2.4 Clusters
Há três aspectos que você deverá considerar ao usar o aplicativo de usuário em um ambiente em cluster:
- A configuração em cluster do JBoss (consulte a Seção 2.4.1, Clusters JBoss)
- A configuração de cache do aplicativo de usuário (consulte a Seção 2.4.3, Definindo a configuração de cache do grupo de clusters do aplicativo de usuário)
- A configuração do mecanismo de workflow (consulte a Seção 2.4.4, Configurando workflows para clusters)
2.4.1 Clusters JBoss
Um cluster é um conjunto de nós de servidores de aplicativos que fornecem determinados serviços. O propósito de um cluster é aumentar o desempenho e a confiabilidade dos aplicativos. Em geral, um cluster fornece três benefícios principais aos aplicativos empresariais:
- Alta disponibilidade
- Escalabilidade (maior capacidade)
- Equilíbrio de carga
Alta disponibilidade significa que um aplicativo é confiável e está disponível durante grande parte do tempo em que está distribuído. Clusters proporcionam alta disponibilidade, uma vez que o mesmo aplicativo é executado em todos os nós. Caso um nó falhe, o aplicativo ainda será executado em outros nós. O aplicativo de usuário do Identity Manager usufrui de maior disponibilidade ao ser executado em um ambiente em cluster. Contudo, o aplicativo de usuário do Identity Manager não tem suporte para a replicação de sessão http. Isso significa que, se a sessão estiver em andamento em um nó, e esse nó falhar, as informações da sessão serão perdidas.
O equilíbrio de carga é a pratica de distribuir a carga de trabalho entre os membros de um cluster. O objetivo do equilíbrio de carga é aprimorar o desempenho. O equilíbrio de carga pode ser realizado de várias formas (por exemplo, com o rodízio de DNS ou equilíbrio de carga de hardware). Consulte http://www.onjava.com/pub/a/onjava/2001/09/26/load.html para obter uma abordagem dos diversos métodos de equilíbrio de carga. Seja qual for o método selecionado, convém incluir o equilíbrio de carga em sua configuração de cluster.
Grupos de clusters JBoss
Os clusters JBoss são baseados em um módulo de comunicação chamado JGroups. O JGroups é instalado com o JBoss (ele também pode ser usado sem o JBoss). Os JGroups proporcionam a comunicação entre grupos, que compartilham um nome, um endereço de multicast e uma porta de multicast comuns.
Quando você instala um servidor JBoss em cluster, o JBoss define dois grupos JGroups diferentes para o uso no gerenciamento do cluster. Um é chamado DefaultPartition e é definido em /deploy/cluster-service.xml. Esse grupo de clusters é usado pelo JBoss para fornecer serviços de cluster básicos. O JBoss também define um segundo grupo de clusters chamado Tomcat-Cluster. Esse grupo de clusters é definido em /deploy/tc-cluster-service.xml. Esse grupo de clusters fornece a replicação de sessão para o servidor Tomcat executado no JBoss.
O aplicativo de usuário do Identity Manager usa um terceiro grupo de clusters. Esse grupo de clusters usa um nome UUID para minimizar o risco de conflitos com outros grupos de clusters que os usuários possam adicionar a seus servidores. Por padrão, o grupo de clusters é chamado c373e901aba5e8ee9966444553544200. Esse cluster não é configurado usando um arquivo de serviço JBoss. Em vez disso, as configurações estão localizadas no diretório e podem ser definidas usando os recursos de administração do aplicativo de usuário. Se estiver familiarizado com clusters JGroups e JBoss, você poderá ajustar as configurações de cluster do aplicativo de usuário por meio dessa interface. Mudanças na configuração de cluster entram em vigor em um nó de servidor somente após ele ter sido reiniciado.
O grupo de clusters do aplicativo de usuário é usado apenas para coordenar os caches do aplicativo de usuário em um ambiente em cluster. Ele não depende dos dois grupos de clusters JBoss, nem interage com eles de modo algum. Por padrão, o grupo de clusters de aplicativo de usuário e os dois grupos JBoss usam nomes de grupo, endereços e portas de multicast diferentes, assim, não é necessária a reconfiguração.
As configurações do grupo de clusters do aplicativo de usuário são compartilhadas por qualquer aplicativo do Identity Manager 3 que compartilhe a mesma configuração de diretório. O propósito da opção de configurações locais na interface de administração do aplicativo de usuário é permitir que um administrador remova um nó de um cluster, ou mude a participação de servidores em um cluster. Por exemplo, você pode desabilitar o uso global de cluster e, em seguida, habilitá-lo localmente para um subconjunto de servidores que compartilhem a configuração de diretório.
