3.1 Retain Planning and Design Best Practices
There are so many variables that impact performance and design that no single document could adequately cover them. Instead, this document mostly discusses concepts so that the reader can apply them their needs. This document has four major sections:
-
Retain Architecture
-
Hardware Design
-
Retain Configuration
-
Backing Up Retain
This document's intent is to provide insight into how Retain works so you know how to design your system. It will provide some guidelines and best practices; however, it does not attempt to make hardware recommendations or provide specifications of such. It is anticipated that the reader will understand how Retain works, how the various hardware components play a role, and be able to make hardware decisions based on that understanding. Again, no two systems are alike, so one size does not fit all. And, keep in mind, Retain's minimum system requirements are MINIMUMS. Retain will work with those minimums; but, if performance is a priority, then read on and apply these concepts to your specific situation.
3.1.1 Retain Architecture
Retain can run on a bare metal server or on a VM running Windows Server or SuSE Linux. For backup purposes and flexibility, we recommend running it on a VM.
Retain consists of four major components:
-
Server
-
Worker
-
Indexer
-
Database
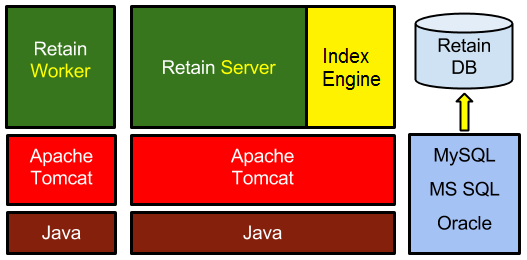
Server
The Server is where the archive system is configured and maintained. It is responsible for storing, indexing, searching, and reading archived items.
Worker
The Worker is the component that interfaces with the messaging host/mail server containing the messages you are archiving. It retrieves the messages and passes them onto the Retain Server.
Indexer
The indexer scans the messages and attachments to make them searchable, indexing each word and some phrases. When a user performs a search in his/her Retain mailbox, the list of messages returned is coming from the indexer, not the database. Understanding that difference helps you make decisions on memory configuration choices for Tomcat (which powers the indexer) and for the database. The index process is the most memory intensive (I.E. uses the most memory) part of Retain.
Database
The database stores most of the Retain configuration as well as the message metadata, which is information about the messages being store (subject, sender, recipients, links to attachments, indexed state of messages, folder location of the message, etc). When a user logs in to his/her Retain mailbox, the list of folders and their messages are being retrieved from the database.
3.1.2 Archive Job Flow
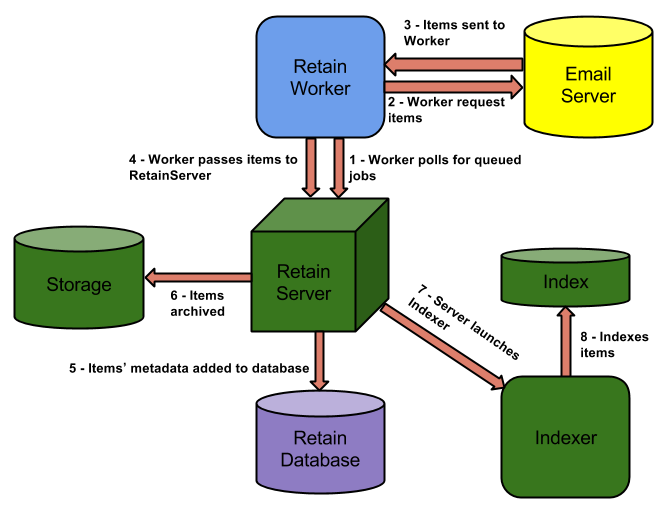
When an archive dredge job is running the work flow follows this pattern.
-
The Worker polls the Server every 10 minutes (default) for new queued jobs it may need to run. It launches the job.
-
The Worker connects to the mail system and does a login to each mailbox. For every mailbox, it requests the items in that mailbox based on the settings in the profile.
-
The mail server responds by sending the items to the Worker.
