75.2 Schéma CIM
Les éléments du méta-schéma sont les classes, les propriétés et les méthodes. Celui-ci prend également en charge les indications et les associations comme des types de classes et les références comme des types de propriétés.
Les classes peuvent être organisées dans une hiérarchie de généralisation représentant les relations des sous-types entre les classes. La hiérarchie de généralisation est un graphique à racines et à direction qui ne prend pas en charge les héritages multiples.
Une classe normale peut contenir les propriétés scalaires ou de tableau de n'importe quel type intrinsèque, par exemple booléen, entier, chaîne, etc. Elle ne peut pas contenir des classes intégrées, ni des références à d'autres classes.
Une association est une classe spéciale contenant deux ou plusieurs références, et représente une relation entre deux ou plusieurs objets. Étant donné la manière dont les associations sont définies, il est possible d'établir une relation entre les classes sans affecter aucune classe liée. Cela signifie que l'ajout d'une association ne modifie pas l'interface des classes liées. Seules les associations peuvent bénéficier de références.
Le fragment de schéma présenté dans l'illustration suivante montre les relations entre certains objets CIM que ZENworks 7 Desktop Management utilise.
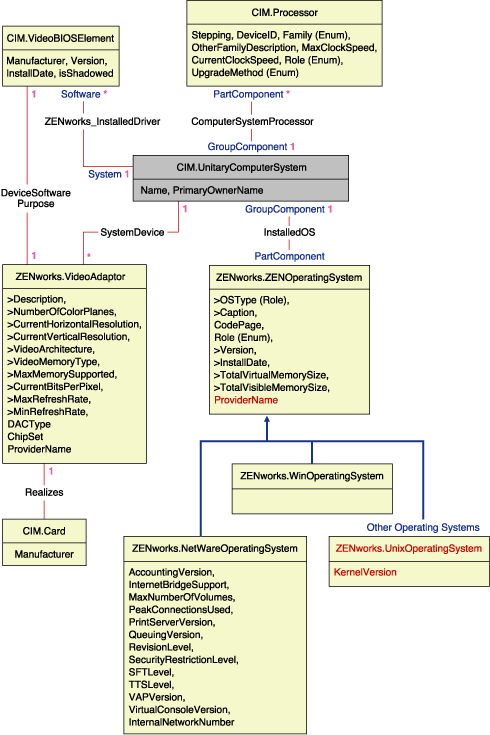
L'illustration montre comment le schéma CIM est assigné à un schéma SGBDR. Les classes sont indiquées par leur nom dans l'en-tête du cadre. Les associations sont indiquées sur les traits qui relient les classes.
La hiérarchie d'héritage de ce fragment de schéma est présentée dans l'illustration suivante du schéma CIM 2.2. Les références illustrées avec le type Ref sont en gras avec chaque sous-type d'association restreignant le type de la référence.
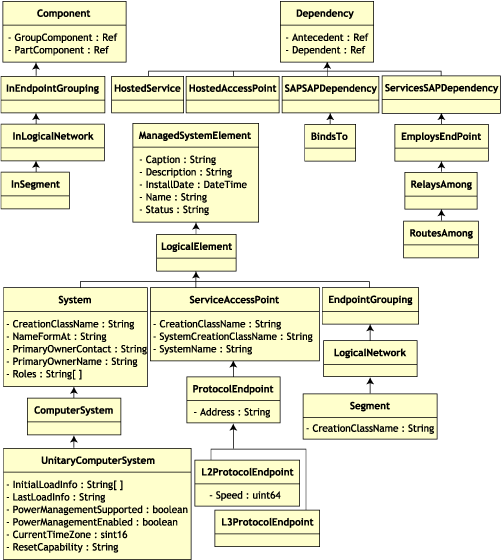
75.2.1 Assignation du schéma CIM au schéma relationnel
CIM est un modèle d'objet complet avec des classes, des héritages et du polymorphisme. L'assignation à un schéma relationnel conserve le maximum de ces caractéristiques. Les deux aspects suivants font partie de l'assignation relationnelle :
-
Schéma logique : similaire à une API, le schéma logique définit la manière dont les données apparaissent dans les applications. L'objectif est que, quelle que soit la base de données sous-jacente, ce schéma logique ne change pas et que les logiciels d'applications puissent fonctionner sans être modifiés sur n'importe quelle base de données prise en charge. Cet objectif n'est pas entièrement réalisable même si SQL est une norme. Les logiciels d'applications doivent posséder plus d'informations sur la base de données utilisée, informations qui peuvent être extraites et regroupées dans une petite partie du code d'application.
-
Schéma physique : le schéma physique définit la manière dont les données sont structurées dans la base de données. Ce schéma est le plus souvent spécifique à la base de données étant donné la nature de SQL et du SGBDR. Ce document ne présente qu'une description générale du schéma physique.
