3.11 Miscellaneous Tiered Electronic Distribution Issues
-
Section 3.11.1, Directory Sync Granularity for File Distributions
-
Section 3.11.2, Understanding Dependencies in Tiered Electronic Distribution
-
Section 3.11.4, Controlling I/O Rates and Concurrent Distributions
-
Section 3.11.6, Changing DNS Names or IP Addresses for Tiered Electronic Distribution Servers
-
Section 3.11.7, When a Tiered Electronic Distribution Process Fails
3.11.1 Directory Sync Granularity for File Distributions
The File Distribution has been enhanced with directory sync granularity:
Understanding Synchronization and Directory Sync Granularity
A File Distribution, with or without synchronization enabled, adds or updates files and directories on a Subscriber server. However, with synchronization enabled it also causes the deletion of files and directories. Therefore, file and directory deletion on the Subscriber server is the main function of synchronization.
Directory sync granularity allows you to specify synchronization at any directory level in the Distribution to provide synchronization “from here down.”
How the Synchronization and Directory Sync Granularity Processes Work
Table 3-16 illustrates what a synchronized File Distribution does to the Subscriber server’s file system if synchronization is enabled in the Distribution:
Table 3-16 Directory Sync Granularity Comparison
Upon extraction of the File Distribution, the following occurs on the Subscriber server’s file system:
-
The missing virus pattern file is restored in the \viruspatterns directory.
The \viruspatterns directory is also made to exactly match the files and subdirectories contained in the Distribution by deleting any files or subdirectories on the Subscriber that are not contained in the Distribution.
-
The nw65sp1.exe file is updated in the \nw65sp directory. Nothing else is synchronized in that directory, because synchronization was not enabled for the \nw65sp directory itself.
-
The \nw65sp2 directory and its files and subdirectories are restored from the Distribution under the \nw65sp directory on the Subscriber.
Directory sync granularity also allows you to retain unsynchronized directories while synchronizing their peer directories. For example, you could select to synchronize the data:\zenworks\viruspatterns and data:\zenworks\nw65sp\nw65sp2 directories, but not the data:\zenworks\nw65sp directory.
However, if you synchronize the parent data:\zenworks directory, all of its subdirectories must also be synchronized, because synchronization occurs from the specified directory and downward. Therefore, when you select directories to be synchronized, you cannot select a parent directory to be synchronized, then select some of its child directories to not be synchronized.
All child directories are automatically synchronized when a parent directory is set to be synchronized, and a parent directory automatically loses its synchronization when one of its child directories has synchronization turned off for it.
For example, Table 3-17 illustrates this:
Table 3-17 Directory Sync Granularity Plan Comparisons
The next few sections describe synchronization scenarios:
Synchronizing All Directories Under the Distribution’s Target Directory
For the source, choose the directories on the Distributor server’s file system to be synchronized. For the destination, the directories to be synchronized might or might not already exist in the Subscriber server’s file system.
If the files already exist, when the Distribution is sent, their content is made to match that of the corresponding directory on the Distributor server’s file system. If they do not exist, they are added on the Subscriber server’s file system.
Determine where these directories should exist on the Subscriber server’s file system. In other words, there is a parent directory under which the synchronized directories are located, or there are the synchronized directories located at the root of the Subscriber’s file system. Variables can be used to specify the target on the Subscriber server’s file system where the Distribution is to be extracted.
In Figure 3-34, the \viruspatterns and \supportpacks directories on the Distributor server are created and synchronized under the vol1:\servers directory on the Subscriber server.
Figure 3-34 Synchronizing All Directories
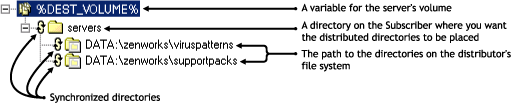
Using Directory Sync Granularity to Synchronize Directories at Various Levels
You can synchronize at the target level (%DEST_VOLUME%). In the example above, we have defined it as vol1:\servers. In that case, the only subdirectories that will exist under that directory are viruspatterns and supportpacks. All other existing subdirectories are deleted.
To retain other directories under vol1:\servers, you would not enable synchronization at the target level (%DEST_VOLUME%). Instead, you would drop down to the subordinate directories and synchronize those. For example, Figure 3-35 illustrates synchronizing only the \viruspatterns directory. That means there could be other directories under vol1:\servers that would be unsynchronized, such as \supportpacks.
Figure 3-35 Using Directory Sync Granularity
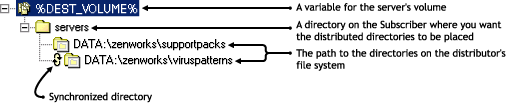
Synchronizing a Subscriber Server Directory with Certain Distributor Server Files
If the File Distribution has certain files on the Distributor server selected to be associated with a directory in the Distribution, you would not normally synchronize that directory in the Distribution. If you did, you could lose valuable data in that directory on the Subscriber server.