-
The Worker sends smaller items to the Server. For large items, it sends the items' metadata and awaits instructions from the Server as to whether the item already exists.
If it already exists, the Server notifies the Worker that it does not need to send the item over.
If it does not exist, the Server notifies the Worker to send the item.
-
The Server updates the Retain database with the item's metadata if it does not already exist.
A good example of this is when User A sends message 1 to User B. When User A's mailbox is archived, Message 1 gets stored on disk with a record getting written in the database pointing to the file on disk and associating the message to User A's mailbox. When User B's mailbox gets archived, the Server notices that message 1 is already stored on disk and that a record in the database exists for that message. Now it updates that record and associates it with User B's mailbox.
-
The Server adds the item to the storage area on disk.
-
The Server launches the indexing process (if it is not already running) to begin the indexing process.
-
The Indexer indexes any items that need to be indexed.
3.1.3 Hardware Design
There are four major considerations you need to take into account when designing the hardware for a Retain system:
-
Bandwidth
-
CPU
-
Storage/Disks
-
RAM
-
VM Configuration
Bandwidth
The Worker will be querying your messaging system for messages to be sent to it and receiving every one of those items; however, not all of those items will be sent over to the Server. If the link between the Worker and the messaging system is slow, you should consider placing the Worker on the messaging system's server or on a server that has a fast link to the messaging system.
The only downside to this strategy is software updates. When upgrading Retain software, you will have to go to each server hosting a Worker and upgrade its software. If the Worker is running on the Retain Server itself, then the installer automatically upgrades every Worker on the Server.
CPU
Retain is multi-threaded and able to make use of multiple CPU cores. The base server uses 4 threads, and the Indexer starts with 3 threads. If more than 7 CPU cores are available, additional Indexer threads are spawned. The basic formula is [cores - 4 (minimum 3)].
|
Cores |
Retain Server Threads |
Indexer Threads |
|---|---|---|
|
2 |
1 |
3 |
|
3 |
2 |
3 |
|
4 |
3 |
3 |
|
5 |
4 |
3 |
|
6 |
4 |
3 |
|
7 |
4 |
3 |
|
8 |
4 |
4 |
|
9 |
4 |
5 |
|
10 |
4 |
6 |
We have found that 8 CPU cores provides a sweet spot for performance gains, allowing Retain 4 threads and the Indexer 4 threads.
Storage/Disks
Since Retain is an archiving solution, it will happily fill up your storage system. While it will warn you of impending doom, it is up to you to keep bad things from happening like the hard drive filling up completely. It is difficult to recover from that since not even the OS works very effectively under those conditions. You need to design in the ability to add extra storage easily. Retain stores data in the archive, database and indexes the data for search. Retain also logs what is happening for auditing and troubleshooting purposes.
Since the point of Retain is data safety, we will design around that priority. It is fine in a lab setting to just leave everything on a single drive, but in production, you should desire something more robust. At the very least put the OS on its own partition. It is much easier to recover if a data drive is full rather than a boot drive. It is also important to consider what needs to be done to backup RetainBacking Up Retain.
Size - Archive Files (BLOBs)
The trend with disk storage is that it is increasingly becoming less expensive. Micro Focus cannot tell a customer how much storage space will be needed - it is almost impossible to predict with any degree of accuracy. A general rule of thumb is current size + rate of yearly growth. Understanding the trends of your email growth, the current space consumed by it, and how Retain stores those messages can help you in your planning. If anything, you'll want at least enough storage space to handle your initial archive job of all your email to date and up to the next year or two. You can always add more disk space and Retain storage partitions after that.
Retain's storage design is efficient. Only one instance of any message or attachment is stored on disk, regardless of how many users received the same items and regardless of whether those users are on the same mail server.
Retain also allows you to expire and delete messages stored in the system after a specified time period, saving you disk space as well.
According to some research we found on the Internet, the average number of emails per user is currently 120 per day or 32,000 emails per year given an average workweek and increasing over the years. The average size of an email is 75kb. Do some math and the average is 2.4GB per user per year. From experience, we have seen typical customer email systems increase in size by about 11% per day.