Dans la base de donnés, un tableau représente chaque classe de la hiérarchie CIM. Dans la table, chaque propriété non héritée de la classe est représentée par une colonne du type approprié. Chaque table possède également une clé primaire, id$, un entier de 64 bits qui identifie de manière unique une instance. Une instance de classe CIM est représentée par une ligne dans chaque table qui correspond à une classe dans sa hiérarchie d'héritage. Chaque ligne possède la même valeur d'id$.
Chaque classe CIM est également représentée par une vue utilisant l'id$ pour relier les lignes des différents tableaux de la hiérarchie d'héritage afin de créer un ensemble composite de propriétés (héritées et locales) pour une instance de cette classe. La vue comprend également une colonne supplémentaire (class$) de type entier qui représente le type de la classe actuelle (la dernière dans la hiérarchie) de l'instance.
Les associations sont assignées de la même manière que les classes normales, avec une propriété de référence représentée par une colonne contenant le champ id$ de l'instance d'objet référencée. Ainsi, les associations peuvent être traversées par la jonction entre le champ de référence de l'association et le champ id$ de la table référencée.
L'illustration suivante décrit une requête standard qui utilise cette assignation :
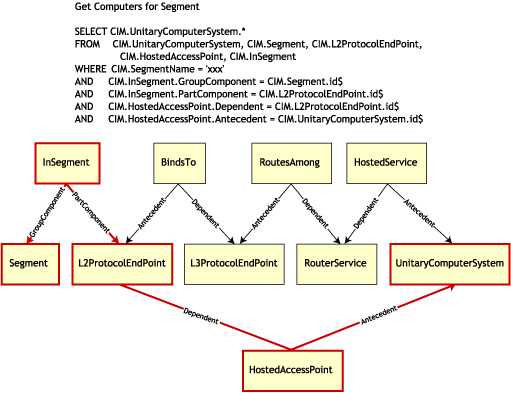
Cette requête recherche tous les ordinateurs connectés à un segment de réseau donné. Les classes et les relations concernées sont mises en évidence par des bordures.
Les rubriques suivantes décrivent les deux types de schéma :
75.2.2 Schéma logique
Le schéma logique est le schéma de la base de données tel qu'il apparaît aux utilisateurs de la base de données et de l'applicatif. Ce schéma se compose de procédures stockées et de vues. Les tables sous-jacentes ne sont pas visibles par l'application.
Les composants d'inventaire de ZENworks 7 Desktop Management utilisent JDBC pour générer des instructions SQL vers le SGBDR et effectuer des conversions entre les types de données SGBDR et les types de données Java. L'utilisation de JDBC avec les procédures et les vues enregistrées offre un niveau d'abstraction qui isole le code d'application de la technologie de la base de données sous-jacente et des modifications du schéma physique.
Les différents éléments du schéma logique sont traités plus en détail dans les sections suivantes :
Assignation de nom aux éléments du schéma
Il est recommandé d'utiliser les noms CIM non modifiés contenus dans le schéma de la base de données. Les différences entre les modes d'assignation de nom peuvent quand même générer certains problèmes :
- Les noms CIM et SQL ne distinguent pas les majuscules des minuscules.
- Toutes les bases de données ont des jeux de mots réservés différents qui doivent être mis entre guillemets (" ") lorsqu'ils sont utilisés comme noms d'éléments du schéma ; toutefois, dans Oracle, lorsqu'un nom est placé entre guillemets, il distingue les majuscules des minuscules.
- Les classes CIM évitent d'utiliser des mots réservés de SQL comme noms.
- La longueur des noms CIM n'est pas limitée et généralement ils sont longs. Sybase autorise jusqu'à 128 caractères, mais Oracle limite la longueur des noms à 30.
La plupart de ces problèmes sont évités lors de la génération du schéma en conservant la casse des noms CIM, en tronquant tous les noms contenant plus de 30 caractères et en mettant entre parenthèses tout nom faisant partie de la réunion des jeux de noms réservés.
Tout nom contenant plus de 28 caractères est abrégé sous forme d'un nom racine de 28 caractères ou moins afin d'obtenir un préfixe à deux caractères pour permettre à tous les éléments du schéma SQL d'utiliser le même nom racine. L'algorithme d'abréviation raccourcit un nom de manière à ce qu'il soit mnémonique, reconnaissable et unique dans son domaine. Le nom abrégé reçoit le caractère # comme suffixe (notez que # est un caractère non autorisé dans CIM) afin d'empêcher tout conflit avec d'autres noms. Si plusieurs noms d'un même domaine donnent une même abréviation, un chiffre supplémentaire est ajouté pour rendre le nom unique. Par exemple, AttCacForRegularFilesMin# est la forme abrégée de AttributeCachingForRegularFilesMin#.