Farm de Aplicativos
O JBoss permite a distribuição do tipo "hot-deploy" em um cluster copiando um aplicativo EAR, WAR ou JAR para o diretório da farm de uma instância do JBoss em cluster. A distribuição “hot” em um computador faz com que o componente seja distribuído automaticamente a todas as instâncias no cluster durante a sua execução.
Esse modo de distribuição de aplicativo não é recomendado com a versão do JBoss Application Server (4.0.2) incluída com o programa de instalação do aplicativo de usuário durante a criação deste documento, pois há problemas relacionados ao seu uso que ainda não foram resolvidos. No entanto, fornecemos as etapas básicas que devem ser realizadas (consulte Distribuindo o aplicativo de usuário em um cluster usando farming do JBoss) para a distribuição bem-sucedida do aplicativo de usuário utilizando a tecnologia de farming do JBoss, já que é provável que essa tecnologia seja aprimorada após a publicação deste documento.
Banco de dados MySQL
O programa de instalação do aplicativo de usuário pode instalar o gerenciador de banco de dados MySQL e criar um banco de dados para uso com o aplicativo de usuário, ou então pode utilizar um banco de dados Oracle, Microsoft SQL Server ou MySQL. O banco de dados é responsável pela persistência de dados. Todos os nós no cluster JBoss devem acessar a mesma instância de banco de dados. O aplicativo de usuário utiliza chamadas JDBC padrão para acessar e atualizar o banco de dados. O aplicativo de usuário utiliza uma fonte de dados JDBC vinculada à árvore JNDI para abrir uma conexão ao banco de dados. Se você criar um cluster JBoss usando o programa de instalação do aplicativo de usuário, a fonte de dados será instalada automaticamente. Se você optar por instalar manualmente o cluster JBoss, deverá copiar o arquivo de fonte de dados (IDM-ds.xml) no diretório de distribuição em todos os nós do cluster. Além disso, se estiver usando o MySQL, você deverá copiar o driver JDBC do MySQL (mysql-connector-java-3.1.10-utf8-clob-fix-bin.jar), localizado no diretório /server/IDM/lib do JBoss, no diretório server/IDM/lib do JBoss.
Registro
Para habilitar o registro em clusters, você deverá editar o arquivo de configuração log4j.xml, localizado no diretório \conf da configuração do servidor JBoss (por exemplo, \server\IDM\conf), e retirar as marcas de comentário da seção na parte inferior similar a:
<!-- Registro de clusters --> - <!-- Retire a marca de comentário do código a seguir para redirecionar as categorias org.jgroups e org.jboss.ha a um arquivo cluster.log. <appender name="CLUSTER" class="org.jboss.logging.appender.RollingFileAppender"> <errorHandler class="org.jboss.logging.util.OnlyOnceErrorHandler"/> <param name="File" value="${jboss.server.home.dir}/log cluster.log"/> <param name="Append" value="false"/> <param name="MaxFileSize" value="500KB"/> <param name="MaxBackupIndex" value="1"/> <layout class="org.apache.log4j.PatternLayout"> <param name="ConversionPattern" value="%d %-5p [%c] %m%n"/> </layout> </appender> <category name="org.jgroups"> <priority value="DEBUG" /> <appender-ref ref="CLUSTER"/> </category> <category name="org.jboss.ha"> <priority value="DEBUG" /> <appender-ref ref="CLUSTER"/> </category> -->
O arquivo cluster.log está no diretório log da configuração do servidor JBoss (por exemplo, \server\IDM\log).
2.4.2 Instalando o aplicativo de usuário em um cluster JBoss
O método recomendado de instalação do aplicativo de usuário em um cluster é o uso do programa de instalação do aplicativo de usuário para instalá-lo em cada nó do cluster. Embora não recomendemos a distribuição do aplicativo de usuário em um cluster usando o método de farming do JBoss, incluímos um procedimento que pode ser executado como método alternativo.
