
Process Manager User's Guide
CHAPTER 1
Welcome to the SilverStream Integration Manager Process Manager. This Guide is a companion to the Integration Manager User's Guide, which explains the core features of Integration Manager. The rest of this guide assumes familiarity with core Integration Manager functionality, so if you haven't looked at the Integration Manager User's Guide yet, please familiarize yourself with it before using this Guide.
Before you begin working with the Process Manager, you must have it installed in your existing Integration Manager environment. Likewise, before you can run any server-based processes, you must already have installed the Integration Manager Process Server software on your application server.
To be successful with the Process Manager, you should be familiar with the following:
The particular app server environment (e.g., SilverStream, WebSphere, or WebLogic) into which you will be deploying
The use of Integration Manager to create and deploy services
Basic structured-programming concepts and object-oriented design patterns
It will also help if you already have some knowledge of the Web Services Flow Language. The complete specification can be seen at
http://www-4.ibm.com/software/solutions/webservices/pdf/WSFL.pdf
This chapter presents an overview of key BPM (or "workflow") concepts so that you can better understand the relationship of Web Services, J2EE applications, and Integration Manager applications to automated workflows.
The aim of Business Process Management is to model business operations as well-defined systems of tasks in which participants interact according to a prescribed choreography to achieve a desired goal.
The top-level unit of work in such a model is usually called a process, emphasizing the dynamic nature of the underlying interactions. Because of the directed flow of work through such a system, the resulting model is often said to encapsulate a workflow.
A non-automated workflow might look something like the following.
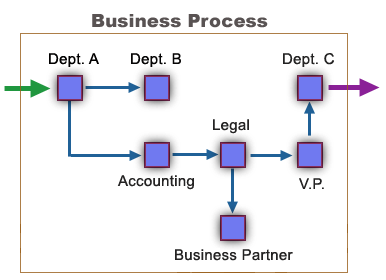
In this hypothetical flow model, various parties (inside and outside the company) accomplish various tasks in a well-defined sequence. The input that triggers the overall process might be a phone call; the output might be a signed contract. The process has identifiable players with defined roles and responsibilities. If each participant does its job, the desired objective will be achieved.
An automated business process attempts to model the same interactions in terms of enterprise applications (each one, again, with its own roles and responsibilities). For maximum flexibility, the applications might be (but need not always be) implemented as Web Services. To accommodate human input, some of the applications might have a user-facing presentation layer. In some cases, the entire model might be realized in software, with no need for human intervention.
The ultimate aim of BPM is to make possible the automation of complex and/or long-running business processes. The benefits of process automation go far beyond the obvious one of reducing demands on human resources. They include:
Scalable throughput—Capacity no longer hinges on personnel headcount. Logjams during "busy times" can be avoided.
Consistency—Once business rules are formalized as part of a process, they are adhered to reliably. TPA (Trading Partner Agreement) provisions can be enforced and company performance documented.
Adaptability—Processes can be designed to automatically detect and route around unexpected bottlenecks.
Upgradability—Processes can be rewired quickly to adapt to changes in business requirements. Individual components of a process can be modified or "changed out" without necessitating a total rewrite of the process itself.
Powerful audit capabilities—Comprehensive reporting across activities, process instances, and business units is possible without the need to pull together disparate data sets from a variety of sources.
Better ability to respond to customer needs—Processes can be initiated by the customer or trading partner in real time and executed on a 24/365 availability basis. Turnaround times can in some cases be shortened from days to hours, or hours to minutes.
New opportunities for Business Process Improvement—The powerful audit and reporting capabilities afforded by BPM can yield new categories of process-related analytics that expose inefficiencies and opportunities for improvement within the organization.
Process design and application design start from different points of reference. The design of an enterprise application usually involves a narrowly focused, data-centric view of a problem and a correspondingly scoped data-oriented solution. Process design, on the other hand, is motivated by the need to fulfill a business objective: patent an invention, process a claim, conduct an auction. The input to the process may be a phone call; the output might be 55-gallon drums on a truck. Carrying out the process may require completion of many tasks. Data requirements may vary greatly along the chain of tasks.
Process design is more than just "data in, data out." It requires thinking about the Big Picture, including not only which applications one might use in modelling a process, but the time order in which those applications must run; the guarantees made by, and responsibilities of, the applications that make up a process; the possible interdependencies of the applications; and the various ways in which a process might terminate prematurely even though no application has failed.

The concept of modularity is key to process modelling. For example:
The various constituent activities that make up a given business process (or workflow model) can, themselves, be processes. This is sometimes called recursive composition.
A particular activity may play a role in multiple processes (which may be unrelated to each other). For example, the "credit check" activity of Process A might also be used by Process B and Process C. This is activity reuse.