Tous les noms ainsi tronqués sont consignés dans le tableau des noms tronqués afin que le programme puisse rechercher le nom CIM réel et récupérer le nom tronqué à utiliser avec SQL.
Les vues sont les éléments du schéma le plus souvent manipulés par le code et les requêtes d'application. Elles utilisent le même nom que la classe CIM qu'elles représentent. Par exemple, la classe CIM.UnitaryComputerSystem est représentée par une vue nommée CIM.UnitaryComputerSystem.
En cas de nécessité, des noms sont créés pour les index et les tables auxiliaires en concaténant le nom de la classe et celui de la propriété séparés par le caractère $. Ces noms sont généralement abrégés. Par exemple, NetworkAdapter$NetworkAddresses est abrégé en NetAdapter$NetAddresses#. Ce fonctionnement n'a pas d'impact négatif sur les utilisateurs des schémas ZENworks 7 Desktop Management.
Utilisateurs et rôles
Dans SQL, un utilisateur qui porte le même nom que le schéma est le propriétaire de chaque schéma, par exemple CIM, ManageWise®, ZENworks, etc.
En outre, il existe un utilisateur MW_DBA détenant les droits et les privilèges d'administrateur de base de données sur tous les objets du schéma. Le rôle MW_Reader a accès en lecture seule à tous les objets du schéma et le rôle MW_Updater a accès en lecture-écriture-exécution à tous les objets du schéma.
Les programmes d'application doivent accéder à la base de données en tant que MW_Reader ou MW_Updater pour une base de données Sybase, MWO_Reader ou MWO_Updater pour une base de données Oracle et MWM_Reader ou MWM_Updater pour la base de données MS SQL Server, en fonction de leurs conditions requises.
Types de données
Les types de données CIM sont assignés au type de données le plus approprié fourni par la base de données. Généralement, l'application Java n'a pas besoin du type. Elle utilise en effet JDBC pour accéder aux données.
Étant donné que Java ne prend pas en charge les types non signés en mode natif, vous devez utiliser les classes ou les types entier de la taille supérieure pour les représenter. De même, assurez-vous que ni la lecture ni l'écriture dans la base de données ne pose problème. Par exemple, la lecture ou l'écriture d'un nombre négatif dans un champ non signé de la base de données peut générer une erreur.
Les chaînes dans CIM et Java étant en Unicode, la base de données est créée à l'aide du jeu de caractères UTF-8. L'internationalisation ne pose aucun problème ; en revanche, elle peut poser des problèmes de distinction majuscules/minuscules dans les requêtes.
Toutes les bases de données conservent la casse des chaînes de données qu'elles contiennent. Toutefois, lors de la requête, elles peuvent accéder aux données en distinguant les majuscules et les minuscules ou d'une autre manière. Dans ZENworks 7 Desktop Management, les composants Requête d'inventaire et Exportation des données ne sont pas affectés parce que les données recherchées sont récupérées dans la base de données avant le lancement de la requête, par conséquent la distinction majuscules/minuscules est automatiquement prise en compte.
Dans CIM, les chaînes peuvent être spécifiées avec ou sans longueur maximale en nombre de caractères. Ne comportant pas de spécification de taille, beaucoup de chaînes peuvent être illimitées. Pour des raisons d'efficacité, ces chaînes illimitées sont assignées à une chaîne variable de 254 caractères au maximum. Les chaînes CIM dont la taille est maximale sont assignées à des chaînes de base de données de variables de même taille. Dans la base de données, la longueur est exprimée en octets et pas en caractères. En effet, l'enregistrement d'un caractère Unicode peut nécessiter plusieurs octets.
Vues
Chaque classe CIM est représentée dans la base de données par une vue contenant toutes les propriétés hors tableau locales et héritées de cette classe. Une vue porte le nom de la classe CIM à laquelle elle correspond.
Les vues peuvent être interrogées à l'aide de l'instruction SELECT et mises à jour à l'aide de l'instruction UPDATE. Étant donné que les vues ne peuvent pas être utilisées avec les instructions INSERT et DELETE, utilisez les procédures de construction et de destruction.
75.2.3 Schéma physique
Le schéma physique se compose d'éléments nécessaires à la mise en oeuvre de la base de données. Il diffère selon chaque base de données. Un schéma physique normal comprend les éléments suivants :
- Définitions de table "t$xxx"Définitions d'index "i$xxx"
- Définitions de déclencheurs "x$xxx", "n$xxx" et "u$xxx"
- Définitions de séquences (Oracle) "s$xxx"
- Procédures enregistrées et fonctions
Comme le schéma logique se place au-dessus du schéma physique, il n'est pas nécessaire aux utilisateurs ni aux applications de connaître le schéma physique.