2.4 Clustering
There are three things that you must consider when using the user application in a cluster environment:
-
The JBoss cluster configuration (see Section 2.4.1, Clustering JBoss)
-
The user application caching configuration (see Section 2.4.3, Configuring the User Application Cluster Group Caching Configuration)
-
The workflow engine configuration (see Section 2.4.4, Configuring Workflows for Clustering)
2.4.1 Clustering JBoss
A cluster is a collection of application server nodes that provide a set of services. The purpose of a cluster is to increase performance and reliability of applications. In general, a cluster provides three key benefits for enterprise applications:
-
High availability
-
Scalability (more capacity)
-
Load balancing
High availability means that an application is reliable and available for a high percentage of the time that it is deployed. Clusters provide high availability because the same application is running on all nodes. If one node fails, the application is still running on other nodes. The Identity Manager user application benefits from higher availability when running in a cluster. However, the Identity Manager user application does not support HTTP session replication. This means that if a session is in process on a node and that node fails, the session information will be lost.
Load balancing is the practice of distributing the workload among the members of a cluster. The goal of load balancing is to improve performance. Load balancing can be achieved by a variety of means (for example, DNS round robin, hardware load balancing). See http://www.onjava.com/pub/a/onjava/2001/09/26/load.html for a discussion of various load balancing methods. Regardless of the method selected, you will want to include load balancing in your cluster configuration.
JBoss Cluster Groups
JBoss clusters are based upon a communications module named JGroups. JGroups is installed with JBoss (it also can be used without JBoss). JGroups provides communications among groups, which share a common name, multicast address, and multicast port.
When you install a clustered JBoss server, JBoss defines two different JGroups groups for use in managing the cluster. One is called DefaultPartition and is defined in /deploy/cluster-service.xml. This cluster group is used by JBoss to provide core clustering services. JBoss also defines a second cluster group named Tomcat-Cluster. This cluster group is defined in /deploy/tc-cluster-service.xml. This cluster group provides session replication for the Tomcat server that runs inside JBoss.
The Identity Manager user application uses a third cluster group. This cluster group uses a UUID name to minimize the risk of conflicts with other cluster groups that users might add to their servers. By default, the cluster group is named c373e901aba5e8ee9966444553544200. This cluster isn't configured using a JBoss service file. Instead, the configuration settings are located in the directory and can be configured using the user application administration features. If you are familiar with JGroups and JBoss clustering, you can adjust the user application cluster configuration using this interface. Changes to the cluster configuration only take effect for a server node when that node is restarted.
The user application cluster group is used solely to coordinate user application caches in a clustered environment. It is independent of the two JBoss cluster groups and does not interact with them in any way. By default, the user application cluster group and the two JBoss groups use different group names, multicast addresses and multicast ports so no reconfiguration is necessary.
User application cluster group settings are shared by any Identity Manager 3 application that shares the directory configuration. The purpose of the local settings option in the user application administration interface is to allow an administrator to remove a node from a cluster, or change the membership of servers in a cluster. For example, you can disable clustering globally, then enable it locally for a subset of your servers sharing the directory configuration.
Application Farming
JBoss allows you to hot-deploy across the a cluster by copying an application EAR, WAR, or JAR into the farm directory of one clustered JBoss instance. Hot-deploying on one machine causes that component to be automatically deployed on all instances within the cluster, while the cluster is running.
This form of application deployment is not recommended with the release of JBoss Application Server (4.0.2) that was included with the user application installation program at the time that this document was written, as there are unresolved problems related to its use. However, we have provided the basic steps that you must perform (see Deploying the User Application to a Cluster Using JBoss Farming) to successfully deploy the user application using JBoss farming technology, as improvements to this technology can be expected after the publication of this document.
MySQL Database
The user application installation program either installs the MySQL database manager and creates a database for use with the user application, or it uses an existing Oracle, Microsoft SQL Server, or MySQL database. The database is responsible for data persistence. All nodes in the JBoss cluster must access the same database instance. The user application uses standard JDBC calls to access and update the database. The user application uses a JDBC data source bound to the JNDI tree to open a connection to the database. If you create the JBoss cluster by using the user application installation program, the data source will be installed for you. If you choose to set up the JBoss cluster manually, you will need to copy the data source file (IDM-ds.xml) to the deploy directory on all nodes in your cluster. Also, if you are using MySQL, you need to copy the MySQL JDBC driver (mysql-connector-java-3.1.10-utf8-clob-fix-bin.jar), located in the JBoss /server/IDM/lib directory, to the JBoss server/IDM/lib directory.