The implementation of an activity can be changed without affecting the process model itself. For example, new business logic, reflecting a change in company policy (or perhaps a change in algorithms), can be instituted in the "credit check" activity of a process; but the process itself doesn't have to be modified.
NOTE: The principle of dividing large, custom-built chunks of work into smaller general-purpose chunks of work is well known to application developers as factoring. The goal of factoring is to promote reuse of costly resources.
The activities that make up a process may involve public-facing Web Services, or they may be limited to "behind-the-firewall" services running on a local app server. External trading partners may or may not be participants, and the process can be long-running, with lots of "callbacks" into the system, or it could be of relatively short duration (i.e., straight-through processing).
An example of an automated business process is shown in the following graphic.
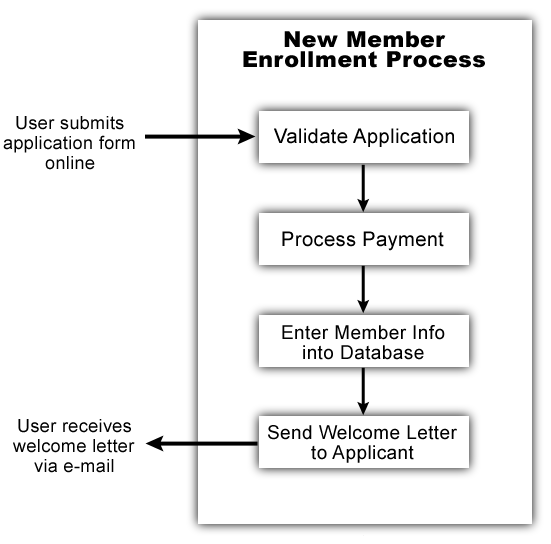
In this scenario, a membership organization accepts member applications online. The applicant, upon submitting HTML form data to the organization's web site, triggers an automated process consisting of four activities:
The first activity checks the application for completeness and perhaps looks in a database to see if the applicant is already a member.
The second activity processes the user's electronic payment information.
Once payment has been received, relevant information about the new member is entered into the main membership database.
The final activity sends a personalized welcome message to the new member via e-mail.
In this admittedly simple example, any of the four component activities of the New Member Enrollment Process might represent an automated process in its own right. One of the activities (Process Payment) might very well rely on a Web Service offered by a business partner. Others might be local to the app server.
Modelling a high-level business function in terms of tasks that can be linked together via software is a powerful metaphor that plays well to the strengths of the Web Services model in particular and distributed computing in general. With the advent of technologies like XML, SOAP, WSDL, and UDDI, it becomes practical to design and deploy powerful, robust, sophisticated business applications that rely on the coordinated efforts of smaller, task-oriented units of work that can be "wired together" without respect to each unit's implementation details. (Separation of interfaces from implementations is a key feature of Web Services architectures.)
The Integration Manager Process Manager leverages many of today's most important enterprise-computing technologies, including:
SOAP (Simple Object Access Protocol) for platform-neutral handling of payloads and remote procedure calls
WSDL (Web Services Definition Language) for describing the public interfaces to services
J2EE (Java 2 Enterprise Edition) standards, for interoperability, security, scalability, and platform independence
In addition, Integration Manager's Process Manager runtime engine utilizes key features of the proposed Web Services Flow Language (WSFL) standard.
Processes are dynamic, stateful systems characterized by a rules-driven flow of data between participating activities. From an input-output point of view, a process receives input data, transforms and/or augments that data, and produces output data, much like any other service. And in fact, if the process is exposed as a Web Service (described by WSDL), it looks to the world like any other Web Service.
What makes a process different from a conventional Web Service is that it ties together—and orchestrates the flow of control and data between—relatively large units of work to accomplish a particular business function. A process is, in this sense, a meta-service that directs the interaction of other services (including, potentially, services that are external to the organization).
Some of the important differences between a conventional Integration Manager service and a process are summarized in the table below (and discussed in further detail in the sections to follow).
The units of work in a process are relatively large. (They encompass whole applications or services.) Likewise, operations on data tend to be conducted at a coarse (rather than fine) scale, occurring at the level of whole documents or document aggregates, rather than at the level of, say, nodes or nodesets. Fine-scale data manipulations occur inside the activities that make up the process.
One key distinguishing characteristic of a process (as opposed to an ordinary application or service) is that it is typically long-running. This means the process could have an execution time measured in hours, days, or even weeks, due to reliance on partner interactions, scheduled batch operations, human intervention at various levels, etc. For example, a process that obtains bids from contractors might very well require weeks to run to completion, whereas a credit-check application is expected to execute quickly, in real time. The credit-check task is best implemented as a discrete, standalone app: It processes information in straight-through fashion while the caller waits for a reply. By contrast, an RFP process involving (potentially) dozens of bidders, each with its own internal procedures and constraints, constitutes a large-scale, long-running process, which might be difficult or impossible to implement robustly as a monolithic, self-contained Web Service.
