2.4 Gestione in cluster
Quando l'applicazione utente viene utilizzata in un ambiente di tipo cluster, è necessario considerare tre aspetti:
- La configurazione del cluster JBoss (vedere Sezione 2.4.1, Gestione in cluster di JBoss)
- La configurazione della memorizzazione nella cache dell'applicazione utente (vedere Sezione 2.4.3, Configurazione della memorizzazione nella cache del gruppo cluster dell'applicazione utente)
- La configurazione del motore di workflow (vedere Sezione 2.4.4, Configurazione dei workflow per la gestione in cluster)
2.4.1 Gestione in cluster di JBoss
Un cluster è una raccolta di nodi del server per applicazioni che forniscono un insieme di servizi. Lo scopo di un cluster è di aumentare le prestazioni e l'affidabilità delle applicazioni. In generale, i tre vantaggi principali offerti da un cluster alle applicazioni aziendali sono i seguenti:
- Elevata disponibilità
- Scalabilità (maggiore capacità)
- Bilanciamento del carico
Con elevata disponibilità si intende che un'applicazione è affidabile e disponibile per un'alta percentuale del tempo in cui è distribuita. I cluster forniscono un elevato livello di disponibilità poiché la stessa applicazione viene eseguita su tutti i nodi. Se si verifica un errore in un nodo, l'applicazione resta in esecuzione sugli altri nodi. Se l'applicazione utente di Identity Manager viene eseguita in un cluster, si otterrà pertanto il vantaggio di una maggiore disponibilità. Non è tuttavia supportata la replica delle sessioni HTTP. Questo significa che se una sessione è in corso su un nodo e in quel nodo si verifica un errore, le informazioni della sessione andranno perse.
Il bilanciamento del carico consiste nella distribuzione del carico di lavoro tra i membri di un cluster a fine di ottenere un miglioramento delle prestazioni e può essere realizzato attraverso vari metodi (ad esempio, round robin del DNS, bilanciamento del carico hardware). Per informazioni sui vari metodi di bilanciamento del carico, visitare il sito Web all'indirizzo http://www.onjava.com/pub/a/onjava/2001/09/26/load.html. Indipendentemente dal metodo selezionato, sarà necessario includere il bilanciamento del carico nella configurazione del cluster.
Gruppi cluster di JBoss
I cluster JBoss si basano su un modulo di comunicazione denominato JGroups, che viene installato con JBoss (può essere utilizzato anche senza JBoss). JGroups consente la comunicazione tra i gruppi che condividono nome comune, indirizzo e porta di multidiffusione.
Quando si installa un server JBoss in cluster, vengono definiti due gruppi JGroups diversi per la gestione del cluster. Il primo è denominato DefaultPartition ed è definito in /deploy/cluster-service.xml. Questo gruppo cluster viene utilizzato da JBoss per i servizi fondamentali della gestione in cluster. Il secondo gruppo definito da JBoss è denominato Tomcat-Cluster ed è definito in /deploy/tc-cluster-service.xml. Questo gruppo cluster consente la replica delle sessioni per il server Tomcat eseguito all'interno di JBoss.
L'applicazione utente di Identity Manager si serve di un terzo gruppo cluster, che utilizza un nome di tipo UUID per ridurre al minimo il rischio di conflitti con altri gruppi cluster eventualmente aggiunti ai server dagli utenti. Esso è denominato per default c373e901aba5e8ee9966444553544200. Questo cluster non viene configurato mediante un file di servizio di JBoss. Le impostazioni di configurazione sono invece ubicate nella directory e possono essere definite utilizzando le funzioni di amministrazione dell'applicazione utente. Se si ha familiarità con JGroups e la gestione in cluster di JBoss, è possibile regolare la configurazione del cluster dell'applicazione utente mediante tale interfaccia. Le modifiche apportate alla configurazione del cluster diventano effettive per un nodo del server solo quando il nodo viene riavviato.
Il gruppo cluster dell'applicazione utente viene utilizzato unicamente per il coordinamento delle cache dell'applicazione utente in un ambiente a cluster. È inoltre indipendente dai due gruppi cluster di JBoss e non interagisce con essi in alcun modo. Per default, questo gruppo cluster e i due gruppi di JBoss utilizzano nomi di gruppo, indirizzi e porte di multidiffusione diversi e di conseguenza non è necessaria alcuna riconfigurazione.
