
This chapter presents some fundamental decisions you should make and essential advice you should consider before starting your SilverStream development project. You'll learn about:

Once you know the requirements for your SilverStream application, you'll need to choose the most appropriate architectures and features to implement them. There are a few basic choices you should make early on, because they have to do with the fundamental nature of your application.
These choices relate to the following application components:
The client portion of a SilverStream application is commonly a graphical user interface that:
Client choices
The particular kind of client you choose to build depends largely on the nature of your end-user community and their machines.
Let Internet, extranet, or intranet users run the application from a browser | HTML client. This can include:
|
Let intranet or extranet users run the application as a dedicated program |
When you have the choice, you'll need to consider factors such as user-interface style, user familiarity, security, performance, and administration to decide between an HTML or Java client. For instance, an HTML client may be favored when a universal interface and low administration are required. A Java client may be better for applications that demand a richer interface.
What about applets?
You can certainly build SilverStream applications that use applets to run Java (such as forms or views) in HTML pages on a client's browser. However, experience has shown browser support for applets to be problematic. If you want to run Java code on your client, it's usually better to do that with SilverJRunner or a Java application.
NOTE Including forms or views in pages is not supported in SilverStream Version 3.0 due to limitations of the Sun Java 1.2 browser plug-in. We hope to re-enable this support in SilverStream in the future. See the release notes for updated information.
What kind of processing should clients do?
No matter which kinds of clients you develop, the code you write for them should focus on user-interface processing not business logic. For instance, coding validation rules into a client is generally appropriate, but the rules for processing validated data should reside on a SilverStream server. The next section explains why and what your options are.
Business logic refers to the enterprise-specific knowledge that you encode in your applications. You can think of it as the rules for performing particular business operations, such as:
For several reasons, this kind of processing belongs on the application-server (middle) tier of your computing environment. First of all, it often represents an important (if not strategic) corporate asset requiring some degree of central control and security. It also needs to be accessible by multiple applications, because there's always some common body of logic that applies across your systems and should be reusable.
These requirements are much more easily met when your business logic is implemented on a SilverStream server, not scattered across many desktops. Administration is also simplified when your applications are partitioned this way, since logic updates can be made centrally at any time and take effect immediately (without any changes to end-user machines).
Business logic choices
Since business logic tends to be strategic, the choice of technology for implementing it tends to be so too. Conformance to industry standards is often a key criterion (to ensure the longer-term integrity and adaptability of this code asset), although factors such as feature support, performance, and ease of development can also become important.
The following table outlines your basic choices for implementing business logic on a SilverStream server.
Conform to the J2EE standard for encapsulating business logic on the middle tier | |
Conform to the CORBA standard for encapsulating business logic on the middle tier | CORBA (Common Object Request Broker Architecture) objects.
|
Of these, EJB session beans and CORBA objects are strategic choices that you'll typically choose in the context of an organization-wide technology plan. They have all the advantages of being robust industry standards but require a certain level of commitment in terms of design and development process.
In contrast, you'll probably use triggered business objects in a more tactical way, to meet some specific application requirements with a minimum of development effort.
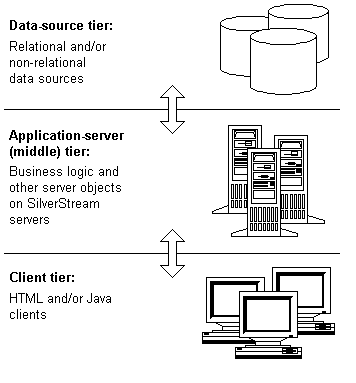
To retrieve and update data, your applications will most likely need to access one or more enterprise data sources. Those might be relational databases (such as Oracle) or non-relational data sources (such as Lotus Notes or CICS). In any case, you should think of them as a separate tier of your application architecture, distinct from both the client tier and the application-server (middle) tier.
Within this architecture, notice that the data-source tier is isolated from direct access by client machines. Instead, all retrieval and update requests for your enterprise data sources are handled on the SilverStream server. This helps protect the integrity of those data sources, enables you to manage data-source connections and network traffic, and eliminates the need to install connectivity software on your clients for specific data sources.