Database
There are a variety of factors that determine how much disk space Retain will consume. The biggest factors are number of messages per day and the length of time you intend to archive your data. It may be difficult to figure out either of those factors. If you have a virtualized environment, you can allocate more space than you think you will use and thin provision the disks. For our cloud customers, we typically set the db partition to 500 GB and go from there. If a partition runs low on disk space at any point, support can direct you on the proper steps to move the data to another partition if necessary.
The numbers provided in the following table are simply representations of three different systems. Remember, no two systems are alike. Two customers with the same number of messages in their system may have vastly different database sizes due to the difference in the message metadata. For example, Customer A may have short distribution lists while Customer B has a lot of emails with hundreds if not thousands of recipients associated with the messages; therefore, this sample data may or may not represent what you may experience with your system. The purpose of providing sample data is to get you into a possible ballpark range. If anything, err on the side of going higher on the storage need.
|
Example Systems |
Server A |
Server B |
Server C |
|---|---|---|---|
|
Message Count |
104,976,966 |
18,261,383 |
2,699,654 |
|
Archive Size |
5.3 TB |
1 TB |
115 GB |
|
File Size per Message (archive) |
4.54 KB |
4.71 KB |
6.21 KB |
|
Database Size |
455 GB |
82 GB |
16 GB |
|
File Size per Message (database) |
56.27 KB |
64.02 KB |
45.06 KB |
File System
When selecting the type of file system on Linux, we recommend going with XFS because it dynamically creates iNodes whereas ext3 forces you to configure those up front. Once you run out of iNodes, nothing can be written to that disk, even if you have plenty of disk space left. XFS is also popularly regarding as performing faster as well.
It is NOT recommended to use ReiserFS, performance on that file system is much worse than XFS.
Other Disk Partitions
Let's talk concepts first, so you can determine if the following recommendation makes sense for you.
Retain archive jobs are disk I/O intensive. You have message content being stored in the archive directory, each message is getting indexed, you have the database getting updated with message metadata, and you have logs being written to continuously. That is a lot of disk access.
Now, let's apply that information to various disk configurations:
Physical ("bare metal") Server
This is your old-school standalone server not running as a VM. In this situation, Retain is installed on a physical machine, not a virtual one. The server has its own locally attached disk. If there is just one disk, you have a lot of disk I/O contention during a job and that will negatively impact performance. In such a case, the recommendations we will make in this section would apply.
VM Guest on Host With Local Disks
Your Retain server is a VM guest running on a physical server that has only local disks. Nothing is on a NAS or SAN. In such a case, the recommendations we will make in this section would apply. You would simply create multiple disks and just ensure that each one gets created on a different datastore.
NAS or SAN
This could be physical box where the storage is mounted/mapped to a NAS or SAN; or, this could be a VM guest where:
-
The VM guest itself is stored on a NAS/SAN; thus, the VM guest's "local disks" are also sitting on a NAS/SAN; or,
-
The VM guest itself is stored on the hosts local disks but the "local disks" of the VM guest are on datastores residing on a NAS/SAN; or,
-
The VM guest is mounting volumes stored on a NAS/SAN.
If the Retain storage will ultimately be on a NAS/SAN and if the volumes are expandable on the fly, then the recommendations we make don't necessarily apply. As you can see, there are so many configurations that a discussion on what exactly to do becomes impossible. The reader really needs to understand what Retain is trying to do and then see what can be done on the hardware end to facilitate best performance.
If it is a NAS/SAN, that doesn't necessarily translate into great disk performance. Many have a NAS but call it a "SAN". So then you have to consider the pipe speed to the storage: 1 gigabit/sec is considered very slow. On top of that, you have to consider how many disks are in the array, their RAID configuration, and the speed of the disks themselves.
For those situation where it makes sense to follow our recommendations:
There is a logical reason for separating your archive files from everything else and a performance reason.
