75.2 Esquema CIM
Os elementos do metaesquema são classes, propriedades e métodos. O meta-esquema também suporta indicações e associações como tipos de classes e suporta referências como tipos de propriedades.
As classes podem ser organizadas em uma hierarquia de generalização que representa relacionamentos de subtipos entre as classes. Essa hierarquia de generalização é um gráfico de raiz direcionado que não oferece suporte à herança múltipla.
Uma classe regular pode conter propriedades escalares ou de matriz de qualquer tipo intrínseco, como booleano, inteiro, string e outros. Ela não pode conter classes incorporadas nem referências a outras classes.
Uma associação é uma classe especial que contém duas ou mais referências. Ela representa um relacionamento entre dois ou mais objetos. Devido à forma de definição das associações, é possível estabelecer um relacionamento entre classes sem afetar nenhuma das classes relacionadas. Isto é, o acréscimo de uma associação não afeta a interface dessas classes. Somente as associações podem ter referências.
O fragmento de esquema na ilustração a seguir mostra os relacionamentos entre alguns objetos CMI utilizados pelo ZENworks 7 Desktop Management.
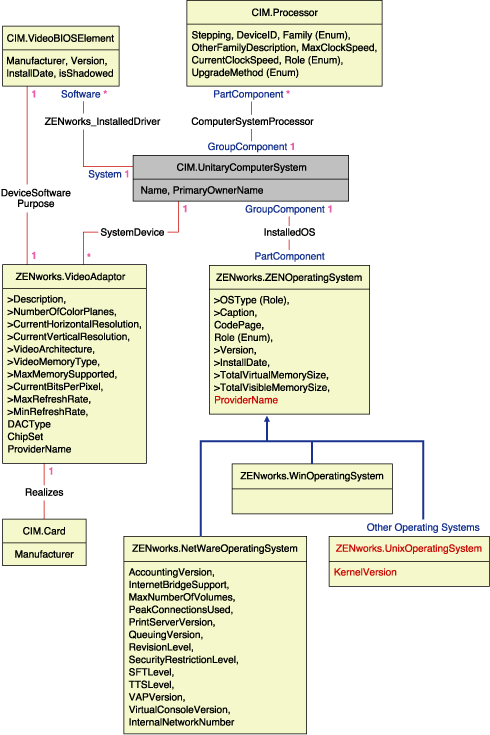
A ilustração mostra como o esquema CIM faz mapeamento para um esquema de DBMS relacional. As classes são mostradas com o nome da classe no título da caixa. As associações estão identificadas nas linhas entre duas classes.
A hierarquia de herança deste fragmento de esquema é mostrada na ilustração do esquema CIM 2.2 a seguir. As referências mostradas como tipo Ref estão em negrito, com cada subtipo de associação limitando o tipo da referência.
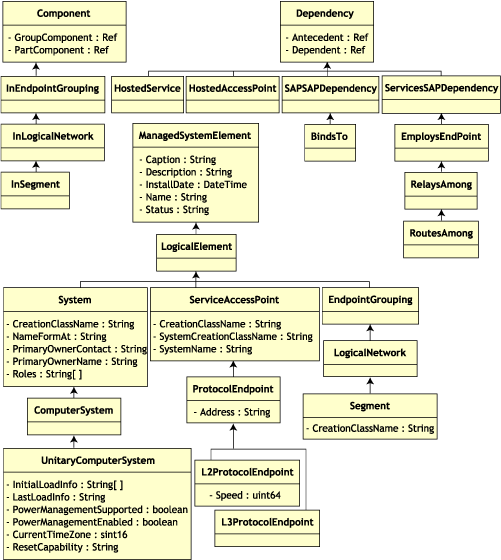
75.2.1 Mapeamento CIM-para-Relacional
O CIM é um modelo completo de objetos com classes, herança e polimorfismo. O mapeamento gerado para um esquema relacional preserva o máximo desses recursos. Os dois aspectos a seguir fazem parte do mapeamento relacional:
-
Esquema Lógico: o esquema lógico define como os dados aparecem para os aplicativos, de forma semelhante a uma API. A meta é que o esquema lógico permaneça o mesmo, independentemente do banco de dados subjacente, de forma que esse software aplicativo seja executado sem alterações em quaisquer bancos de dados suportados. Embora SQL seja um padrão, essa meta não é totalmente possível. O software aplicativo precisará saber mais sobre o banco de dados em uso, e essas informações poderão ser extraídas e isoladas em uma pequena área do código do aplicativo.
-
Esquema Físico: o esquema físico define como os dados são estruturados no banco de dados. O esquema tende a ser específico ao banco de dados, devido à natureza do SQL e do RDBMS. Este documento descreverá o esquema físico apenas em termos gerais.
