupWise®, LDAP, etc.), a health monitor object (HMO) can be implemented to ensure that these clustered services remain operating at peak efficiency. If performance falls below set criteria, the HMO results in actions (such as the service being moved to a higher performing alternate server) to retain high availability to users. For more information, see the Section D.0, Health Monitor Object Sample.
2.2.10 Portal Cluster Agent
The Portal Cluster Agent (PCLUSTER) NLM provides the ability to manage clustering services from NetWare Remote Manager. Clustering services can be managed from any computer with a browser and Internet connection. The functionality in Remote Manager is practically identical to the functionality in ConsoleOne.
2.2.11 NDF File Trustee Migration
On NetWare 5.x, the TRUSTMIG NLM migrates the eDirectory trustee rights associated with a cluster-enabled volume of a failed node to the surviving node that remounts that volume. Without this migration, users would no longer be able to access their data and services on that volume once it remounted the new node.
2.2.12 Updated NCP Protocol Engine
The NCS installation process installs two updated NLMs on each node in the cluster. The updated NCPIP NLM provides support on a NetWare server such that cluster-enabled volumes can be tied to virtual NCP servers. It also facilitates transparent, automatic client reconnect by allowing NetWare clients to detect when they have been connected to a cluster.