Logging
To enable logging for clusters you need to edit the log4j.xml configuration file, located in the \conf directory for the JBoss server configuration (for example, \server\IDM\conf), and uncomment the section at the bottom that looks like this:
<!-- Clustering logging
-->
- <!--
Uncomment the following to redirect the org.jgroups and
org.jboss.ha categories to a cluster.log file.
<appender name="CLUSTER" class="org.jboss.logging.appender.RollingFileAppender">
<errorHandler class="org.jboss.logging.util.OnlyOnceErrorHandler"/>
<param name="File" value="${jboss.server.home.dir}/log cluster.log"/>
<param name="Append" value="false"/>
<param name="MaxFileSize" value="500KB"/>
<param name="MaxBackupIndex" value="1"/>
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%d %-5p [%c] %m%n"/>
</layout>
</appender>
<category name="org.jgroups">
<priority value="DEBUG" />
<appender-ref ref="CLUSTER"/>
</category>
<category name="org.jboss.ha">
<priority value="DEBUG" />
<appender-ref ref="CLUSTER"/>
</category>
-->
You can find the cluster.log file in the log directory for the JBoss server configuration (for example, \server\IDM\log).
2.4.2 Installing the User Application to a JBoss Cluster
The recommended method of installing the user application to a cluster is to use the user application installation program to install the user application to each node in a cluster. Although we do not recommend deploying the user application to a cluster using JBoss farming, we have included a procedure that you can follow as an alternative method.
Using the User Application Installation Program on Each Node in the Cluster
JBoss comes with three different ready-to-use server configurations: minimal, default and all. Clustering is only enabled in the all configuration. A cluster-service.xml file in the /deploy folder describes the configuration for the default cluster partition. When you install the user application and indicate to the installation program that you want to install into a cluster, the installation program makes a copy of the all configuration, names the copy IDM (by default; the installation program allows you to change the name), and installs the user application into the this configuration.
To install the user application to each node in a cluster using the user application Installation Program:
-
Perform a complete install of the user application (MySQL, JBoss, and the user application) on the first JBoss node. For information about using the user application installation program, see the Identity Manager 3 Installation Guide.
-
If you are using MySQL as your database for the user application, the user application installer creates a new installation of MySQL. Make note of the MySQL root user password that you specify; you will need this information when you install the user application on the rest of the nodes in the cluster.
-
In the installation program IDM Configuration screen, select the “clustering (all)” option.
-
Select other installation options as appropriate for your environment.
-
-
If MySQL isn’t running already, start MySQL using the start-mysql.bat file located in the /IDM/mysql directory.
NOTE:On Linux, the following shell command will be helpful in determining whether the MySQL daemon is running:
ps -A | grep mysqld
If this command returns several lines ending in mysqld, then the daemon is running.
-
Start JBoss and the user application using the start-jboss.bat (Windows) or start-jboss.sh (Linux) file, located in the IDM directory.

-
Perform a custom install of the user application on each additional node in the JBoss cluster.
-
Select only the user application for installation:
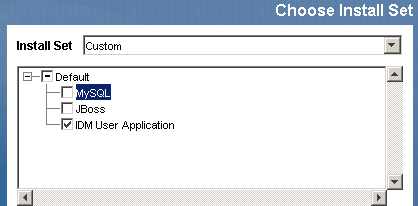
-
Specify the IP address or host name of the server on which the database for the user application is installed.
-
Specify the database user name and password for the user application database. If you are using MySQL, the user name is root, and the password is whatever you specified during the installation process in Step 1.
-
In the installation program IDM Configuration screen, select the “clustering (all)” option.
-
Select other installation options as appropriate for your environment.
-
-
Start each node in the JBoss cluster using the start-jboss.bat (Windows) or start-jboss.sh (Linux), located in the IDM directory.
