5.3 Planning for Disk Storage
If not monitored, Retain can completely fill its allocated archive storage.
Although Retain warns of disk-full conditions, you are responsible to keep the storage from filling up completely.
Once storage is full, recovery is difficult because server performance is heavily impacted.
It is critical that you design your system so that you can easily add storage as the system grows.
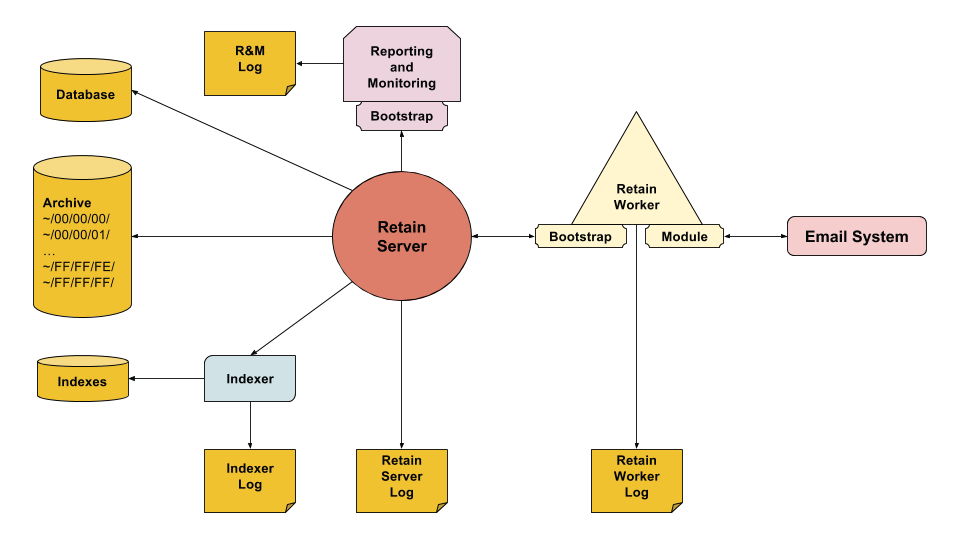
Retain’s success depends on a robust storage design.
Install the OS on its own partition so that it’s easier to recover from a disk-full condition.
Make sure you have a comprehensive backup strategy for Retain. See Backing Up Retain
in Retain 4.9.2: Installation and Upgrade.
5.3.1 Planning Your Archive Size - Archive Files (BLOBs)
As you begin planning your Retain archive, we recommend that you start with the current size of your post offices and other systems, then multiply that by your system’s yearly growth rate and add that amount to cover at least one year, it not two.
It isn’t possible to predict how much archive space requirements will increase over time, but at least this sets a good starting point for your initial archive and growth in the near term.
If you have a virtualized environment, you can allocate more space than you think you will be used and thin provision the disks.
Retain archiving is designed so that only one copy of a message or attachment is archived no matter how many users receive it, or which post office they belong to.
Retain lets you expire and delete messages from the archive after a specified time period.
5.3.2 Database Size
For cloud deployments, we typically set the db partition to 500 GB and go from there.
If a partition runs low on disk space at any point, support can direct you on the proper steps to move the data to another partition if necessary.
The numbers provided in the following table are representations of three different systems. Two customers with the same number of messages in their system may have vastly different database sizes due to the difference in the message metadata.
For example, Customer A may have short distribution lists while Customer B has a lot of emails with hundreds if not thousands of recipients associated with the messages. The purpose of providing sample data is to illustrate differences.
|
Example Systems |
Deployment A |
Deployment B |
Deployment C |
|---|---|---|---|
|
Message Count |
104,976,966 |
18,261,383 |
2,699,654 |
|
Archive Size |
5.3 TB |
1 TB |
115 GB |
|
File Size per Message in the archive |
4.54 KB |
4.71 KB |
6.21 KB |
|
Database Size |
455 GB |
82 GB |
16 GB |
|
File Size per Message in the database |
56.27 KB |
64.02 KB |
45.06 KB |
5.3.3 Choose XFS as the File System on Linux
Micro Focus recommends choosing XFS for Linux servers because it creates iNodes dynamically and performs well.
