1.3 Driver Features
1.3.1 Local and Remote Platforms
The driver runs on all platforms supported for Identity Manager 3.6.1, including any local installation (Metadirectory server) or remote installation (Remote Loader). For information about supported platforms for Identity Manager 3.6.1, see System Requirements
in the Identity Manager 3.6.1 Installation Guide.
For information on supported databases, see Database Interoperability.
For information on supported third-party JDBC drivers, see Third-Party JDBC Driver Interoperability.
1.3.2 Entitlements
The JDBC driver does not support entitlements.
1.3.3 Password Synchronization
The JDBC driver supports password set and check on the Subscriber channel. The driver does not support bidirectional password synchronization.
1.3.4 Data Synchronization Models
The JDBC driver supports two data synchronization models: direct and indirect. Both terms are best understood with respect to the final destination of the data being synchronized.
The following sections describe how direct and indirect synchronization work on both the Subscriber and Publisher channels.
Indirect Synchronization
Indirect synchronization uses intermediate staging tables to synchronize data between the Identity Vault and a database.
The following diagrams illustrate how indirect synchronization works on the Subscriber and Publisher channels. In the following scenarios, you can have one or more customer tables and intermediate staging tables.
Subscriber Channel
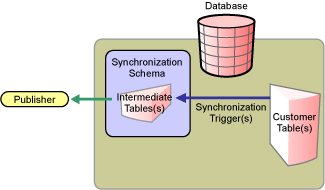
Figure 1-2 Indirect Synchronization on the Subscriber Channel
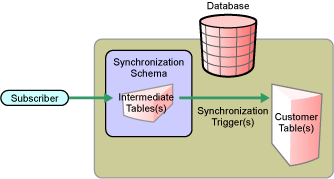
The Subscriber channel updates the intermediate staging tables in the synchronization schema. The synchronization triggers then update customer tables elsewhere in the database.
Publisher Channel
Figure 1-3 Indirect Synchronization on the Publisher Channel
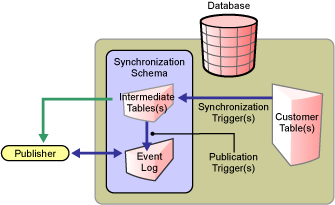
When customer tables are updated, synchronization triggers update the intermediate staging tables. Publication triggers then insert one or more rows into the event log table. The Publisher channel then reads the inserted rows and updates the Identity Vault.
Depending on the contents of the rows read from the event log table, the Publisher channel might need to retrieve additional information from the intermediate tables before updating the Identity Vault. After updating the Identity Vault, the Publisher channel then deletes or marks the rows as processed.
Direct Synchronization
Direct synchronization typically uses views to synchronize data between Identity Manager and a database. You can use tables if they conform to the structure that the JDBC driver requires.
The following diagrams illustrate how direct synchronization works on the Subscriber and Publisher channels. In the following scenarios, you can have one or more customer views or tables.
Subscriber Channel
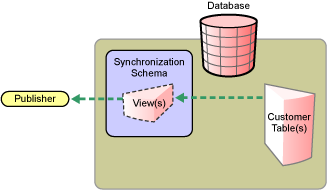
Figure 1-4 Direct Synchronization on the Subscriber Channel
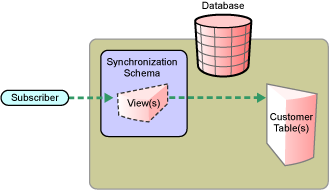
The Subscriber channel updates existing customer tables through a view in the synchronization schema.
Direct synchronization without a view is possible only if customer tables match the structure that the JDBC driver requires. For additional information, see Section 8.3, Indirect Synchronization.
Publisher Channel
Figure 1-5 Direct Synchronization on the Publisher Channel
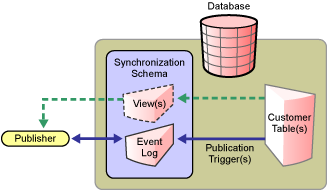
When a customer table is updated, publication triggers insert rows into the event log table. The Publisher channel then reads the inserted rows and updates the Identity Vault.
Depending on the contents of the rows read from the event log table, the Publisher channel might need to retrieve additional information from the view before updating the Identity Vault. After updating the Identity Vault, the Publisher channel then deletes or marks the rows as processed.
1.3.5 Triggerless vs. Triggered Publication
Triggers are not required to log events for the Publisher channel. In situations where triggers cannot be used to capture granular events, the Publisher channel can derive database changes by inspecting database data.
Triggerless publication is particularly useful when support contracts forbid the use of triggers on database application tables or for rapid prototyping.
However, triggerless publication is less efficient than triggered publication. With triggered publication, what changed is already known. With triggerless publication, change calculation must occur before events can be processed.
Triggerless publication, unlike triggered publication, does not preserve event order. It only guarantees that by the end of a polling cycle, objects in the database and the Identity Vault are in sync.
Triggerless publication, unlike triggered publication, does not provide historical data such as old values. It provides information on the current state of an object, not the previous state.
Triggerless publication does have the advantage of being much simpler because it reduces database-side dependencies. Writing database triggers can be complicated and requires extensive knowledge of database-specific SQL syntaxes.
The following figure illustrates direct triggerless publication:
Figure 1-6 Direct Triggerless Publication
The following figure illustrates indirect triggerless publication:
Figure 1-7 Indirect Triggerless Publication
If you move the driver without moving the state files, the driver must build up new state files by resynchronizing. For information on this situation, see State Directory.