Persistence of state information is important for automated processes not only from a recovery standpoint but for efficient use of resources. A long-running process has to be able to deal with suspensions and resumptions of service, whether brought about administratively or through hardware downtime (scheduled or otherwise).
Integration Manager's Process Manager persists process-instance info to database storage, so that processes can be put to sleep as needed and woken up again in response to appropriate events (such as the arrival of data from a just-finished activity), thus freeing valuable RAM and CPU resources during long waits.
NOTE: State info is persisted at every stage of process execution (not just when a process goes to sleep), so that a server restart, for example, is not disruptive.
Processes typically involve more than simple "straight-through" processing. If each task in a process requires, say, three days to complete, a straight-through execution chain would mean that the process could require nine days to run. This could be very inefficient if the tasks are not directly dependent on one another. Splits and merges (parallel execution and resynchronization) are a common feature, therefore, of process control flows.
These concepts become clearer with an example. The following figure depicts a process that relies on parallel execution of tasks.
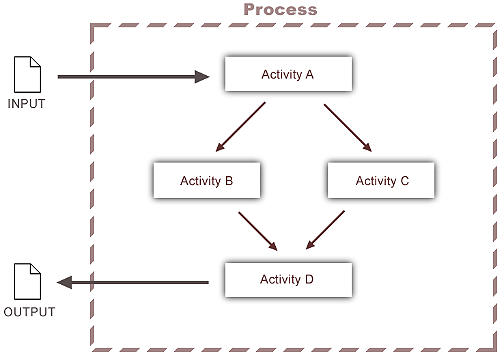
In this example, an incoming request (which could be a SOAP request, form data received via HTTP POST, etc.) triggers a process instance to handle the request. Activity A performs the initial processing, then calls two more activities (B and C) to do additional processing. The output of Activities B and C form the input to Activity D. Finally, the latter sends output to the requester.
It's important to note that this diagram could cover a wide range of scenarios. For example:
The request might come from inside the firewall or outside; and it could invoke the process asynchronously, or wait for the process to return (synchronous execution).
The process might or might not be designed to send output to the original requester. The output might actually be directed elsewhere.
Activity A might call B and/or C asynchronously, or synchronously.
The process might be designed such that if Activity B does not respond within a given timeout period, a retry will occur.
Activities B and C could be Web Services operated by remote business partners.
Activity D might be designed to execute as soon as B or C finishes (whichever is first), or it might be required to block until both B and C have delivered data. In the latter case, D might be required to choose data from B or C, but not both.
Any of the four activities shown could be processes in their own right. Or they could be Web Services, or Integration Manager components; or any combination of the above.
To be productive quickly with Integration Manager's Process Manager, it's important that you understand certain key terms and concepts. This section explains the terms and concepts you'll most need to know when working with the Process Manager.
Note that most of the process automation idioms discussed below—as implemented by Integration Manager's Process Manager—derive directly from the Web Services Flow Language (WSFL). For a more rigorous explanation of key terms, consult the WSFL specification at:
http://www-4.ibm.com/software/solutions/webservices/pdf/WSFL.pdf
Many of the fundamental concepts behind Integration Manager's vision of process automation stem, also, from WSDL (the Web Services Description Language). For a detailed discussion of WSDL, see
http://www.w3.org/TR/wsdl
NOTE: The more you understand WSDL and Web Services, the easier it will be for you to understand Integration Manager's vision of business process automation.
Integration Manager implements processes in terms of activities and links. Activities are the units of work that carry out the steps of the process; they may be Web Services, applications, or other processes. Links establish the possible control-flow paths between activities. Data moves through the process model via messages that are passed (in whole or in part) from one activity to another.
Activities represent the fundamental unit of work inside an automated process. In a Process Manager process model, an activity can be:
NOTE: The notion of a Web Service puts no restrictions on implementations. A Web Service can be implemented in any language, on any kind of platform, as long as it has an interface that can be described in WSDL.
In some cases, the components and services that you intend to use in a process model will have already been deployed on your server (or might already exist on the Web somewhere). That is to say, a process might simply "wire together" preexisting services. In other cases, you will develop components or services from scratch in order to meet process requirements. (Obviously, you can't test or deploy the process until all activities have been fully implemented.)
The trigger for a process provides data that can be mapped (as messages) to one or more start activities. The final activities of a process model are said to be end activities. (There can be more than one start activity to a workflow; and also more than one end activity.) Start and end activities are like any other activities, except that a start activity has no incoming control link and an exit activity has no outgoing control link.
