1.2 Understanding PlateSpin Orchestrate Functionality
1.2.1 Resource Virtualization
Host machines or test targets managed by the Orchestrate Server form nodes on the grid (sometimes referred to as the matrix). All resources are virtualized for access by maintaining a capabilities database containing extensive information (facts) for each managed resource.
This information is automatically polled and obtained from each resource periodically or when it first comes online. The extent of the resource information the system can gather is customizable and highly extensible, controlled by the jobs you create and deploy.
The PlateSpin Orchestrate Virtual Machine Builder is a service of VM Management that allows you to build a VM to precise specifications required for your data center. You designate the parameters required: processor, memory, hard drive space, operating system, virtualization type, whether it is based on an auto-install file, and any additional parameters. When you lauch the build job, VM Builder sends the build request to a machine that meets the hardware requirements of the defined VM and builds the VM there.
For more information, see Creating a Xen VM
in the PlateSpin Orchestrate 2.0 VM Client Guide and Reference.
1.2.2 Policy-Based Management
Policies are aggregations of facts and constraints that are used to enforce quotas, job queuing, resource restrictions, permissions, and other user and resource functions. Policies can be set on all objects and are inherited, which facilitates implementation within related resources.
Facts, which might be static, dynamic or computed for complex logic, are used when jobs or test scenarios require resources in order to select a resource that exactly matches the requirements of the test, and to control the access and assignment of resources to particular jobs, users, projects, etc. through policies.This abstraction keeps the infrastructure fluid and allows for easy resource substitution.
Of course, direct named access is also possible. An example of a policy that constrains the selection of a resource for a particular job or test is shown in the sample below. Although resource constraints can be applied at the policy level, they can also be described by the job itself or even dynamically composed at runtime.
<policy>
<constraint type="resource">
<and>
<eq fact="resource.os.family" value="Linux"/>
<gt fact="resource.os.version" value="2.2" />
<and>
</constraint>
</policy>
An example of a policy that constrains the start of a job or test because too many tests are already in progress is shown in the following sample:
<policy>
<!-- Constrains the job to limit the number of running jobs to a
defined value but exempt certain users from this limit. All jobs
that attempt to exceed the limit are qued until the running jobs
count decreases and the constraint passes. -->
<constraint type="start" reason="Too busy">
<or>
<lt fact="job.instances.active" value="5"/>
<eq fact="user.name" value="canary" />
</or>
</constraint>
</policy>
1.2.3 Grid Object Visualization
One of the greatest strengths of the PlateSpin Orchestrate solution is the ability to manage and visualize the entire grid. This is performed through the PlateSpin Orchestrate Development Clientand the PlateSpin Orchestrate VM Monitoring System.
The desktop Development Client is a Java application that has broad platform support and provides job, resource, and user views of activity as well as access to the historical audit database system, cost accounting, and other graphing features.
The Development Client also applies policies that govern the use of shared infrastructure or simply create logical grouping of nodes on the grid. For more information about the PlateSpin Orchestrate Development Client, see the PlateSpin Orchestrate 2.0 Development Client Reference.
The PlateSpine Orchestrate VM Monitoring System provides robust graphical monitoring of all managed virtual resources managed on the grid.