Usando o programa de instalação do aplicativo de usuário em cada nó do cluster
O JBoss é fornecido com três configurações de servidor prontas para o uso: mínima, padrão e todos. Clusters são habilitados apenas na configuração todos. O arquivo cluster-service.xml na pasta /deploy descreve a configuração da partição de cluster padrão. Quando você instala o aplicativo de usuário e indica ao programa de instalação que deseja instalá-lo em um cluster, o programa de instalação faz uma cópia da configuração todos, nomeia a cópia IDM (por padrão, o programa de instalação permite mudar o nome) e instala o aplicativo de usuário nessa configuração.
Para instalar o aplicativo de usuário em cada nó do cluster usando o programa de instalação do aplicativo de usuário:
-
Execute uma instalação completa do aplicativo de usuário (MySQL, JBoss e o aplicativo de usuário) no primeiro nó JBoss. Para obter informações sobre o uso do programa de instalação do aplicativo de usuário, consulte o Guia de Instalação do Identity Manager 3.
- Se você estiver usando MySQL como o banco de dados do aplicativo de usuário, o instalador do aplicativo de usuário criará uma nova instalação do MySQL. Anote a senha de usuário raiz do MySQL que especificar; você precisará dessa informação ao instalar o aplicativo de usuário nos outros nós do cluster.
- Na tela Configuração do IDM do programa de instalação, selecione a opção “cluster (tudo)”.
- Selecione outras opções de instalação conforme apropriado em seu ambiente.
-
Se o MySQL não estiver em execução, inicie-o usando o arquivo start-mysql.bat no diretório /IDM/mysql.
NOTA:No Linux, o seguinte comando shell será útil para determinar se o daemon MySQL está em execução:
ps -A | grep mysqld
Se esse comando resultar em várias linhas terminadas em mysqld, isso significa que o daemon está em execução.
-
Inicie o JBoss e o aplicativo de usuário utilizando o arquivo start-jboss.bat (Windows) ou start-jboss.sh (Linux), localizado no diretório IDM.

-
Execute uma instalação personalizada do aplicativo de usuário em cada nó adicional do cluster JBoss.
- Selecione apenas o aplicativo de usuário para instalação:
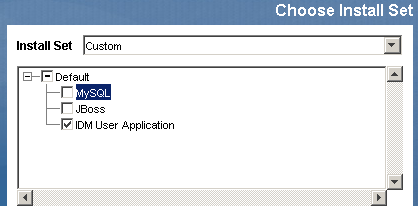
- Especifique o endereço IP ou nome de host do servidor no qual o banco de dados do aplicativo de usuário está instalado.
- Especifique o nome de usuário e a senha do banco de dados do aplicativo de usuário. Se você estiver usando MySQL, o nome de usuário é root, e a senha é aquela especificada durante o processo de instalação em Etapa 1.
- Na tela IDM Configuration do programa de instalação, selecione a opção “cluster (tudo)”.
- Selecione outras opções de instalação conforme apropriado em seu ambiente.
-
Inicie cada nó do cluster JBoss utilizando o arquivo start-jboss.bat (Windows) ou start-jboss.sh (Linux), localizado no diretório IDM.
Distribuindo o aplicativo de usuário em um cluster usando farming do JBoss
Não use o recurso de farming do JBoss com a versão 4.0.2 ou anterior, pois poderá encontrar problemas (consulte http://jira.jboss.com/jira/browse/JBAS-1899). Recomendamos a instalação do aplicativo de usuário em cada nó do cluster por meio do programa de instalação do aplicativo de usuário (consulte Usando o programa de instalação do aplicativo de usuário em cada nó do cluster neste Capítulo). Contudo, se desejar usar farming para distribuir o aplicativo de usuário em um cluster JBoss usando o JBoss 4.0.3 ou posterior, siga as etapas abaixo.
NOTA:Essas etapas destinam-se a clientes que desejam usar o JBoss 4.0.3 por conta própria para experimentar essa configuração. A versão oficialmente suportada é a 4.0.2.
Para distribuir o aplicativo de usuário em um cluster usando farming do JBoss:
-
Execute uma instalação personalizada do aplicativo de usuário em um dos nós do cluster JBoss, selecionando o aplicativo de usuário e o MySQL (se estiver usando MySQL; do contrário, instale apenas o aplicativo de usuário) para a instalação. Você pode realizar a instalação com todos os clusters executados no nó, porém, o nó para a instalação do aplicativo de usuário deverá ser o primeiro nó no cluster a ser iniciado.
-
Copie o arquivo de driver JDBC (por exemplo, se estiver usando o MySQL, o driver JDBC estará em mysql-connector-java-3.1.10-utf8-clob-fix-bin.jar), localizado no diretório /server/IDM/lib, no diretório correspondente em cada nó do cluster.