Micro Focus does not recommend ReiserFS (poor performance with Retain), or Ext3 (iNode inflexibility).
5.3.4 Disk Options
Retain archive jobs are disk-I/O intensive and includes:
-
Storing message content in the archive
-
Indexing each message
-
Updating the database with each message’s metadata
-
Updating various logs continually
In light of this, here are a few recommendations.
Physical ("bare metal") Server
Physical servers have their own locally attached disks. If there is just one disk, then disk I/O contention negatively impacts performance, especially while jobs are running.
VM Guest on Host With Local Disks
If your VM host has only local disks (NAS or SAN),make sure that you create multiple disks and that each one is on a different datastore if possible.
NAS or SAN
This could be physical server where the storage is mounted/mapped to a NAS or SAN; or, this could be a VM guest where:
-
The VM guest itself is stored on a NAS/SAN; thus, the VM guest's "local disks" are also sitting on a NAS/SAN; or,
-
The VM guest itself is stored on the hosts local disks but the "local disks" of the VM guest are on datastores residing on a NAS/SAN; or,
-
The VM guest is mounting volumes stored on a NAS/SAN.
If the Retain storage is on a NAS/SAN and if the volumes are expandable on the fly, there are so many configurations that recommendations aren’t possible, except to understand what Retain is trying to do and then see what can be done on the hardware end to facilitate best performance.
If it is a NAS/SAN, consider the pipe speed to the storage: 1 gigabit/sec is very slow. On top of that, consider how many disks are in the array, their RAID configuration, and the speed of the disks themselves.
Recommendations
If all the Retain storage is located on the same volume and you run out of space, Retain provides the ability to create additional storage volumes for the archive files. After an additional logical storage volume is created within Retain, all archive files go to the new location.
However, the indexes continue to grow and Retain doesn't have the ability to partition indexes. Some customers have run out of disk space, created new logical storage partitions that point to another volume, but then run into problems with their archive jobs because they are still out of disk space for the indexes. Thus, for logical reasons, you want to have your archive files on a separate volume to begin with, unless the volume containing the archive is expandable on demand.
If it makes sense to do so (based on all the concepts previously discussed), you'll want to separate your archive files from your indexes and from your database, which means two to three other partitions on your Retain Server in addition to your OS partition. If your database is on a separate server from Retain, then only two other partitions are needed; otherwise, you'll want three additional partitions.
5.3.5 Data Partitioning
We recommend dividing up your storage directories onto separate disks, so beyond the OS disk there should be:
-
Disk 1: Archive
-
Disk 2: Index (250G start). For best search performance, consider making this a solid state drive.
-
Disk 3: Logs, xml, ebdb, export, backup, and license (150 - 200G)
-
Disk 4: Database (if on-board)
Disk 2 should be expandable and you'll want to give it room for the indexes to grow; but, if you cannot do that, then when it runs out of space, you'll simply need to move your index files to another volume with more disk space in the future. For disk 2 - as mentioned previously - you may want to consider an SSD, as that would increase the search performance.
If disk 1 and disk 2 can literally be on different physical disks, then you get some performance gains from that because an archive job writes simultaneously to the archive directory, the index directory, and to the database. If each of those are on different physical disks, then this eliminates disk contention bottlenecks. Smaller systems may not need to be concerned with performance while larger systems that have archive jobs running for hours may want the performance gains.