Deploying the User Application to a Cluster Using JBoss Farming
Do not use JBoss farming with JBoss version 4.0.2 or earlier, as you may experience problems (see http://jira.jboss.com/jira/browse/JBAS-1899). We recommend that you install the user application, using the user application installation program, on each node in the cluster (see Using the User Application Installation Program on Each Node in the Cluster in this Chapter). However, if you want to use farming to deploy the user application to a JBoss cluster using JBoss 4.0.3 or higher, follow the steps below.
NOTE:These steps are for customers who wish to use JBoss 4.0.3 on their own, experimentally. The officially supported version is 4.0.2.
To deploy the user application to a cluster using JBoss farming:
-
Perform a custom install of the user application to one of the JBoss cluster nodes, selecting the user application and MySQL (if you are using MySQL; otherwise, install just the user application) for installation. You can perform the installation with all clusters in the node running, but the node on which you install the user application should be the first node in the cluster to start.
-
Copy the JDBC driver file (for example, if you are using MySQL, the JDBC driver is mysql-connector-java-3.1.10-utf8-clob-fix-bin.jar), located in the /server/IDM/lib directory, to the corresponding directory on each node in the cluster.
-
Copy the cacerts file from the /lib/security directory of the JRE that was installed with the user application to the JRE /lib/security directory of each node in the cluster.
-
Move the IDM.war file and the IDM-ds.xml data source file from the /deploy directory in the server configuration directory to the /farm directory in the server configuration directory. You must actually move the files. Do not leave the originals in the /deploy directory.
-
Start the database for the user application (if you are using the supplied MySQL, start MySQL using the start-mysql.bat file located in the /IDM/mysql directory).
-
Start JBoss and the user application using the start-jboss.bat (Windows) or start-jboss.sh (Linux), located in the IDM directory on the node to which you installed the user application and user application database.
-
Start the other nodes in the cluster.
2.4.3 Configuring the User Application Cluster Group Caching Configuration
Users who are familiar with JGroups and JBoss clustering can modify the cluster group caching configuration, using the user application administration user interface (see Section 13.3.5, Cache settings for clusters). Changes to the cluster configuration only take effect for a server node when the server node is restarted.
2.4.4 Configuring Workflows for Clustering
Workflow engine clustering works independently of the user application cache framework. There are several steps that you must perform to ensure that the workflow engine works correctly in a cluster environment.
-
All servers in the cluster need to be pointing to the same database. If you install the user application to the cluster using the recommended method (see Using the User Application Installation Program on Each Node in the Cluster), you accomplish this by specifying, during the installation process, the IP address or host name of the server on which the database for the user application is installed. If you use farming to deploy the user application to cluster nodes (see Deploying the User Application to a Cluster Using JBoss Farming), you accomplish this by moving the data source file (IDM-ds.xml) from the /deploy directory to the /farm directory on node on which the user application was first installed. This causes the data source to be deployed to all nodes in the cluster.
-
Each server in the cluster needs to be started with a unique engine-id. This can done by setting the com.novell.afw.wf.engine-id system property at server startup. For example, if you wanted to start JBoss and assign the engine id ENGINE1 to the workflow engine for that server, you would use the following command:
run.sh -Dcom.novell.afw.wf.engine-id=ENGINE1 (Linux)
run.bat -Dcom.novell.afw.wf.engine-id=ENGINE1 (Windows)
Once started by an workflow engine running on a particular server, a workflow process instance can only run and complete on that server. This ensures that the workflow process executes safely. However, it does not provide process instance failover support. If a server in the cluster crashes, the process instance will not be restarted until an engine with the same ID is restarted.
If a server computer cannot be restarted because of a serious hardware or software failure, you can start the application server on a new computer, using the same workflow engine ID that was used on the unrecoverable machine. Since the engine ID is a logical name, not a direct mapping to the physical computer on which the engine was running, the interrupted process instance will complete successfully on the new computer.
Process instances are owned by the engine that started the process. However, a user may log on to any user application in a cluster to view process detail, retract processes, or complete tasks assigned to them. Processes that are retracted or tasks that are completed on an engine that does not own the process enter a pending state and resume execution once they are discovered by the engine that owns them.