2.8 動詞トークン
この節では、引数ビルダインタフェースで使用できるすべての動詞トークンについて、詳しく説明します。
2.8.1 ターゲットDNのエスケープ
ターゲットデータストアのDNフォーマットのルールに従って文字列をエスケープします。
例
この例は、Identity Manager 3.0に付属している事前定義されたルールからのものです。詳細については、配置-発行者(フラット)を参照してください。
操作ターゲットDNの設定アクションでは、ターゲットDNのエスケープトークンを使用して、ユーザオブジェクトのターゲットDNを作成します。
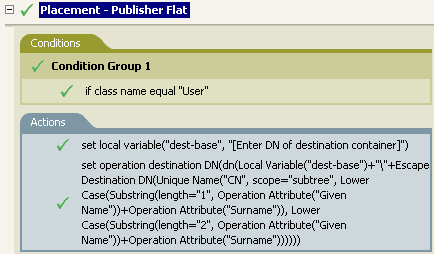

ターゲットDNのエスケープでは、一意の名前の値を取得して、これをターゲットDNの形式に設定します。
2.8.2 ソースDNのエスケープ
ソースデータストアのDNフォーマットのルールに従って文字列をエスケープします。
例

2.8.3 小文字
文字列内の文字を小文字に変換します。
例
この例では、電子メールアドレスを「name@slartybartfast.com」に設定します。nameの部分は、名前と名字の最初の文字になります。ポリシーが表示されます。Create E-mail from Given Name and Surname, and it is available for download at Novell’s support Web site. 詳細については、ダウンロード可能なIdentity Managerポリシーを参照してください。
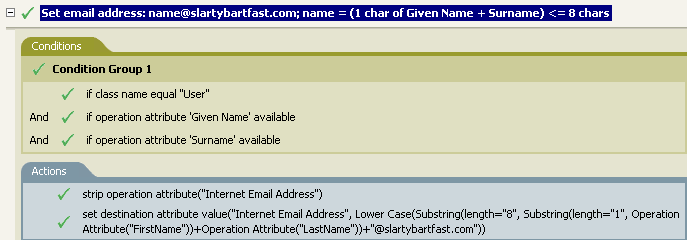

小文字トークンは、ターゲット属性値の設定アクションの情報を、すべて小文字に設定します。
2.8.4 DNの解析
DNを別の形式に変換します。
フィールド
- 開始
- 開始のRDNインデックスを指定します。
- インデックス0はルートに最も近いRDN
- 正のインデックスはルートに最も近いRDNからのオフセット
- インデックス-1はリーフに最も近いセグメント
- 負のインデックスは、リーフに最も近いRDNからルートに最も近いRDN方向へのオフセット
- 長さ
- 含めるRDNの数です。負の数は(セグメント総数+長さ) +1のように解釈されます(たとえば、セグメント数が5のDNでは、長さが-1の場合は-1 = (5 + (-1)) + 1 = 5、長さが-2の場合は-2 = (5 + (-2)) + 1 = 4)。
- ソースDNのフォーマット
- ソースDNの解析に使用されるフォーマットを指定します。
- ターゲットDNのフォーマット
- 解析されたDNの出力に使用されるフォーマットを指定します。
- ソースDN区切り文字
- ソースDNのフォーマットが[カスタム]に設定されている場合に、カスタムのソースDN区切り文字を指定します。
- ターゲットDN区切り文字
- ターゲットDNのフォーマットが[カスタム]に設定されている場合に、カスタムのターゲットDN区切り文字を指定します。
備考
「開始」または「長さ」がデフォルト値{0、-1}に設定されている場合は、DN全体が使用されます。それ以外の場合は、「開始」または「長さ」で指定されたDNの一部分が使用されます。
カスタムのDNフォーマットを指定する場合、区切り文字を構成する8文字は次のように定義されます。
1. タイプ付きの名前のブールフラグ: 0は名前がタイプなし、1はタイプ付きであることを示します。
2. Unicode No-Map文字のブールフラグ:0は、マップ不可能なUnicode文字を、出力しない、または¥FEFFなどのエスケープ処理された16進数字の文字列として変換しないことを意味します。eDirectoryでは、Unicode文字の0xfeff、0xfffe、0xfffd、および0xffffは使用できません。
3. 相対RDN区切り文字
4. RDN区切り文字
5. 名前ディバイダ
6. 名前の値の区切り文字
7. ワイルドカード文字
8. エスケープ文字
RDN区切り文字と相対RDN区切り文字が同じ文字である場合、名前の向きは右から左、それ以外の場合は左から右になります。
区切り文字セットが8文字を超える場合、超過した文字はエスケープ処理が必要な文字と見なされるだけで、それ以外の特別な意味は考慮されません。
例
この例では、DNの解析トークンを使用して、ターゲット属性値の追加アクションの値を作成します。この例は、Identity Manager 3.0に付属している事前定義されたルールからのものです。詳細については、コマンド変換-部署別コンテナの作成-パート1とパート2を参照してください。