Uma tabela no banco de dados representa cada classe na hierarquia do CIM. Uma coluna do tipo apropriado na tabela representa cada propriedade não herdada na classe. Cada tabela também tem uma chave primária, id$, que é um inteiro de 64 bits que identifica uma instância com exclusividade. Em cada tabela, uma instância de uma classe CIM é representada por uma linha, que corresponde a uma classe em sua hierarquia de herança. Cada linha tem o mesmo valor para id$.
Cada classe CIM também é representada por uma tela que usa o id$ para unir as linhas das várias tabelas de uma hierarquia de herança a fim de produzir um conjunto misto de propriedades (herdadas e locais) para uma instância da classe. A tela também contém uma coluna extra, class$, de tipo inteiro, que representa o tipo da classe real (a maioria das folhas) da instância.
As associações são mapeadas da mesma forma que as classes regulares, com a representação de uma propriedade de referência por uma coluna com o campo id$ da instância do objeto referenciado. Assim, as associações podem ser percorridas através de uma ligação entre o campo de referência da associação e o campo id$ da tabela referenciada.
A ilustração a seguir representa uma consulta típica, usando este mapeamento:
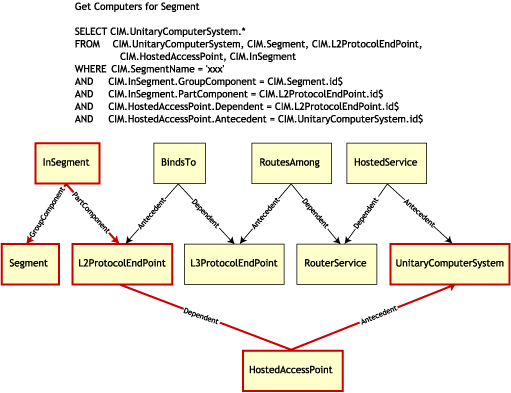
Essa consulta encontra todos os computadores conectados a um determinado segmento da rede. As classes e os relacionamentos envolvidos estão realçados com bordas.
Os tópicos a seguir descrevem ambos os tipos de esquema:
75.2.2 Esquema Lógico
O esquema lógico é o esquema de banco de dados como é visto pelos usuários do banco de dados e do programa aplicativo. O esquema consiste em telas e processamentos armazenados. As tabelas subjacentes não são visíveis para o aplicativo.
Os componentes de Inventário do ZENworks 7 Desktop Management usam o JDBC para emitir instruções SQL para o RDBMS e para conversão entre tipos de dados RDBMS e tipos de dados Java. O uso de JDBC com telas e procedimentos armazenados oferece um nível de extração que isola o código do aplicativo da tecnologia subjacente do banco de dados e de mudanças no esquema físico.
Os vários elementos do esquema lógico são abordados com mais detalhes nas seguintes seções:
Nomeando elementos de esquema
Recomenda-se utilizar os nomes CIM sem alterações no esquema do banco de dados. É possível que ainda ocorram alguns problemas, devido às diferenças nos esquemas de nomeação, como as que se seguem:
- Os nomes em CIM e em SQL não fazem distinção entre maiúsculas e minúsculas.
- Todos os bancos de dados apresentam diferentes conjuntos de palavras reservadas que devem ser colocadas entre aspas (“ “) quando utilizadas como nomes de elementos de esquema. Entretanto, no Oracle, quando um nome é colocado entre aspas, ele fica sujeito à distinção entre letras maiúsculas e minúsculas.
- As classes CIM impedem o uso de palavras reservadas de SQL como nomes.
- Os nomes CIM não têm limitação de tamanho e normalmente são longos. O Sybase permite até 128 caracteres, mas o Oracle restringe os nomes a 30 caracteres.
A maioria desses problemas é evitada durante a geração de esquemas, com a preservação das maiúsculas/minúsculas dos nomes CIM, a abreviação de todos os nomes com mais de 30 caracteres e a colocação entre aspas de qualquer nome que faça parte dos conjuntos de palavras reservadas.
Para permitir um prefixo de dois caracteres, todo nome com mais de 28 caracteres é abreviado para um nome raiz de 28 ou menos caracteres, de forma que todos os elementos do esquema SQL associado possam usar o mesmo nome raiz. O algoritmo de abreviação reduz um nome de forma que ele seja mnemônico, reconhecível e também único dentro de seu escopo. O nome abreviado recebe um caractere # como sufixo (observe que # é um caractere ilegal em CIM) para evitar conflitos com outros nomes. Se dois ou mais nomes dentro do mesmo escopo geram a mesma abreviação, um dígito adicional é acrescentado ao final do nome para torná-lo único. Por exemplo, AttributeCachingForRegularFilesMin é abreviado para AttCacForRegularFilesMin#.