It's possible that some start activities might not have any outgoing control links. For example, one of a process model's startup activities might be a JMS messaging component (built using Integration Manager's JMS Connect) that sends notifications to various queues asynchronously. If no downstream activities depend on data from the messaging activity, the messaging activity becomes both a start and an end activity.
Integration Manager's vision of process modelling makes a subtle but important distinction between tasks, activities, and implementations.
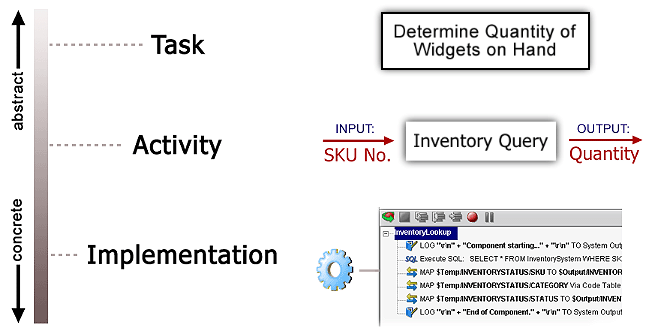
At the most abstract level, a task is a business function (which, in the real world, might go by a name like "Obtain Payment History," "Issue Purchase Order," or "Determine Back-Order Status"). Some business tasks are performed by humans; others are automated. Twentieth-century enterprise computing was concerned mainly with finding ways to automate or semi-automate business tasks.
Activities carry out tasks. The word "activity" implies a task that can be realized in software, but it does not imply anything about the actual implementation. One might know in advance what an activity's required inputs and outputs will be, but this simply means that the activity's interface needs are known. It doesn't mean underlying implementation details are known.
Implementations of activities can take many forms. This is the key intuition behind Web Services: Collaboration depends on interfaces, not implementations. Integration Manager's Process Manager takes full advantage of the Web Services model, allowing any service that has a WSDL-described interface to be used as an activity in a process. No restrictions are put on how activities are implemented. An activity might be a C++ program running on a business partner's web server, or it could be a custom EJB running on your own server, or a Integration Manager JDBC component, etc.
Activities operate on messages which, in turn, are composed of logical parts. The parts have name and type characteristics as defined in a schema. (The types can be canonical XSD data types, or complex types of your own, defined in custom schemas.) You can think of message parts as corresponding to the input and output data for activities.
If you are accustomed to thinking of service inputs and outputs as XML documents or DOMs, the message metaphor simply extends the input-doc/output-doc idiom to include the notion of collaboration between participants. A message implies an interface—a predefined set of operations on specific kinds of data. The key intuition is that a message, far from being a static container of data, carries with it an implicit operational semantic arising from the fact that messages and their parts can be named and therefore designated in operations associated with an interface.
NOTE: The concept of "data as message" is fundamental in WSDL. If you are not familiar with Web Service Description Language concepts involving messages, message parts, types, etc., you will find it helpful to read the WSDL spec.
The message metaphor is extremely powerful, because it is concrete enough, in practice, to allow applications to specify their interface needs (and so make interoperability possible), yet abstract enough to keep participants from having to know anything about their respective implementation details. This means that applications can be developed entirely independent of one another, in different times and places, by different programmers, yet interoperate with one another as the need arises.
By exploiting the message metaphor, Integration Manager's Process Manager achieves the goal of keeping interfaces and implementations isolated, for maximum flexibility in "wiring activities together."
Integration Manager's Process Manager "understands" the message-part semantics of WSDL-described services, in cases where activities are associated with WSDL.
Where activities consist of regular Integration Manager components, message parts needn't be explicitly defined in a schema. Component Input and Output DOMs are treated (by default) as messages.
Links define the allowable control-flow paths in a process model. Unless an activity is a start activity or an end activity (see below), it will have one or more incoming links and zero or more outgoing links.
NOTE: The mere existence of a link does not mean that the link will actually be followed at runtime. Transition-condition logic actually determines this. (See discussion to follow.)
In an operational sense, links tell the Process Manager runtime engine "what to do next" when an activity finishes.
Links also provide a convenient metaphor for visualizing control flow between activities in a design-time environment, since links can be drawn as lines or arrows connecting boxes or icons that represent activities.
A process is more than just a collection of links and activities. The links in a process model are like the roads in a highway system: They define all the possible paths that can be traversed, but not how they will actually be traversed. In the real world, the pattern of traffic flow through a road system is affected by traffic laws, clearance limits on overpasses, etc. Likewise, the flow of execution through a process model is dependent on various designed-in rules and constraints that apply at runtime.
Factors that affect runtime flow patterns include:
Link-traversal logic—Rules applied at the level of link transition conditions. (See below.)