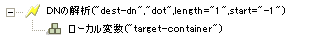
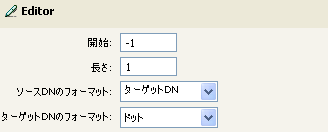
DNの解析トークンは、ソースDNから情報を取得し、これをドット表記に変更します。DNの解析からの情報は、OUの属性値に保存されます。
2.8.5 すべて置換
文字列内の正規表現と一致したものをすべて置換します。
フィールド
- 正規表現
- 置換される部分文字列と一致させる正規表現を指定します。
- 置換文字列
- 置換する文字列を指定します。
備考
正規表現の作成についての詳細は、次を参照してください。
[パターン]のオプションにはCASE_INSENSITIVE、DOTALL、およびUNICODE_CASEが使用されますが、適切な埋め込みエスケープを使用して逆の意味を指定することができます。
例
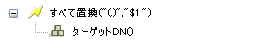
2.8.6 最初を置換
文字列内の正規表現と最初に一致したものを置換します。
フィールド
- 正規表現
- 置換される部分文字列と一致させる正規表現を指定します。
- 置換文字列
- 置換する文字列を指定します。
備考
一致したインスタンスは、[置換文字列]フィールドで指定された値で指定された文字列に置き換えられます。
正規表現の作成についての詳細は、次を参照してください。
[パターン]のオプションにはCASE_INSENSITIVE、DOTALL、およびUNICODE_CASEが使用されますが、適切な埋め込みエスケープを使用して逆の意味を指定することができます。
例
この例では、電話番号(nnn)-nnn-nnnnをnnn-nnn-nnnnを再フォーマットします。このルールは、Identity Manager 3.0に付属している事前定義されたルールです。詳細については、入出力変換-電話番号の形式を(nnn) nnn-nnnnからnnn-nnn-nnnnに変更を参照してください。
[最初を置換]トークンは、[操作属性の再フォーマット]アクションで使用されます。

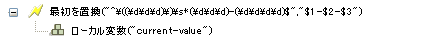

正規表現^\((\d\d\d)\)\s*(\d\d\d)-(\d\d\d\d)$は、(nnn) nnn-nnnnを、正規表現$1-$2-$3はnnnを示しています。このルールでは、電話番号の形式を(nnn) nnn-nnnnからnnn-nnn-nnnnに変更します。
2.8.7 部分文字列
文字列の一部を抽出します。
フィールド
- 開始
- 開始文字のインデックスを指定します。
- インデックス0は1文字目です。
- 正のインデックスは文字列の先頭からのオフセットです。
- インデックス-1は最後の文字です。
- 負のインデックスは、最後の文字から文字列の先頭方向へのオフセットです。
たとえば、開始が-2に設定されると、最後の文字から読み込みが開始されます。-3が指定されると、最後から2文字目で開始されます。
- 長さ
- 部分文字列に含める、開始位置からの文字数。負の数は(文字総数+長さ) + 1のように解釈されます。たとえば、-1の場合は全長または元の文字列を表します。-2が指定されると、「全体の長さ-1」になります。5文字の文字列の場合、長さが-1の場合は-1= (5 + (-1)) + 1 = 5、長さが-2の場合は-2 = (5 + (-2)) + 1 = 4になります。
例
この例では、電子メールアドレスを「name@slartybartfast.com」に設定します。nameの部分は、名前と名字の最初の文字になります。これは「Policy: Create E-mail from Given Name and Surname (ポリシー: 名前と名字から電子メールを作成)」という名前のポリシーで、NovellのサポートWebサイトでダウンロードできます。詳細については、ダウンロード可能なIdentity Managerポリシーを参照してください。

部分文字列トークンは、ターゲット属性値の設定アクションで2度使用されます。名前属性の最初の文字列を取得し、名字属性の8文字を追加して、1つの部分文字列を作成します。
2.8.8 大文字
文字列内の文字を大文字に変換します。
例
この例では、ユーザオブジェクトの名前と名字の属性を大文字に変換します。これは「Policy: Convert First/Last Name to Upper Case (ポリシー: 名前と名字を大文字に変換)」というポリシーで、NovellのサポートWebサイトでダウンロードできます。詳細については、ダウンロード可能なIdentity Managerポリシーを参照してください。