If all the Retain storage is located on the same volume and you run out of space, Retain provides the ability to create additional storage volumes for the archive files. After an additional logical storage volume is created within Retain, all archive files from that point forward as archive jobs run will go to the new location. That works great.
However, the indexes will continue to grow and Retain doesn't have the ability to partition indexes. Some customers have run out of disk space, created new logical storage partitions that point to another volume, but then run into problems with their archive jobs because they are still out of disk space for the INDEXES. Thus, for logical reasons, you want to have your archive files on a separate volume to begin with unless the volume containing the Retain storage is expandable on demand.
If it makes sense to do so (based on all the concepts previously discussed), you'll want to separate your archive files from your indexes and from your database, which means two to three other partitions on your Retain Server in addition to your OS partition. If your database is on a separate server from Retain, then only two other partitions are needed; otherwise, you'll want three additional partitions.
Data Partitioning
We recommend dividing up your storage directories onto separate disks, so beyond the OS disk there should be:
-
Disk 1: Archive
-
Disk 2: Index (250G start). For best search performance, consider making this a solid state drive.
-
Disk 3: Logs, xml, ebdb, export, backup, and license (150 - 200G)
-
Disk 4: Database (if on-board)
Disk 2 should be expandable and you'll want to give it room for the indexes to grow; but, if you cannot do that, then when it runs out of space, you'll simply need to move your index files to another volume with more disk space in the future. For disk 2 - as mentioned previously - you may want to consider an SSD, as that would increase the search performance.
If disk 1 and disk 2 can literally be on different "spindles", then you will also get some performance gains from that because an archive job writes simultaneously to the archive directory, the index directory, and to the database. If each of those are on different physical disks (a.k.a., "spindles"), then this eliminates disk contention bottlenecks. Smaller systems may not need to be concerned with performance while larger systems that have archive jobs running for hours may want the performance gains.
Using disk 3 for logs is especially helpful for larger systems. If you have 6 Workers averaging 5 - 10 messages per second, expect a RetainServer log of around 60G unzipped. Plan for 150 - 200G for your logs directory. For the initial archive job, the rule of thumb is 10G per day per Worker. If you do not use a third disk, then the logs will go to the OS partition and that could spell trouble. Also, if users access their archives often and perform PDF exports, that can grow as well. The xml, ebdb, and license directories are pretty much static with minimal to no growth. The backup directory is a backup of the index directory and other important items. However, if the disk begins to run out of room, you can easily copy this data over to a larger disk at some future time and point retain to that new disk.
Finally, if your database is on the Retain Server, you'll want a third or fourth disk for it (depending on whether you decided to dedicate a disk for your Retain logs).
If performance is an issue, not only will you want all three of these partitions/disks to be on physically different spindles (or at least written to a NAS/SAN with many disks that it can swipe across), but you'll benefit from putting indexes and the database on high speed drives. Your archive directory does not need the performance and can be on less expensive disk media.
Make sure to set the permissions of the new disks correctly in Linux or the installation will fail.
Disk Performance
This comes up a lot; thus, it bears repeating what was mentioned previously. A customer will claim that they are on a fast SAN. Often, it is not a SAN but a NAS and there are many considerations that go into performance. So, knowing that disk I/O is the top issue with archive job performance, it is best to plan out your disk storage accordingly.
Storage design and disk I/O has everything to do with Retain performance as archive jobs are I/O intensive. You have the following processes writing to disk simultaneously:
-
The indexer to the [storage path]/index
-
The database (if on the Retain server)
-
The Retain Server to [storage path]/archive
-
The Retain Server to the logs directory:
-
Linux: /var/logs/retain-tomcat8
-
Windows: [drive]:\Program Files\Beginfinite\Retain\Tomcat8\logs
-
With all of that disk activity, if a single spindle (drive) is having to handle all of it, then you can see that the performance bottleneck would be disk I/O. However, many disk systems these days involve multiple disks using (i.e., RAID 5 or RAID 10) that write the data across multiple disks. The more disks involved, the more you are spreading the load and typically the faster the disk performance will be. You also have a difference in drives (SATA/SAS/SSD). In those cases, you now are looking at whether the disks are local to the server or in a SAN/NAS.