To give clients and other consumers access to enterprise data, you'll use the distributed data cache that the SilverStream server provides as an integral part of its data services. This caching facility works like a staging area that brings needed data as close to its consumer as possible for efficiency. If the consumer is a Java client, the data is automatically cached on the client machine when required. If the consumer is an object on the SilverStream server, the data is cached there. Consumers can make updates to the cache, then ask the SilverStream server to apply them to the actual enterprise data sources.
Data access choices
Once you understand this general framework, it's time to consider the specific choices available to fulfill the data-access requirements of your SilverStream applications.
Conform to the J2EE standard for encapsulating data access on the middle tier | |
Access common relational databases or other standard data sources from your SilverStream pages, forms, and business objects | The built-in data facilities in the SilverStream Designers. These include:
|
Provide custom data access to your application Provide SilverStream data services to external application components | |
As you can see, these choices mostly depend on the types of data sources you need to access (standard or custom) and the nature of the applications you're accessing them from (developed in the SilverStream Designers or externally). As a result, it's usually clear what to use.
One choice that might require more thought is EJB entity beans. Like the session beans discussed earlier, their use is typically part of an organization-wide technology strategy. They provide the advantages of being a robust standard but require a certain level of commitment in terms of design and development process.
When designing an application, keep in mind that your SilverStream servers themselves represent a significant aspect of the overall architecture. The configuration of those servers should be included in the plan to ensure that the application is developed, tested, and deployed to work as required in the ultimate production environment. This is especially important if server administration is handled by someone outside of your development and testing organization.
Server configuration choices
The following table lists some key server configuration choices you should consider in your application planning.
Secure the application (or components of it) from unauthorized access | One or more server security features, including:
|
Scale the application to run acceptably under anticipated production conditions | Clusters of SilverStream servers (to provide load balancing and failover).
|
 For a comprehensive look at planning the configuration of your SilverStream servers, see the server configuration chapter in the Administrator's Guide. It covers several typical intranet and Internet scenarios, including the use of:
For a comprehensive look at planning the configuration of your SilverStream servers, see the server configuration chapter in the Administrator's Guide. It covers several typical intranet and Internet scenarios, including the use of:
In addition to good application planning, proper setup of the development environment is an important aspect of conducting a successful project. Before starting to build SilverStream applications, you should make sure you configure your development environment appropriately in terms of:
You can choose the development tools you want to use to build SilverStream applications, including:
Your choices will typically depend on a combination of these factors:
The next section lists the features that are tool-dependent.
Use the following table to determine which kind(s) of development tools you need to build the features required by the SilverStream applications you've planned.
SilverStream pages (visual servlets) | JavaServer Pages (JSP) Static HTML pages | |
SilverStream forms (and views) | Forms from a third-party IDE Standard Java applications (graphical or command-line) Standard Java applets | |
Enterprise JavaBeans (EJB) session beans SilverStream triggered business objects | Enterprise JavaBeans (EJB) session beans SilverStream triggered business objects | |
Enterprise JavaBeans (EJB) entity beans SilverStream data source objects (DSOs) | Enterprise JavaBeans (EJB) entity beans SilverStream data source objects (DSOs) | |
Standard Java classes | Standard Java classes Media: images, sounds, etc. |
You'll learn more about building these features later in this guide.
Once you select the development tools to use, you need to install and configure them on each appropriate developer machine.
Setup requirements in Coding Java for SilverStream Applications |
SilverStream applications are typically developed by teams, and team development always requires a code management strategy. This strategy should:
Preferred configuration
The preferred development environment configuration for meeting these requirements consists of:
For information on using source control in the SilverStream Designer, see the SilverStream source control chapter in the online Tools Guide.
Moving to test
Once objects are checked into source control, they can be migrated to a QA (quality assurance) environment for integration testing. The QA environment typically consists of:
If your project is large or you want more migration control, you might consider introducing a pre-test staging environment (consisting of a SilverStream server and metadata databases) where developed objects from source control can be integrated prior to formal testing.
Moving to production
When all testing is complete, objects can be published from QA to the production environment (which includes SilverStream servers, metadata databases, and live databases of application data).