Synchronization logic—Rules that govern the triggering of activities that have more than one incoming link. In some cases, a "join" activity will want all potential input activities to finish executing before the join is evaluated. In other cases, the target activity may be designed to begin executing as soon as the first input (from any incoming activity) arrives.
Retry and timeout policies—Some business interactions are required to adhere to elaborate try/timeout/retry requirements. For example: "Query this vendor and wait a maximum of two hours for acknowledgement. Query again, up to a total of three times." Every activity can have (but doesn't have to have) a timeout/retry policy.
These and other flow control factors are discussed in the sections immediately below.
Control flow is mediated by logic that you can apply at three key points in a process: link transition conditions, activity exit conditions, and join conditions.
The logic that determines whether or not a given link is actually traversed at runtime is called a transition condition. The transition logic returns a boolean value based, typically, on inspection of the data coming into the link. If the transition condition evaluates to true, the link is traversed; otherwise it is not.
Note that links are not required to have transition logic. By default, a link is traversed straight-through.
In the example shown previously (see Figure 4-3), the arrows between Activities constitute links. Each link could have an associated transition condition (expressed via XPath). Data at Activity A might or might not trigger Activity B depending on (for example) the type of data received or particular values contained in the data.
Every activity can have an exit condition. The exit condition is a logical expression that yields a boolean value. That value signifies whether or not the associated activity completed normally. If the exit condition evaluates to true at runtime, the outgoing link(s) can be followed. If it is false, the original activity will be reexecuted; but outgoing links will not be followed. (If an activity has no outgoing links, there is no exit condition.)
When two or more links meet at the same target activity, logic needs to be applied in order for execution to continue. This logic takes the form of a join condition in conjunction with a map policy.
The join condition is an expression that returns true or false based on examination of the truth values of incoming links. (The truth value is the final value of the link condition.)
NOTE: While exit and link conditions are expressed in XPath, join conditions are specified in straightforward fashion using AND, OR, NOT, and parentheses (for grouping).
When an activity has a join condition, the join logic is consulted to determine how to proceed. Consider the following scenarios.
Bids have been solicited from three suppliers. Company policy requires that bids must be received from all three suppliers before the rest of the process can be undertaken. The join condition specifies a logical-AND between link values. This pattern is called an AND-join.
A company allows each of its employees to choose between two retirement plans. Each plan has associated with it an activity that generates appropriate paperwork for the employee. The paperwork contains data that will be passed to a join activity. The join condition specifies something like:
(Plan1 AND NOT Plan2) OR (NOT Plan1 AND Plan2)
An activity receives input from any of several links. Any or all of the inputs can be used. This pattern is an OR-join.
The easiest way to visualize the relationship between the various kinds of flow logic is to think of the join condition as the "input-side" logic of an activity and the exit condition as the "output-side" logic.
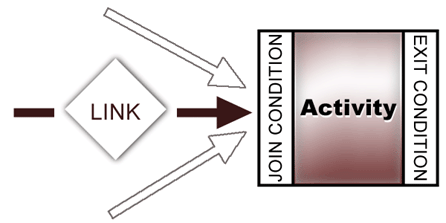
The join condition exists for the primary purpose of implementing synchronization logic of the OR/XOR/AND type. Data from one or more activities can be inspected and used as the basis for deciding whether the next activity executes or doesn't execute.
The exit condition is strictly a mechanism for determining whether the associated activity (once it finishes executing) has produced data suitable for use by the next activity (or activities). If an exit condition evaluates to true, it means the activity's data output met the minimum criteria for continuation to any outgoing links. All outgoing links will be followed if the exit condition is met. No links will be followed if it is not met.
Transition conditions determine whether the next activity can be entered at all, using output from the source activity. Since there is no way for a link to "know" anything about other link targets, transition logic tends to be relatively simple (in many cases merely defaulting to true).
NOTE: Conditional branching can be implemented at the link level. See the discussion under "Branch Logic" in the next chapter.
Joins can be fully synchronized (i.e., dependent on all source activities having finished executing), or asynchronous (allowing continuation as soon as data from any input activity arrives). By default, all joins occur in Deferred Mode, which means that all of a join's input activities must finish before the join condition can be evaluated. In this mode, a join condition will be evaluated exactly once.
For cases where the desired behavior is for a join activity to fire prior to the completion of all source activities, there is Immediate Mode. In this mode, the join condition is evaluated every time a source activity finishes. If there are multiple incoming links to a join, the join condition could be set to fire as soon as the first "true" link is known.
Integration Manager Process Manager allows setting Deferred or Immediate Mode on an activity-by-activity basis.