Figure 1-8 PlateSpin Orchestrate Monitoring in the VM Client
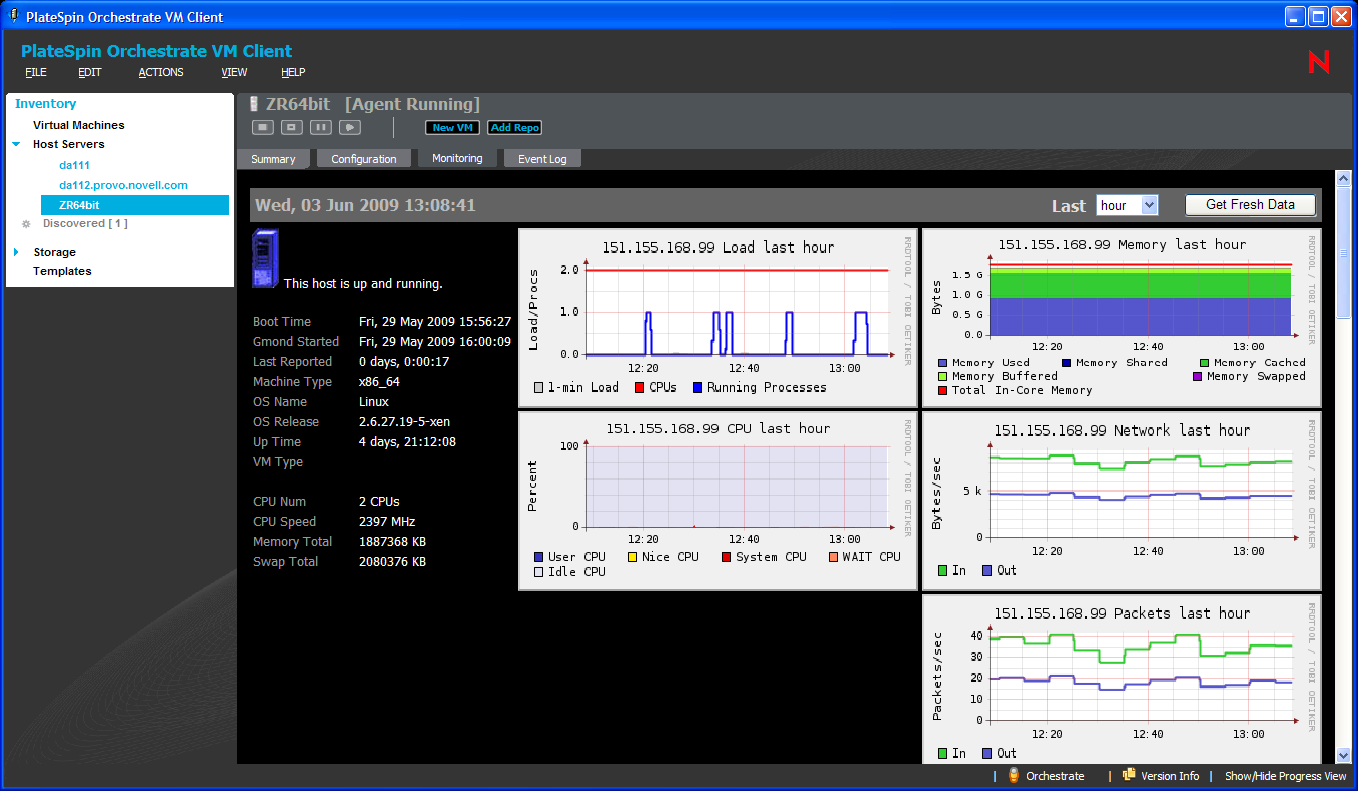
For more information, see the PlateSpin Orchestrate 2.0 VM Client Guide and Reference.
1.2.4 Understanding Job Semantics
As mentioned earlier, PlateSpin Orchestrate runs jobs. A job is a container that can encapsulate several components including the Python-based logic for controlling the job life cycle (such as a test) through logic that accompanies any remote activity, task-related resources such as configuration files, binaries and any policies that should be associated with the job, as illustrated below.