If your project is large or you want more migration control, you might consider introducing a pre-production staging environment (consisting of a SilverStream server and metadata databases) where tested objects from source control can be integrated prior to deployment.
To learn more about publishing to the production environment, see
Deploying and Distributing Applications.
For detailed information on setting up SilverStream development, test, and production environments, see the server configuration chapter in the Administrator's Guide.
To ensure the smoothest release integration path, experience shows that it's best to use the same database platform(s) in every phase of your project--from development to test to production. In other words, if your production application is to access an Oracle database for its data, you should access an Oracle database in your development and test environments too.
Avoiding a database platform migration can save you lots of time and effort when deploying your application. Otherwise, you may need to work out DBMS differences in data types, identifier names, and other details.
For more information about database platform migration, see
Publishing across database types in
Deploying and Distributing Applications.
As with any development effort, you should establish the standards and conventions for your SilverStream project before work begins and make sure everyone follows them. The larger your project and team, the more important are such guidelines to ensure a clean and maintainable application.
Some of the common ones you should consider establishing include:
Many books and other resources are readily available (from a variety of public and commercial sources) to help you choose UI conventions that reflect accepted design principles.
Some groups choose loose coding conventions, others more particular ones. A lot depends on the nature of your staff and enterprise. In any case, if you conduct code reviews as part of your development process, you can check for compliance to these guidelines at that time.
To learn about the naming conventions recommended by SilverStream, see the chapter on naming SilverStream objects in the online General Reference.
This section provides some additional advice, gathered from SilverStream experts, that you should keep in mind throughout your development work. It includes:
Remember these tips when planning your SilverStream projects.
Test early and often
Don't wait until the end to test your application. Begin the project with a UI prototype that end users can try out. Then, set milestones over the course of the project for conducting functional, performance, and scalability tests. Such testing often leads to substantial improvements in an application by uncovering a variety of problems while you have time to fix them.
Simulate deployment conditions when testing
Make sure your tests reflect the production environment as much as possible, including:
This will give you a much better picture of your application's usability, performance, and scalability. If you test only on your local development machine or in an overly simplified network configuration, you may be surprised with problems at deployment time.
Back up your databases regularly
Schedule periodic backups of all the databases (SilverMaster, metadata, and data) used by your SilverStream applications. Doing so can save you much time and effort if you need to recover from a problem.
Remember these tips when designing your SilverStream applications.
Retrieve only the data you need
When designing for optimal performance, the most important thing you can do is make sure your application doesn't retrieve too much data from the database. This can often be as simple as formulating appropriate selection criteria (in Where clauses) for the rows to get. Think in terms of retrieving the 100 or 200 rows you really need at the moment, instead of all 10,000 rows of a table.
Sometimes applications are required to retrieve large amounts of data, but you can still deliver good performance by using techniques such as these:
Use cached data whenever possible
When you use SilverStream data access features in your application, you automatically get intelligent data caching across the tiers of your system. To capitalize on the performance benefits of this service, make sure your application uses cached data whenever appropriate (instead of going back to the database for rows).
You should also consider doing your own caching of other data your application uses. Here's a good rule of thumb: If the life of a piece of data is longer than the time needed to create it, then that data is a candidate for caching.
Design pages modularly
To make your pages as reusable and maintainable as can be:
Remember these tips when writing code for your SilverStream applications.
Avoid creating unnecessary object instances
Instantiation consumes both time and memory, so make sure you really need the objects you create. In particular, watch out for overuse of Strings and concatenation, since this can cause the VM to generate a lot of separate objects without you realizing it.
For example, the following code creates several unnecessary object instances:
String a = "a"; String b = "b"; String c = "c"; String result = a + b + c;
It should be rewritten as follows:
StringBuffer result = new StringBuffer("abc");
Avoid synchronized objects
For best performance, minimize the use of synchronized objects in your application. For example, the Hashtable class is synchronized, so any persistent object that uses Hashtables will cause a queue of clients waiting to take their turn through the object's code.
If you can't avoid synchronization, it's better to use synchronized methods within objects rather than synchronized objects.