Le impostazioni del gruppo cluster dell'applicazione utente sono condivise da qualsiasi applicazione Identity Manager 3 che condivide la configurazione di directory. L'opzione delle impostazioni locali nell'interfaccia di amministrazione dell'applicazione utente ha lo scopo di consentire a un amministratore di rimuovere un nodo da un cluster o di modificare l'appartenenza dei server di un cluster. Ad esempio, è possibile disabilitare la gestione in cluster globalmente, quindi abilitarla localmente per un sottoinsieme di server che condividono la configurazione di directory.
Raggruppamento di applicazioni
JBoss consente di eseguire la distribuzione a caldo in un cluster copiando un file EAR, WAR o JAR dell'applicazione nella directory farm di un'istanza di JBoss in cluster. Grazie alla distribuzione a caldo in un solo computer, il determinato componente verrà distribuito automaticamente in tutte le istanze all'interno del cluster, mentre il cluster è in esecuzione.
Non è consigliabile eseguire questo tipo di distribuzione dell'applicazione con la versione di JBoss Application Server (4.0.2) inclusa nel programma di installazione dell'applicazione utente al momento della stesura del presente documento, a causa di problemi non ancora risolti legati al suo utilizzo. Vengono tuttavia forniti i passaggi fondamentali necessari (vedere Distribuzione dell'applicazione utente in un cluster JBoss utilizzando il raggruppamento JBoss) per distribuire l'applicazione utente utilizzando la tecnologia di raggruppamento JBoss, poiché se ne prevedono miglioramenti successivamente alla pubblicazione del presente documento.
Database MySQL
Il programma di installazione dell'applicazione utente consente di installare il gestore del database MySQL e creare un database da utilizzare con l'applicazione utente, oppure di utilizzare un database Oracle, Microsoft SQL Server o MySQL esistente. Il database viene utilizzato per la memorizzazione permanente dei dati. Tutti i nodi del cluster JBoss devono accedere alla stessa istanza di database. L'applicazione utente utilizza chiamate JDBC standard per accedere e aggiornare il database e un'origine dati JDBC associata all'albero JNDI per aprire una connessione al database. Se il cluster JBoss viene creato mediante il programma di installazione dell'applicazione utente, l'origine dati verrà installata automaticamente. Se si invece si sceglie di configurare manualmente il cluster JBoss, sarà necessario copiare il file dell'origine dati (IDM-ds.xml) nella directory di distribuzione di tutti i nodi del cluster. Se si utilizza MySQL, sarà inoltre necessario copiare il driver JDBC di MySQL (mysql-connector-java-3.1.10-utf8-clob-fix-bin.jar) dalla directory /server/IDM/lib di JBoss alla directory server/IDM/lib di JBoss.
Registrazione
Per abilitare la registrazione per i cluster, è necessario modificare il file di configurazione log4j.xml, che si trova nella directory \conf relativa alla configurazione del server JBoss (ad esempio, \server\IDM\conf), e rimuovere i contrassegni di commento dalla sezione nella parte inferiore che si presenta come segue:
<!-- Clustering logging --> - <!-- Uncomment the following to redirect the org.jgroups and org.jboss.ha categories to a cluster.log file. <appender name="CLUSTER" class="org.jboss.logging.appender.RollingFileAppender"> <errorHandler class="org.jboss.logging.util.OnlyOnceErrorHandler"/> <param name="File" value="${jboss.server.home.dir}/log cluster.log"/> <param name="Append" value="false"/> <param name="MaxFileSize" value="500KB"/> <param name="MaxBackupIndex" value="1"/> <layout class="org.apache.log4j.PatternLayout"> <param name="ConversionPattern" value="%d %-5p [%c] %m%n"/> </layout> </appender> <category name="org.jgroups"> <priority value="DEBUG" /> <appender-ref ref="CLUSTER"/> </category> <category name="org.jboss.ha"> <priority value="DEBUG" /> <appender-ref ref="CLUSTER"/> </category> -->
Il file cluster.log si trova nella directory log relativa alla configurazione del server JBoss (ad esempio \server\IDM\log).
2.4.2 Installazione dell'applicazione utente in un cluster JBoss
Il metodo consigliato per l'installazione dell'applicazione utente in un cluster consiste nell'utilizzare il programma di installazione dell'applicazione utente per installare l'applicazione utente in ogni nodo di un cluster. Anche se non è consigliabile distribuire l'applicazione utente in un cluster mediante il raggruppamento JBoss, nel presente documento è stata inclusa una procedura che è possibile utilizzare come metodo alternativo.