Figure 1-9 Components of a Job
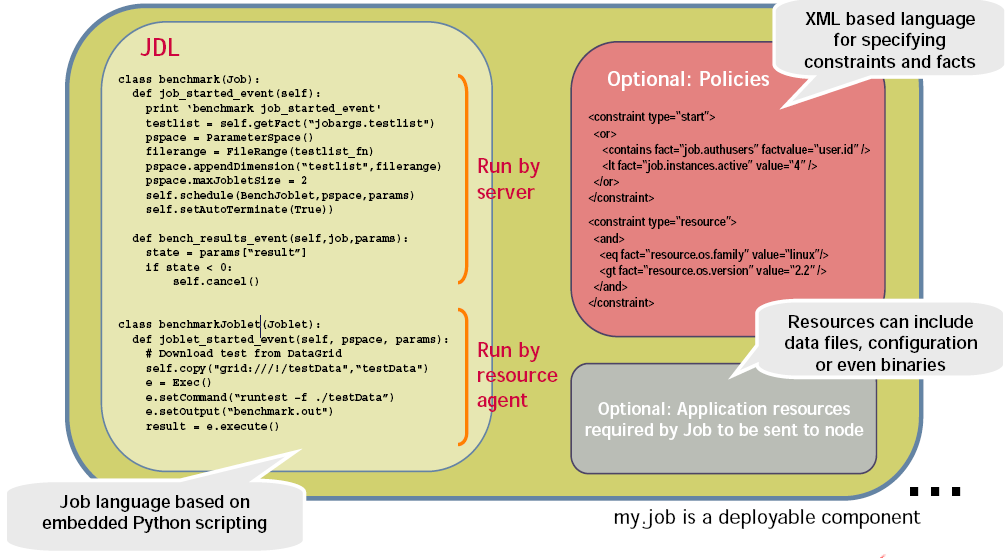
Workflows
Jobs can also invoke other jobs, creating hierarchies. Because of the communication between the job client (either a user/user client application or another job) it is easy to create complex workflows composed of discrete and separately versioned components.
When a job is executed and an instance is created, the class that extends job is run on the server and as that logic requests resources, the class(es) that extend the joblet are automatically shipped to the requested resource to manage the remote task. The communication mechanism between these distributed components manifests itself as event method calls on the corresponding piece.
For more information, see Workflow Job Example
in Advanced Job Development Concepts
, and Job State Transition Events
, or Communicating Through Job Events
in Job Architecture
in the PlateSpin Orchestrate 2.0 Developer Guide and Reference.
1.2.5 Distributed Messaging and Failover
A job has control over all aspects of its failover semantics, which can be specified separately for conditions such as the loss of a resource, failure of an individual joblet, or joblet timeout.
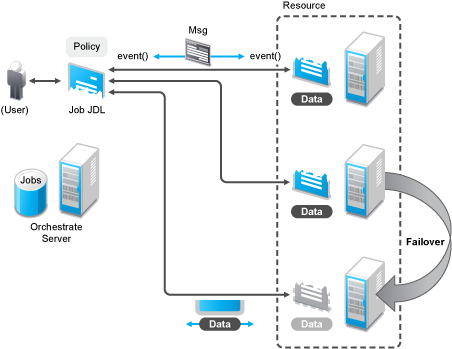
The failover/health check mechanisms leverage the same communications mechanism that is available to job and joblet logic. Specifically, when a job is started and resources are employed, a message interface is established among all the components as shown in Figure 1-10.
Optionally, a communication channel can also be kept open to the initiating client. This client communication channel can be closed and reopened later based on jobid. Messages can be sent with the command
sendEvent(foo_event, params, ...)
and received at the other end as a method invocation
def foo_event(self, params)
If a job allows it, a failure in any joblet causes the Orchestrate Server to automatically find an alternative resource, copy over the joblet JDL code, and reestablish the communication connection. A job also can listen for such conditions simply by defining a method for one of the internally generated events, such as def joblet_failure_event(...).
Such failover allows, for example, for a large set of regression tests to be run (perhaps in parallel) and for a resource to die in the middle of the tests without the test run being rendered invalid. The figure below shows how job logic is distributed and failover achieved:
Figure 1-10 A Job in Action
1.2.6 Web-Based User Interaction
PlateSpin Orchestrate ships a universal job monitoring and submission interface as a Web application that natively runs on the Orchestrate Server. This application is written to the PlateSpin Orchestrate job management API and can be customized or replaced with alternative rendering as required.The figure belows shows an example of this interface, called the Server Portal.
Figure 1-11 PlateSpin Orchestrate Server Portal
For more information, see the PlateSpin Orchestrate 2.0 Server Portal Reference.