For example, Figure 3-36 illustrates this:
Figure 3-36 Synchronizing a Subscriber Server Directory

The Possible Data Loss method would cause all files in the \nw65sp directory and any of its subdirectories to be deleted from the Subscriber server, except for the nw65sp1.exe file. The Preserving Other Files method just updates the nw65sp1.exe file in the \nw65sp directory, leaving all other files and subdirectories unchanged on the Subscriber server.
Synchronizing Directories for a File Distribution
-
In ConsoleOne®, right-click a Distribution object, then click .
-
Select the tab, then select for the type of Distribution.
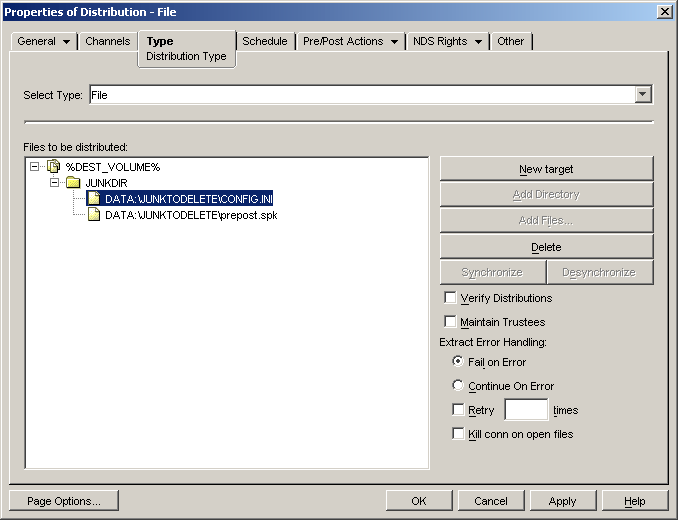
-
Click and %DEST_VOLUME% as the default variable that contains the target path on each Subscriber server.
WARNING:If you want to synchronize at the target level, make sure this variable does not contain the root of the Subscriber server’s file system.
-
Select the and buttons to create the directory structure in the box.
The button is for the Subscriber server’s target paths and directories, and the button is for browsing the distributor’s file system and selecting directories and files that are to be included in the Distribution.
-
If necessary, click the plus signs to expand the directory structure.
By default, no directories in the listing are selected for synchronization.
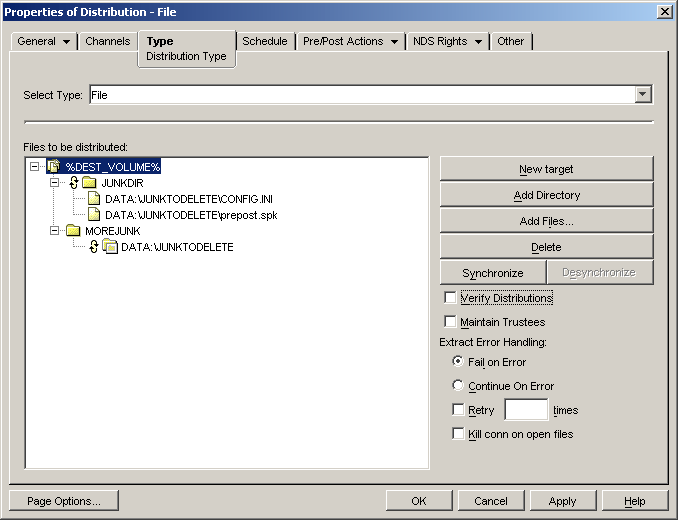
-
To specify a directory to synchronize, select the directory in the box, then click the button.
The icon (
 ) is placed in front of that directory name.
) is placed in front of that directory name.
The and buttons are dimmed when you select a filename instead of a directory name. You can only synchronize directories.
Because directory synchronization is done for the directory you select and all of its subdirectories (in other words, “from here down”), there is no need to synchronize any directories below a directory that you select for synchronization.
When you synchronize a directory and expand the directories below it, the icon is displayed before each directory’s name.
-
To reverse your selection of a directory to be synchronized, select the directory name that has a icon, then click the button.
If you desynchronize a directory and its parent directory was synchronized, the parent directory is also automatically desynchronized. This includes all directories (grandparents) up the path that might have been synchronized. In other words, you cannot synchronize a directory, then desynchronize any directory below it without also causing the directory to be desynchronized.
-
Repeat Step 6 for each directory to synchronize.
-
Continue with configuring the Distribution.
For more information on configuring Distributions, see Creating and Configuring the Distribution.
-
Click when finished configuring the Distribution.
For this Distribution, directory synchronization occurs with only the directories where you placed the icon (
), including all of their subdirectories.