If a join condition is waiting on the truth value of an incoming link, but the link's condition is never evaluated (because flow was halted at some upstream point), the join will hang. Consider the following scenario:

In this flow graph, a join occurs at Activity5. In Deferred Mode, the join condition will not be evaluated until the truth conditions of Link3 and Link4 are both known. But assume that after Activity2 finishes normally, the link condition at Link2 evaluates to false. In that case, Activity4 will never fire; and if Activity4 never fires, Link3 will never be evaluated. (Link3 thereby becomes a dead link, and any segment of the flow graph that depends on it constitutes a dead path.) The net result is that the join at Activity 5 hangs.
To avoid this kind of synchronization failure, the Process Manager runtime engine performs a lookahead any time a condition expression evaluates to false. The lookahead is conducted as follows:
Starting at the false link (or false join condition, as applicable), the engine traverses all downstream links until either a join activity or an end activity is reached, whichever occurs first. At this point, traversal stops.
If the traversal path ends at a join, the engine determines whether the join condition can be evaluated (based on other link truth values and the join mode); if so, it is immediately evaluated with the incoming (dead) link having a value of false. Should the join condition then be true, the join is considered to be "alive" and no further dead-link traversal need occur. If the join is false—meaning that its outgoing links are dead—its status must be set to false, and the lookahead must continue downstream from that point.
This "dead-path elimination" procedure ensures that no false condition can cause a downstream join to hang. It is carried out automatically, as needed, by the runtime engine.
When multiple activities direct their output at a single activity, the potential exists for source activities to overwrite each other's data at the input to the target activity. A map policy specifies the mapping order and overwrite policy that will be followed for resolving conflicts.
There are three policy choices:
First writer wins (FWW)—This means that the first data to be mapped into the activity's input template will be used as input to the join activity. Any subsequent messages cannot overwrite.
Last writer wins (LWW)—The last data to arrive are mapped without regard to how any previous data were mapped.
Map Order—Data mappings will occur in a user-specified order, without regard to time-of-arrival.
See "Map Policy" in the chapter called "Creating and Testing Processes" later in this guide.
An activity (whether it is part of a join or not) can have explicitly defined timeout/retry behavior. That is to say, if the activity doesn't produce usable output within a specified timeout period, a retry can be attempted, up to some maximum number of retries. Retries can be repeated at a user-specified interval.
NOTE: Timeout/Retry behavior is available on a per-activity basis but is entirely optional.
Timeouts and retries are an important part of many standard business interactions and are formalized, in some cases, by industry standards, such as the Partner Interface Processes defined by RosettaNet. Integration Manager's Process Designer allows timeout and retry options to be set on an activity-by-activity basis.
In automated business processes, as in human-mediated ones, the flow of data is coupled to the flow of control, but not always tightly. Some activities, for example, require data from outside the normal chain of control; the last activity to execute might need some piece of data from the first activity that executed, which could be many control links away. Other activities require data on the input side but have no "output data" per se. (The "output" of the activity might be physical goods loaded onto a truck.) There are many real-world situations in which data flow and control flow take different paths.
Integration Manager's Process Manager allows data and control to follow their own paths, subject to one restriction: When an activity requires data from an activity to which it is not directly linked, the source activity must be reachable if one were to "swim upstream" (never downstream) through the control path, as shown in the following diagram.
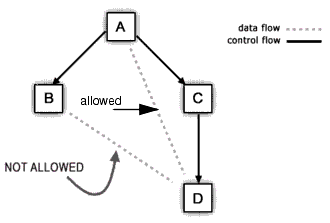
In the example shown above, data can flow along the path from A to C to D, and it is also permissible for D to obtain data directly from A, because A lies on the (entirely one-way) path from A to C to D. But it is not permissible for D to obtain data from B. (The path from B to A to C to D involves first moving upstream from B to A, then downstream from A to C to D.)
It is not safe for D to obtain data from B, because the link topology does not ensure that B completes before D. One of the guarantees made by control links is that any activity on the "upstream" terminus of a link must execute before the activity on the downstream end can execute. In the above example, B might take three days to execute, but C might execute in a matter of seconds. The only safe way to get data from B to D is to create a control link between the two activities, thus making D a "join" activity.
Without getting too heavily into the details of data propagation, it should be mentioned in passing that data transfer (or mapping) across activities follows its own unique set of rules, distinct from the control-flow rules that Process Designer depicts with icons and arrows. (Flow graphs created in the Designer show control flow rather than data flow.) Data routing is easier to understand than control flow, but some unique twists apply; see the next chapter for details.
A process can respond to any of several lifecycle events, so-called because they affect the overall execution of the process.
Spawn—A spawn event invokes or instantiates a process in an asynchronous mode. The spawning agent does not want to wait (block) for the process to return, so after the process is activated the caller expects to return to whatever it was doing as soon as the spawned process returns a set of instance data (a "receipt") to the caller, indicating that a unique process instance has been invoked successfully. The caller can, if necessary, later use this data to query the process for status updates, etc.