-
Copie o arquivo cacerts do diretório /lib/security do JRE instalado com o aplicativo de usuário no diretório /lib/security do JRE de cada nó do cluster.
-
Mova o arquivo IDM.war e o arquivo de fonte de dados IDM-ds.xml do diretório /deploy, no diretório de configuração do servidor, para o diretório /farm no diretório de configuração do servidor. Você deve mover de fato os arquivos. Não deixe os originais no diretório /deploy.
-
Inicie o banco de dados do aplicativo de usuário (se estiver usando o MySQL fornecido, inicie-o utilizando o arquivo start-mysql.bat localizado no diretório /IDM/mysql).
-
Inicie o JBoss e o aplicativo de usuário utilizando o arquivo start-jboss.bat (Windows) ou start-jboss.sh (Linux), localizado no diretório IDM no nó em que instalou o aplicativo de usuário e o banco de dados do aplicativo de usuário.
-
Inicie os outros nós no cluster.
2.4.3 Definindo a configuração de cache do grupo de clusters do aplicativo de usuário
Usuários familiarizados com clusters JGroups e JBoss podem modificar as configurações de cache do grupo de clusters usando a interface de administração do aplicativo de usuário (consulte a Seção 13.3.5, Configurações de cache para clusters). Mudanças na configuração de cluster entram em vigor em um nó de servidor somente após esse nó ter sido reiniciado.
2.4.4 Configurando workflows para clusters
O mecanismo de workflow em cluster funciona de modo independente da estrutura de cache do aplicativo de usuário. Há diversas etapas a serem executadas para garantir que o mecanismo de workflow funcione corretamente em um ambiente de cluster.
- Todos os servidores no cluster devem estar apontando para o mesmo banco de dados. Se você instalar o aplicativo de usuário no cluster usando o método recomendado (consulte Usando o programa de instalação do aplicativo de usuário em cada nó do cluster), poderá fazer isso durante o processo de instalação especificando o endereço IP ou nome de host do servidor no qual o banco de dados do aplicativo de usuário está instalado. Se você usar o método de farming para distribuir o aplicativo de usuário a nós do cluster (consulte Distribuindo o aplicativo de usuário em um cluster usando farming do JBoss), poderá fazer isso movendo o arquivo de fonte de dados (IDM-ds.xml) do diretório /deploy ao diretório /farm no nó em que o aplicativo de usuário está instalado. Isso faz com que a fonte de dados seja distribuída em todos os nós do cluster.
- Cada servidor no cluster deverá ser iniciado com um ID de mecanismo exclusiva. Isso pode ser feito configurando a propriedade de sistema com.novell.afw.wf.engine-id na inicialização do servidor. Por exemplo, se desejar iniciar o JBoss e atribuir o ID de mecanismo ENGINE1 ao mecanismo de workflow do servidor, você poderá usar o seguinte comando:
run.sh -Dcom.novell.afw.wf.engine-id=ENGINE1 (Linux)
run.bat -Dcom.novell.afw.wf.engine-id=ENGINE1 (Windows)
Após ser iniciada por um mecanismo de workflow executado em um determinado servidor, a instância do processo de workflow poderá ser executada e concluída apenas naquele servidor. Isso garante a execução segura do processo do workflow. Contudo, não fornece suporte de failover à instância do processo. Se um servidor em um cluster falhar, a instância do processo só será reiniciada quando um mecanismo com o mesmo ID for reiniciado.
Se um servidor não puder ser reiniciado devido a uma falha grave de hardware ou software, você poderá iniciar o servidor do aplicativo em um novo computador usando o mesmo ID de mecanismo de workflow usado no computador que não pôde ser recuperado. Como o ID de mecanismo é um nome lógico, e não um mapeamento direto ao computador físico no qual o mecanismo era executado, a instância do processo interrompida será concluída com êxito no novo computador.
Instâncias de processo pertencem ao mecanismo que iniciou o processo. Contudo, um usuário pode efetuar login em qualquer aplicativo de usuário em um cluster para ver detalhes do processo, recolher processos ou concluir tarefas a ele atribuídas. Processos que são recolhidos ou tarefas concluídas em um mecanismo ao qual o processo não pertence registram um estado de pendente e recomeçam sua execução após serem descobertos pelo mecanismo ao qual pertencem.