Todos esses nomes truncados são gravados na tabela de nomes truncados, de forma que o programa possa pesquisar o nome CIM real e encontrar o nome truncado a ser utilizado com o SQL.
As telas são os elementos de esquema mais freqüentemente manipulados pelo código do aplicativo e por consultas. Elas usam o mesmo nome da classe CIM que representam. Por exemplo, a classe CIM.UnitaryComputerSystem é representada por uma tela chamada CIM.UnitaryComputerSystem.
Quando necessário, são criados nomes de índices e de tabelas auxiliares concatenando-se o nome da classe e o nome da propriedade e separando-os por um caractere $. Geralmente, esses nomes são abreviados. Por exemplo, NetworkAdapter$NetworkAddresses é abreviado para NetAdapter$NetAddresses#. Isso não tem nenhum impacto negativo para os usuários de esquemas do ZENworks 7 Desktop Management.
Usuários e funções
No SQL, o usuário que tem o mesmo nome do esquema é o proprietário desse esquema, por exemplo, CIM, ManageWise®, ZENworks, entre outros.
Além disso, há um usuário MW_DBA que tem privilégios e direitos de Administrador de Banco de Dados a todos os objetos Esquema. A função MW_Reader tem acesso apenas leitura a todos os objetos Esquema, ao passo que a função MW_Updater tem acesso leitura-gravação-execução a todos os objetos Esquema.
Os programas aplicativos devem acessar o banco de dados como MW_Reader ou MW_Updater em um banco de dados Sybase, como MWO_Reader ou MWO_Updater em um banco de dados Oracle e como MWM_Reader ou MWM_Updater em um banco de dados MS SQL Server, dependendo de seus requisitos.
Tipos de dados
Os tipos de dados CIM são mapeados para os tipos de dados mais apropriados fornecidos pelo banco de dados. Geralmente, o aplicativo Java não exige o tipo porque usa JDBC para acessar os dados.
Originalmente, o Java não suporta tipos em valor absoluto (sem sinal), portanto, você deve usar classes ou tipos inteiros do próximo tamanho para representá-los. Além disso, verifique se não há problemas durante a leitura ou gravação no banco de dados. Por exemplo, é provável que a leitura ou a gravação de um número negativo em um campo sem sinal do banco de dados cause um erro.
As strings em CIM e em Java são Unicode, portanto, o banco de dados é criado usando o conjunto de caracteres UTF-8. A internacionalização não representa nenhum problema; entretanto, pode criar problemas de distinção entre maiúsculas e minúsculas em consultas.
Todos os bancos de dados preservam as maiúsculas/minúsculas dos dados da string que armazenam mas, nas consultas, podem acessar os dados fazendo ou não distinção entre maiúsculas e minúsculas. No ZENworks 7 Desktop Management, os componentes Consulta de Inventário e Exportação de Dados não são afetados, porque os dados da consulta são obtidos no banco de dados antes de serem consultados, de forma que a distinção entre maiúsculas e minúsculas é automaticamente considerada.
No CIM, as strings podem ser especificadas com ou sem limite máximo de caracteres. Muitas strings não têm tamanho especificado, o que significa que podem ser de tamanho ilimitado. Por razões de eficiência, essas strings ilimitadas são mapeadas para uma string variável com o tamanho máximo de 254 caracteres. As strings CIM com tamanho máximo são mapeadas para strings variáveis de banco de dados de mesmo tamanho. O tamanho no banco de dados é em bytes, e não em caracteres, pois os caracteres Unicode podem exigir mais do que um byte para armazenamento.
Telas
Cada classe CIM é representada no banco de dados por uma tela que contém todas as propriedades não-matriz locais e herdadas dessa classe. A tela tem o mesmo nome que a classe CIM.
As telas podem ser consultadas através da instrução SELECT e atualizadas com a instrução UPDATE. Como as telas não podem ser utilizadas com as instruções INSERT e DELETE, use os procedimentos construtor e destrutor.
75.2.3 Esquema Físico
O esquema físico compreende elementos necessários à implementação do banco de dados. Ele é diferente para cada banco de dados. Um esquema físico típico consiste em:
- Definições de tabela ’t$xxx’ e definições de índice ’i$xxx’
- Definições de acionador ’x$xxx’, ’n$xxx’ e ’u$xxx’
- Definições de seqüência (Oracle) ’s$xxx’
- Procedimentos armazenados e funções
O esquema lógico é colocado numa camada no topo do esquema físico e torna desnecessário que os usuários e aplicativos conheçam o esquema físico.