Call—When an entity calls a process, the caller expects to receive data back from the process in real time (which is to say, synchronously). The call invokes the process, and the process runs to completion before returning. The output of the process is directed back at the caller.
Suspend—A suspend stops, but does not destroy, an ongoing process. Control flow is temporarily interrupted. This type of lifecycle event typically occurs in an administrative context.
Resume—The inverse of suspend. A process that was previously suspended continues operation. Again, this is an event of primarily administrative importance.
Processes you create using the Integration Manager Process Manager are implemented and managed at three different levels.
Design Level: The design layer has the responsibility of managing the visual or user-interface representation of a process. This layer lets you define activities, connect activities via links, determine message mappings, and assign logic to transition points (links, joins, and exit conditions), using a rich set of visual design tools. The process model that you create here becomes the basis for the metadata representation of the process (see below) that the runtime engine uses for creating and managing process instances.
Metadata Level: At the non-visual level, a process model is stored in metadata form as an XML description of activities, links, input and output messages, etc. This metadata description provides all of the information needed to instantiate the process in a runtime environment. No presentation-related information is needed at this level.
Runtime Level: The runtime layer manages the execution of process instances. It maintains state information, manages lifecycle events, implements timeout/retry behavior, mediates the flow of data and control between activities, and performs housekeeping tasks involving (among other things) persistence of instance data to a database. Administrative access to processes occurs via this layer.
The graphic below summarizes the relationship of these layers.
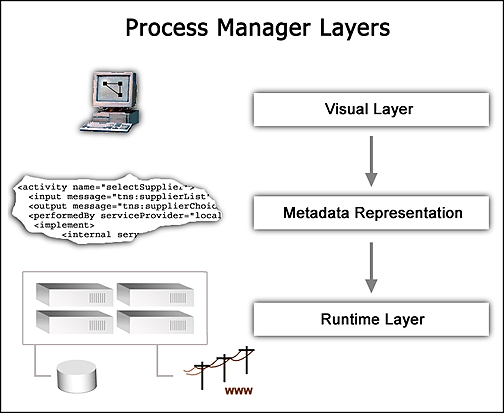
The layers drive each other from the top down (never from the bottom up). For example, the visual or design layer drives the creation of the process's metadata representation, but the metadata layer never dictates a particular presentation. Likewise, the metadata layer sets the rules for the runtime layer, but the runtime engine never modifies the metadata; the metadata constitutes a blueprint of the process.
The design-time and runtime responsibilities of the layers (and their constituents) are shown in greater detail in the graphic below.
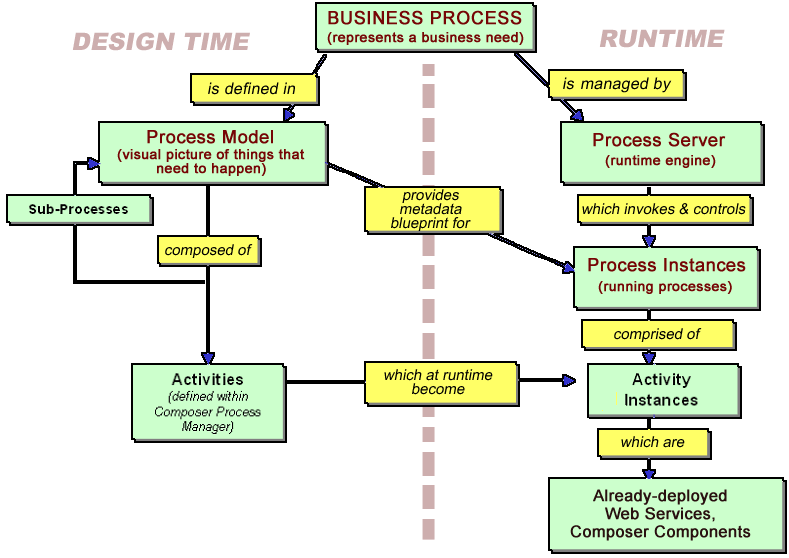
Notice that the process ultimately "sits on top of" and relies, for its concrete runtime implementation, on already-deployed services and components. (Some of these could be remote Web Services.) Deploying a process that uses prebuilt services can be likened to deploying a management framework whose sole job is to invoke existing applications according to special rules.
Existing applications might play roles in any number of processes. For example, there might be a Process A that uses Activities X, Y, and Z; and a Process B that uses Activities X, Z, and Q. If Activity Z is a Web Service with a public URI, it might actually play a role in a remote process in use at another company.
The plug-and-play nature of Web Services brings great power and flexibility to process management and is key to understanding how to use Integration Manager's Process Manager effectively.