Utilizzo del programma di installazione dell'applicazione utente in ogni nodo del cluster
JBoss viene fornito con tre configurazioni server diverse già predisposte: minima, di default e completa. La gestione in cluster viene abilitata solo con la configurazione completa. Nel file cluster-service.xml della cartella /deploy è contenuta la descrizione della configurazione per la partizione cluster di default. Quando si installa l'applicazione utente e si specifica che si desidera eseguire l'installazione in un cluster, il programma di installazione esegue una copia della configurazione completa, assegna alla copia il nome IDM (per default; ma il programma di installazione consente di modificarlo) e installa l'applicazione utente secondo tale configurazione.
Per installare l'applicazione utente in ogni nodo di un cluster utilizzando il programma di installazione dell'applicazione utente:
-
Eseguire un'installazione completa dell'applicazione utente (MySQL, JBoss e l'applicazione utente) nel primo nodo JBoss. Per informazioni sull'utilizzo del programma di installazione dell'applicazione utente, vedere la Guida all'installazione di Novell Nsure Identity Manager.
- Se si utilizza MySQL come database per l'applicazione utente, attraverso il programma di installazione dell'applicazione utente viene creata una nuova installazione di MySQL. Prendere nota della parola d'ordine dell'utente root di MySQL specificata, perché sarà necessario indicarla per l'installazione dell'applicazione utente negli altri nodi del cluster.
- Nella schermata Configurazione cluster del programma di installazione, selezionare l'opzione “Tutti”.
- Selezionare le altre opzioni di installazione in base all'ambiente specifico.
-
Se MySQL non è già in esecuzione, avviarlo utilizzando il file start-mysql.bat che si trova nella directory /IDM/mysql.
NOTA:in Linux, per determinare se il daemon MySQL è in esecuzione, potrà essere utile il comando di shell seguente:
ps -A | grep mysqld
Se questo comando restituisce alcune righe che terminano con mysqld, il daemon è in esecuzione.
-
Avviare JBoss e l'applicazione utente utilizzando il file start-jboss.bat (Windows) o start-jboss.sh (Linux), che si trova nella directory IDM.

-
Eseguire un'installazione personalizzata dell'applicazione utente in ogni altro nodo del cluster JBoss.
- Selezionare l'installazione della sola applicazione utente:
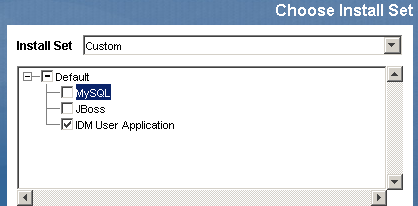
- Specificare l'indirizzo IP o il nome host del server in cui è installato il database per l'applicazione utente.
- Specificare il nome utente e la parola d'ordine per il database dell'applicazione utente. Se si utilizza MySQL, il nome utente è root, mentre la parola d'ordine è quella specificata durante il processo di installazione descritto nel Passaggio 1.
- Nella schermata Configurazione cluster del programma di installazione, selezionare l'opzione “Tutti”.
- Selezionare le altre opzioni di installazione in base all'ambiente specifico.
-
Avviare ogni nodo del cluster JBoss utilizzando il file start-jboss.bat (Windows) o start-jboss.sh (Linux), che si trova nella directory IDM.
Distribuzione dell'applicazione utente in un cluster JBoss utilizzando il raggruppamento JBoss
Non utilizzare il raggruppamento JBoss con JBoss versione 4.0.2 o precedente, poiché potrebbero verificarsi dei problemi (vedere http://jira.jboss.com/jira/browse/JBAS-1899). È consigliabile installare l'applicazione utente utilizzando il relativo programma di installazione in ciascun nodo del cluster (vedere Utilizzo del programma di installazione dell'applicazione utente in ogni nodo del cluster in questo capitolo). Se tuttavia si desidera utilizzare il raggruppamento per distribuire l'applicazione utente in un cluster JBoss 4.0.3 o versione successiva, eseguire le operazioni seguenti.
NOTA:questi passaggi sono destinati agli utenti che desiderano utilizzare JBoss 4.0.3 per conto proprio in via sperimentale. La versione ufficiale supportata è la 4.0.2.
Per distribuire l'applicazione utente in un cluster JBoss utilizzando il raggruppamento JBoss:
-
Eseguire un'installazione personalizzata dell'applicazione utente in uno dei nodi del cluster JBoss, selezionando l'installazione dell'applicazione utente e di MySQL (se si utilizza MySQL; altrimenti installare solo l'applicazione utente). È possibile eseguire l'installazione con tutti i cluster del nodo in esecuzione, ma il nodo in cui si installa l'applicazione utente deve essere il primo nodo del cluster da avviare.