3.11.2 Understanding Dependencies in Tiered Electronic Distribution
Policy and Distribution Services agents (Policy/Package Agent and Distributor Agent) are dependent on one another and upon eDirectory. It is important to understand the following dependencies when using Policy and Distribution Services to manage your network:
Synchronization of Tiered Electronic Distribution Objects in eDirectory
Server Management uses eDirectory as the repository for information needed by the Tiered Electronic Distribution and Server Policies components. Because eDirectory is a distributed database and can have partitions and replicas throughout the network, it takes time to synchronize all of the replicas each time Server Management objects are created or modified.
Unloading Parent Subscribers
You must change the parent Subscriber attribute in the Subscriber object to change the parent Subscriber. Then, the next time a Distribution is sent, the distribution route to the Subscriber reflects the new parent Subscriber.
If a parent Subscriber Java process is unloaded (exited), the subordinates of the parent Subscriber do not renegotiate to another parent Subscriber. The subordinates wait until that parent Subscriber is loaded again and continue to use it. The reason for this is that if the parent Subscriber was the only server between twenty Subscribers and the Distributor (which is located across the WAN), you do not want all of the Subscribers to go across the WAN to get their Distributions if the parent Subscriber is unavailable.
3.11.3 System Resources and Server Behavior
Using Policy and Distribution Services can affect the behavior of your system:
-
Tiered Electronic Distribution usage can affect system behavior because of the traffic created in sending Distributions
-
Some server policies are designed to control the behavior of servers, such as how a server should be brought down
-
Some server policies are designed for NetWare server configuration, such as SET parameters, content of the autoexec.ncf file, and so on
Installing and using Tiered Electronic Distribution can affect any of the following:
-
CPU utilization
-
Disk space resources
-
Network traffic
-
Other I/O activity
To optimize your installation of Tiered Electronic Distribution, you should consider the following issues when selecting Distributor and Subscriber servers:
-
Which servers are the best candidates for the heavy workload of a Distributor?
Consider CPU speed for building and sending Distributions, and sufficient disk space for storing all of the Distributor’s Distributions.
The server can perform other non-Server Management network functions, be running other Server Management or non-Server Management software, or be solely dedicated to the Distributor function.
-
Which servers do you want to manage using server policies?
Consider installing the Subscriber software to each server that you want to manage with policies, or where you want to distribute software packages. The policy engine is installed with the Subscriber software; also, the Subscriber software is used to extract and install software packages.
-
Which servers could best handle the additional workload of being a parent Subscriber? (A parent Subscriber is a Subscriber that acts as a proxy for the Distributor to store and pass Distributions so that the Distributor does not need to send its Distributions to every Subscriber.)
Consider CPU speed for sending the Distributions, and free disk space for storing the Distributions that the parent Subscriber passes on.
-
Does each of your LAN segments have servers that are capable of being a parent Subscriber?
Consider WAN traffic when deciding where to locate parent Subscribers.
-
Do you have other processes using up bandwidth on some LANs and WAN links?
Consider Distribution priorities and setting sending and receiving rates to minimize the affect Distributions can have on bandwidth for WAN links.
3.11.4 Controlling I/O Rates and Concurrent Distributions
If you need to control bandwidth usage for Distribution traffic, you can set the I/O rates and the maximum number of concurrent Distributions for Distributors and/or Subscribers.
Attributes of both the Distributor and Subscriber objects provide the following controls:
-
Input rate: For sending and receiving Distributions, you can set the maximum bytes per second. The Distributor Agent sends the Distributions, and the Policy/Package Agent receives and extracts them. This allows you to have some control over the bandwidth used by these agents.The default is the maximum that the connection can handle. However, this does not control the rate at which FTP, HTTP, and RPM Distributions are built by the Distributor.
-
Output rates based on Distribution’s priority: Sets the default output rate to minimize network traffic for Tiered Electronic Distribution objects. This determines the send rate for Distributors and parent Subscribers. The default value is the maximum that the connection can handle. Blank means that bandwidth is taken from third-party applications.
There are three output priorities where you can specify a rate:
-
High priority: These Distributions are sent before any Medium or Low priority Distributions.
-
Medium priority: These Distributions are sent after all High priority and before any Low priority Distributions.
-
Low priority: These Distributions are sent after all High and Medium priority Distributions.
For more information, see Section 3.4.5, Prioritizing Distributions.
-
-
Maximum number of concurrent Distributions: This determines how many simultaneous Distributions the Distributor Agent can send. The default is unlimited (blank field). The Subscriber always receives as many Distributions as it is sent; however, it only concurrently passes on the number that you choose here.
If there is only one Subscriber, the Distributor sends Distributions at the selected rate. If there are two Subscribers, the Distributions are sent at one half the rate. In other words, to determine the slowest distribution rate, divide the Distributor’s output rate by the maximum number of concurrent Distributions.