RAID Considerations
Let's say your server employs RAID 5, which provides better redundancy than, say, RAID 10. If there were 4 disks. As you know, RAID 5 uses an extra parity bit that consumes an entire disk, which leaves it with 3 drives on which to stripe across. If one of those drives becomes unavailable, that leaves you with 2. Striping across 2 or 3 drives doesn't lend for great speed, especially if the disks are lower end SATA drives.
SAN / NAS Considerations
If on a SAN/NAS, now you are looking at the network link speed as well. You could have very fast drives, but if your link speed is 1 Gb/s, your bottleneck is going to be your link.
The 1 GB/s network link is slower than a SATA 2 or 3 connection (AKA SATA 3 Gb/s and SATA 6 Gb/s.) Your SATA 2 connection (which is now getting to be a pretty old standard) is 3x faster than a 1000 Mb/s network link (or 1 Gb/s network connection). A fast single HDD can saturate a 1 Gb/s connection but not quite a 3 Gb/s connection (SATA 2.0, or SATA 3 Gb/s) with a sequential read/write. 7,200 RPM platter drives usually top out around 160-170 MB/s (or 1.28-1.36 Gb/s).
Measuring Disk Performance
It really comes down to IOPS. Here is a very simple IOPS calculator: http://www.thecloudcalculator.com/calculators/disk-raid-and-iops.html or you can find one of your own.
So, it really comes down to you understanding your underlying disk storage. This article just gives food for thought. If you are running Retain on a VM guest server like most customers do, then you need to also understand your VM host and VM infrastructure. Is the Retain storage viewed by the server OS running on the VM guest as "local" storage? If so, what type of disk system is holding your VM's datastore? If it is not local storage but the server is connecting to external storage, then you need to take a look at the external system's configuration.
Bottom line: Disk I/O performance is key to Retain's performance and there are several areas to investigate where the bottlenecks could be.
In addition to partition considerations, make sure that your storage is reliable. NFS mounts can be problematic, so you may want to shy away from those. NSS volumes are not supported, so do not use them.
RAM
The amount of memory depends on the number of active mailboxes you are archiving, the mail volume, your underlying hardware, and how your Retain system will be used.
We'll first discuss the concepts so that you can apply them to your system and we'll give you some general guidelines. In most instances, you will need to experiment with various memory configurations until you find what works best in your environment.
Concepts
Retain runs under Tomcat as shown at the beginning of this article and Tomcat runs on Java. The Retain Server will use the Java "heap" for its memory and the indexer will use the OS memory as well as virtual memory (see the Virtual Memory subsection below). For this reason, you should configure Tomcat/Java with the bare minimum to have it run in an acceptable fashion for you. If logins or Retain in general seems sluggish when in the mailbox or using the web admin tool, you may need more heap. The sweet spot for most systems with a single Worker installed on the local Retain server is 8 GB minimum (xms) and maximum (xmx). You want to leave as much RAM as possible for the Indexer, which uses non-heap RAM.
The amount of Java heap you set will depend on total RAM on your system and the number of Workers you install in addition to the default single Worker. As we grow in customer experience with Retain 4, we adjust this article's memory recommendations accordingly.
Right now, development has suggested 1 - 2GB per additional Worker beyond the 8 GB you normally would give to the Java heap for a system with a single Worker local to the Retain server; however, we've had a customer with 110 million messages with 7 Workers local to the Retain server get away with 8 - 10 GB of RAM, but that is really pushing it. They didn't run under that configuration for more than 24 hours, so we cannot tell whether it would have been successful in the long run.
The installer for Retain 4.0.1 and later tunes Tomcat/Java memory based on total RAM and which Retain components are installed. See the online manual's topic, "Tomcat Memory tuning" (note: that link goes to the 4.0.1 documentation, so if the link doesn't exist in the future, go to the online manual and find that topic). Again, as we learn more from customer experience, the installer's default RAM configuration is subject to change.