Using disk 3 for logs is especially helpful for larger systems. If you have 6 Workers averaging 5 - 10 messages per second, expect a RetainServer log of around 60G unzipped. Plan for 150 - 200G for your logs directory. For the initial archive job, the rule of thumb is 10G per day per Worker. If you do not use a third disk, then the logs are written on the OS partition and that could spell trouble. Also, if users access their archives often and perform PDF exports, that can grow as well. The xml, ebdb, and license directories are pretty much static with minimal to no growth. The backup directory is a backup of the index directory and other important items. However, if the disk begins to run out of room, you can copy this data over to a larger disk at some future time and point retain to that new disk.
Finally, if your database is on the Retain Server, you'll want a third or fourth disk for it (depending on whether you decide to dedicate a disk for your Retain logs).
If performance is an issue, you should place all three partitions on different physical disks (or at least a NAS/SAN with many disks that it can swipe across). You should also put the indexes and the database on high speed drives. Your archive directory does not need the performance and can be on less expensive disk media.
Make sure to set the permissions of the new disks correctly in Linux, or the installation fails.
5.3.6 Disk Performance
Knowing that disk I/O is the top issue with archive job performance, it is best to plan out your disk storage accordingly.
Storage design and disk I/O has everything to do with Retain performance as archive jobs are I/O intensive. You have the following processes writing to disk simultaneously:
-
The indexer to the [storage path]/index
-
The database (if on the Retain server)
-
The Retain Server to [storage path]/archive
-
The Retain Server to the logs directory:
-
Linux: /var/logs/retain-tomcat8
-
Windows: [drive]:\Program Files\Beginfinite\Retain\Tomcat8\logs
-
With all of that disk activity, if a single drive is having to handle all of it, then you can see that the performance bottleneck would be disk I/O. However, many modern disk systems involve multiple disks using (i.e., RAID 5 or RAID 10) that write the data across multiple disks. The more disks involved, the more you spread the load and the faster the overall performance. You also have a difference in drives (SATA/SAS/SSD). In those cases, you now are looking at whether the disks are local to the server or in a SAN/NAS.
5.3.7 RAID Considerations
Let's say your server employs RAID 5, which provides better redundancy than, say, RAID 10. If there were 4 disks. As you know, RAID 5 uses an extra parity bit that consumes an entire disk, which leaves it with 3 drives on which to stripe across. If one of those drives becomes unavailable, that leaves you with 2. Striping across 2 or 3 drives doesn't lend for great speed, especially if the disks are lower-end SATA drives.
5.3.8 SAN / NAS Considerations
If on a SAN/NAS, now you are looking at the network link speed as well. You could have very fast drives, but if your link speed is 1 Gb/s, your bottleneck is going to be your link.
The 1 GB/s network link is slower than a SATA 2 or 3 connection (AKA SATA 3 Gb/s and SATA 6 Gb/s.) Your SATA 2 connection (which is now getting to be a pretty old standard) is 3x faster than a 1000 Mb/s network link (or 1 Gb/s network connection). A fast single HDD can saturate a 1 Gb/s connection but not quite a 3 Gb/s connection (SATA 2.0, or SATA 3 Gb/s) with a sequential read/write. 7,200 RPM platter drives usually top out around 160-170 MB/s (or 1.28-1.36 Gb/s).
5.3.9 Measuring Disk Performance
It really comes down to IOPS. Here is a very simple IOPS calculator: http://www.thecloudcalculator.com/calculators/disk-raid-and-iops.html or you can find one of your own.
So, it really comes down to you understanding your underlying disk storage. This article just gives food for thought. If you are running Retain on a VM guest server like most customers do, then you need to also understand your VM host and VM infrastructure. Is the Retain storage viewed by the server OS running on the VM guest as "local" storage? If so, what type of disk system is holding your VM's datastore? If it is not local storage but the server is connecting to external storage, then you need to take a look at the external system's configuration.
Bottom line: Disk I/O performance is key to Retain's performance and there are several areas to investigate where the bottlenecks could be.
In addition to partition considerations, make sure that your storage is reliable. NFS mounts can be problematic, so you may want to shy away from those. NSS volumes are not supported, so do not use them.