-
Copiare il file del driver JDBC (ad esempio, se si utilizza MySQL, il driver JDBC è mysql-connector-java-3.1.10-utf8-clob-fix-bin.jar) dalla directory /server/IDM/lib nella directory corrispondente di ogni nodo del cluster.
-
Copiare il file cacerts dalla directory /lib/security di JRE (Java Runtime Enviroment) installato con l'applicazione utente, nella directory JRE /lib/security di ogni nodo del cluster.
-
Spostare il file IDM.war e il file di origine dati IDM-ds.xml dalla directory /deploy della directory di configurazione del server nella directory /farm della directory di configurazione del server. Questi file devono essere effettivamente spostati. Non lasciare gli originali nella directory /deploy.
-
Avviare il database per l'applicazione utente (se si utilizza il database MySQL fornito, avviarlo mediante il file start-mysql.bat che si trova nella directory /IDM/mysql).
-
Avviare JBoss e l'applicazione utente utilizzando il file start-jboss.bat (Windows) o start-jboss.sh (Linux), che si trova nella directory IDM nel nodo in cui sono stati installati l'applicazione utente e il relativo database.
-
Avviare gli altri nodi del cluster.
2.4.3 Configurazione della memorizzazione nella cache del gruppo cluster dell'applicazione utente
Gli utenti che hanno familiarità con JGroups e la gestione in cluster di JBoss possono modificare la configurazione della memorizzazione nella cache del gruppo cluster utilizzando l'interfaccia di amministrazione dell'applicazione utente (vedere xref linkend="b2hk1en" xrefstyle="SectTitleOnPage"/>. Le modifiche apportate alla configurazione del cluster diventeranno effettive per un nodo del server quando il nodo viene riavviato.
2.4.4 Configurazione dei workflow per la gestione in cluster
La gestione in cluster del motore di workflow funziona in modo indipendente dal framework delle cache dell'applicazione utente. Per garantire il corretto funzionamento del motore di workflow in un ambiente cluster, è necessario eseguire alcune operazioni.
- Tutti i server del cluster devono puntare allo stesso database. A questo scopo, se l'applicazione utente viene installata nel cluster utilizzando il metodo consigliato (vedere Utilizzo del programma di installazione dell'applicazione utente in ogni nodo del cluster), durante il processo di installazione, è necessario specificare l'indirizzo IP o il nome host del server in cui è installato il database per l'applicazione utente. Se si utilizza il raggruppamento per distribuire l'applicazione utente nei nodi del cluster (vedere Distribuzione dell'applicazione utente in un cluster JBoss utilizzando il raggruppamento JBoss), è necessario spostare il file di origine dati (IDM-ds.xml) dalla directory /deploy nella directory /farm del nodo in cui è stata inizialmente installata l'applicazione utente. In questo modo l'origine dati viene distribuita in tutti i nodi del cluster.
- Ogni nodo del cluster deve essere avviato con un ID motore univoco. A questo scopo, è possibile impostare la proprietà di sistema com.novell.afw.wf.engine-id all'avvio del server. Ad esempio, se si desidera avviare JBoss e assegnare l'ID motore ENGINE1 al motore di workflow relativo a tale server, è necessario utilizzare il comando seguente:
run.sh -Dcom.novell.afw.wf.engine-id=ENGINE1 (Linux)
run.bat -Dcom.novell.afw.wf.engine-id=ENGINE1 (Windows)
Una volta avviata da un motore di workflow in esecuzione su un determinato server, l'istanza di un processo di workflow può essere eseguita e completata solo su quel server. In questo modo viene garantita un'esecuzione sicura del processo di workflow. Non viene tuttavia fornito il supporto di failover dell'istanza del processo. Se un server del cluster si blocca, l'istanza del processo non verrà riavviata fino a quando non verrà riavviato un motore con lo stesso ID.
Se il computer di un server non può essere riavviato a causa di un grave errore hardware o software, è possibile avviare il server per applicazioni su un nuovo computer, utilizzando lo stesso ID del motore di workflow utilizzato per il computer irrecuperabile. Poiché l'ID motore è un nome logico e non una mappatura diretta al computer fisico su cui il motore era in esecuzione, l'istanza di processo interrotta potrà essere completata sul nuovo computer.
Le istanze di processo sono di proprietà del motore che ha avviato il processo. Un utente può tuttavia eseguire il login a qualsiasi applicazione utente di un cluster per visualizzare i dettagli dei processi, ritirare processi o completare task assegnati. I processi ritirati o i task completati su un motore che non è proprietario del processo vengono messi in stato di sospensione e riprendono l'esecuzione una volta rilevati dal motore loro proprietario.