Because Subscribers always receive another concurrent Distribution, the rate applies even though you cannot limit the number of incoming connections.
3.11.5 Minimizing Messaging Traffic
Tiered Electronic Distribution provides message notifications so that administrators and selected end users are kept informed. Notifications are sent in several ways:
-
Information written to log files
-
Notifications sent via e‑mail messages
-
SNMP traps used and displayed on both local and remote consoles
The following sections explain message notification usage:
Message Notification Levels
There are seven levels of message notification available. Each level adds its own information to the previous level.
Regardless of the destination for a message, resources are directly affected by the level you choose.
For information on setting message notification levels, see:
Managing Message Notification Level Log Files
The level you choose for a log file affects the rate at which the log file grows. Because log files have no maximum size, you can control the size of a log file by choosing to delete entries after x number of days. For information on setting message notification levels for log files, see:
Sending Notifications Over LANs and WANs
The greatest impact on network traffic can come from the levels you choose for SNMP traps and for the remote console. For information on setting message levels for SNMP traps, e‑mail messages, and the server’s console, see:
SNMP Traps
SNMP messages are sent only if there is an SNMP policy in effect for the receiving server, regardless of the level you choose for the messages. SNMP traffic is affected by both the level you choose and by the SNMP configuration in the policy on the server. There is one SNMP packet per message per destination in the SNMP Trap Target policy. IPX™ addresses are not supported for trap targets.
E-Mail Messages
E-mail messages can also affect network traffic. Like SNMP, e‑mail sends only one e‑mail per message per e‑mail user defined. E‑mail is also configured by a server policy. You must define and enable the policy on the sending server for e‑mail messages to be sent.
3.11.6 Changing DNS Names or IP Addresses for Tiered Electronic Distribution Servers
Whenever there is a change to the identity of either a Distributor or Subscriber server, you must perform certain tasks so that the distribution processes for these servers can continue as before.
In the distribution process, Tiered Electronic Distribution servers identify themselves to each other by their DNS names or IP addresses. The following sections explain situations that can arise from changing these server identifiers.
If You Are Using DNS Names to Identify Your Servers
-
If you change the DNS name of a Distributor server, Subscriber servers cannot recognize the Distributor as a valid source for receiving Distributions.
-
If you change the DNS name of a Subscriber server, the Distributor cannot locate the Subscriber server for sending Distributions to it. This is because the Distributor obtains the Subscriber server’s address from the eDirectory object.
If you change the IP address of a Distributor or Subscriber server when you are using its DNS name to identify it to Server Management, this change does not affect the distribution processes.
If You Are Using IP Addresses to Identify Your Servers
-
If you change the IP address of a Distributor server, Subscriber servers cannot recognize the Distributor as a valid source for receiving Distributions.
-
If you change the IP address of a Subscriber server, the Distributor cannot locate the Subscriber server for sending Distributions to it. This is because the Distributor obtains the Subscriber server’s address from the eDirectory object.
Because reinstating valid certificates is involved in resolving server identity changes, see Section 7.1.7, Handling Invalid Certificates for instructions.
3.11.7 When a Tiered Electronic Distribution Process Fails
It is possible, for many common computer-related reasons, that a Tiered Electronic Distribution process could fail. The following are a few possibilities:
-
A Distribution could be interrupted. If so, when it restarts it picks up where it left off.
Before distribution, the Distribution package resides at the Distributor. After distribution, the Distribution package still resides at the Distributor with a copy now at the Subscriber. It is during the distribution process that an interruption could halt copying. When the Distributor tries to re‑send the Distribution (the next time the Channel schedule starts), it picks up where it left off and does not re‑send the entire Distribution.
If re‑sending a Distribution is interrupted, the sender retries every two minutes for 30 minutes. If it is not successful in reestablishing connection to the target server, it stops retrying. The next time the Channel’s schedule starts, it picks up where it left off in sending the Distribution when it was originally interrupted.
-
An extraction could be interrupted. If so, the extraction does not pick up where it left off.
Distributions are made across the wire from server to server, while extractions are performed on the server from Distributions already sent. Therefore, when an extraction is interrupted, it simply fails. The Subscriber does not roll back (or undo) the failed extraction, unless the Distribution was a software package (.cpk file). It tries the extraction again the next time the Subscriber’s extraction schedule starts.
Files are extracted to the volume and directory specified when the Distribution package was created. File groupings and software packages both allow you to specify to which volume and directory the package should be extracted. Therefore, when an interruption occurs during extraction, it fails in the same way as if you were copying a file in the operating system.
-
The File type offers the following:
- - Retry X times
- - Kill the connection on files that are open
- - Error handling (Fail on error; perform a routine on error)
All options deal with extraction and how to handle it.