By now, you are probably starting to have many questions about the ways in which processes can be modelled using Integration Manager's Process Manager and what the limitations are, if any, on process design. The answers to many questions will become clearer in subsequent chapters, but for now, here are a few quick answers to Frequently Asked Questions.
Can I Create or Edit Integration Manager Components within Process Manager?
Yes. The Process Manager design-time editor runs entirely within Integration Manager. You can have multiple components, services, and processes open at the same time and switch between windows freely. In fact, in animation mode, you can step over and into process activities, and if a given activity's underlying implementation was built in Integration Manager, you can step into the activity-implementation's action model and step through it before returning to the process itself. You have the ability to debug action models and process models all in the same environment.
Can I Begin Designing a Process Even if Some Activities Have not Yet Been Implemented?
Yes. You can put placeholder activity icons on the process canvas and name them, draw links between them, etc., arbitrarily. To perform useful message-part mappings, of course, you will need to designate actual components or services for each activity, but even then, the components do not have to be completely built. If an activity is a Web Service, its mappings can be specified in the process model even before the service is built, so long as WSDL exists for the service.
Can I Run a Process in the Design-Time Environment for Test Purposes?
Yes. You can run a process within Integration Manager, in animation mode, much the same way that you would execute a Integration Manager Component in animation mode. This is a unique capability among workflow and process automation tools. In other workflow products, you may be able to create a "skeleton" process fairly quickly, but you usually cannot implement activity-layer functionality without leaving the design-time environment to do low-level programming; and when the activity layer has been implemented, you generally can't test it in the original design environment. With Integration Manager Process Manager, you can design, test, and debug activities as well as processes without leaving the design environment, dramatically shortening the development cycle.
Is It Possible to Import WSFL Flow Models Created in Another Environment?
No. Integration Manager's Process Manager is not designed to import workflow models from other sources. WSFL is too immature a specification at this point to provide all the functionality required by users, and it's unlikely, therefore, that two vendors would implement two WSFL solutions in a compatible manner. In addition, the presentation (graphing) layer of Integration Manager Process Manager is not directly driven by the metadata layer; in other words, no particular graphical representation of a process is inherent in a WSFL metadata model, and the Process Designer would not have any a priori notion of how to display your graph.
Can I Edit My Process-Model Metadata in an XML Editor?
You should never have to hand-edit the metadata descriptions of process models produced by Integration Manager's Process Manager. Direct editing of the metadata is not recommended.
Does Process Manager Support Parallel Split, Exclusive Choice, and other Branching Constructs?
Yes. By allowing the designer to place boolean logic on the entry and exit sides of activities (in join and exit conditions) as well as on individual links, WSFL is able to accommodate arbitrarily complex flow patterns without having to define special-purpose constructs. So the short answer is that Integration Manager Process Manager (following WSFL's lead) does not define special branch or join flow primitives. But you can easily achieve any desired branch/join behavior by means of appropriate transition conditions.
Does Process Manager Support Looping?
Yes, although backwards-facing links are not allowed. Links that connect downstream activities to source activities produce what's called a cyclic graph, which is not supported by WSFL because of the potential for reentrancy-related problems. (These problems are discussed more fully in the next chapter, along with the looping constructs actually supported by Process Manager.)
Can I Use the Process Manager for Document Routing and User Agent Functionality?
Queue-based workflows with human-facing activities can be created using Process Manager (see the "Advanced Topics" chapter). The concepts of queues containing work items, work-item priority, addressees (individuals) with roles, timeouts, locks, and administrative control over and browsing of queues are all supported by Process Manager. Also, the various actions that support these features are available for use across all component types (and all Component Editors) in Integration Manager.
Will Automated Processes Put Huge Demands on My System?
No. The load and performance characteristics of a system running processes under Integration Manager's Process Server are determined by the activities that make up the process. The Process Server itself incurs very little processing overhead because one instance of the Process Server controls any number of running processes. Also, since processes are typically long-running, it's usually the case that most of the pieces of an in-progress process instance spend the majority of their time in a sleep state. During these waiting periods, activities exist in persistent storage so that they do not actually consume CPU cycles.
Can I Start and Stop a Server While a Process is Running?
Yes, because process state information is persisted for each process instance on an ongoing basis. Also, processes are generally long-running and spend most of their time asleep. Suspension of a running process instance is supported by WSFL and by Process Manager. You can suspend any process at any time via the Process Server Console.
Must All Activities Be Implemented as Web Services?
No. Your activities can take the form of Integration Manager Components or Web Services.
Must Processes be Exposed as Web Services?
No. They can be, but they don't have to be.
Copyright © 2004 Novell, Inc. All rights reserved. Copyright © 1997, 1998, 1999, 2000, 2001, 2002, 2003 SilverStream Software, LLC. All rights reserved. more ...