If you really want the fastest search performance, load it up with RAM, like 64GB or more. Systems with large numbers of messages (100 million or more) seem to be needing 64 GB of RAM or more. If you have a database system running on your Retain Server as well and multiple local Workers, then those will cut away at available RAM for the indexer, so you need to take that into account. The indexer wants to cache indexing data into RAM and memory access is much quicker than disk.
General Guidelines
All of this really depends on the priority you place on Retain performance. If a customer is only interested in getting data into Retain and it doesn't matter how long the archive jobs take (as long as they finish within a 24-hour timeframe) nor does the customer care how long it takes to search for messages (because they do not do it that often), then none of this matters.
The key test is how quickly tomcat shuts down and how much memory the OS is sending to swap. If tomcat is shutting down slowly, that's probably an indication that it has code in swap memory that it is having to call off of disk in order to close out. Reserving more memory for the OS should alleviate that problem; thus, reserve a minimum of 4G for the server OS right up front. On some systems, we have had to allocate more, on others, less. So, the key is to try different configurations on your system to see what makes the difference.
Once you have subtracted the OS memory from your total memory, give 2 - 4G of RAM to the database (if the database is on the same server; otherwise, the remainder can go to Tomcat). Note that Tomcat will need a minimum of 2G.
For small systems (1 - 250 mailboxes), 8G of RAM might be OK if that's all you can afford to allocate that. It is true that a small Retain system can run on 4G, but performance will be awful in most cases. If even decent performance matters, you really should not go lower that 8G unless you are a very small business and have 0 - 50 mailboxes. You might even want to consider trying 12 - 16G and see what difference that makes for you. For some, it will make a big difference. For others, it may make no difference as the bottleneck is elsewhere.
For medium sized systems (250 - 750 mailboxes), 12 - 16G of RAM should be considered.
For larger systems, 16G should be considered a minimum. Many large systems range from 24 - 48G of RAM. The more mailboxes and mail volume, the more RAM you might consider giving your Retain server. But, again, we have to emphasize that every system is unique and RAM may not be the biggest performance factor for them.
Case in point: We have a customer with 700 users that found allocating 24G of RAM made a big difference. In another case, a customer that had 1,500 users needed only 12G. We have systems with thousands of mailboxes and those systems do benefit from increased memory allocation, but their needs vary.
Tomcat Memory Configuration
Tomcat memory is manually configured. The latest version of Retain sets it to 8G by default. It is an industry best practice to set the minimum and maximum memory values to the same value.
In Linux
You set the Tomcat memory parameters in a file called j2ee found at /etc/opt/beginfinite/retain/tomcat8. See Tomcat Memory Tuning for more detail. Tomcat must be restarted after configuring it.
In Windows
You can set Tomcat parameters by running Programs | Tomcat 8.0 | Configure Tomcat. Go to the "Java" tab to set them. Note, we also recommend setting the stack size to 256k (it defaults to 160k in Windows).
Database Memory Configuration
Since most organizations employing Oracle or MS SQL have someone designated as a database administrator (DBA), they typically understand memory configuration. What they need to know is that archiving speed and user mailbox browsing performance is affected by the amount of memory given to the Retain database.
Virtual Memory
If you have the available disk space, we recommend increasing the virtual memory to at least 50GB. In Linux, this is known as swap. In Windows, this is called the page file. Ideally, this swap or page file should be placed on a fast storage for performance reasons.
VM Configuration
VM (Virtual Machine) NIC Settings
We have found that using VMXNET3 for the network adapter in VMs helps performance.
Virtual Machine SnapShots
We have found that VM snapshots can reduce performance of the Retain Server. Keeping the number of snapshots to a minimum is highly recommended.
Resource Restrictions
See "Retain tomcat becomes unresponsive after several mailbox searches", which addresses a VM resource limitation setting that - if set - can affect the performance of Retain and cause it to freeze.