Collector Development Guide
PLUG-IN CONTENTS
In the previous section we walked through a simple build process and got a look at a Collector in the process of executing. You may have noticed that the files in the running Collector looked a little bit different than what you see when you look at the Collector in the development directory - the build process does a fair amount of conversion and manipulation to turn the Collector source into a running Collector.
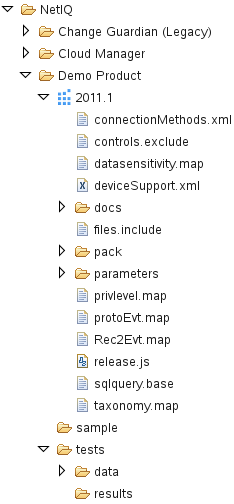 Take a look at a typical Collector as it appears in the SDK, at right. We'll walk through each folder and file in turn
so you know what each item represents.
Take a look at a typical Collector as it appears in the SDK, at right. We'll walk through each folder and file in turn
so you know what each item represents.
- The top-level folder is named after the vendor that provides the product this Collector is a parser for. Any given vendor can have multiple products underneath it. The vendor name is set when you create a new Collector, and should match what the vendor calls itself on their website (avoid '-' and '_'). You should check to make sure a particular vendor name doesn't already exist before creating a new one.
- The next level lists the product name you entered for this Collector during creation, which should again match the current official product name per the vendor. Do not include any version information at this level, if you can avoid it. In general, we assume a Collector will provide parsing for an entire product line, no matter what version, and will auto-detect if it has to apply different parsing for different versions. This simplifies Collector selection and deployment. In some rare cases, however, this s more trouble than it's worth.
- The next directory labeled 2011.1 is the actual Collector directory, meaning everything below this level is relevant to this specific Collector with this specific revision. You may see older Collector versions (such as the 6.1 Collector) at this level as well which are mostly just archival. Note that this directory is named after the version of the SDK against which this Collector will be tested and built.
- Note that the three items above can be renamed at will. You might change the vendor and/or product if, for example, the vendor is acquired or the product name is changed. Any changes you make here will rename the Collector in terms of the output file name, in the documentation, etc. Also note that although you can manually rename the Collector directory itself to point to a newer SDK, in general we will provide conversion scripts to do so for you and also fix up the Collector internals at the same time.
- Under the 2011.1 directory:
- The connectionMethods.xml file contains the list of supported Connectors that work with this Collector (see Connector Interaction).
- The controls.exclude file lists the template controls that should be excluded from the final Collector Pack (see below).
- The datasensitivity.map file contains a list of sensitive files or directories on the source, like /etc/passwd on SUSE Linux.
- The deviceSupport.xml contains the list of event sources that this Collector can process data from (see Metadata). This is where the individual product version(s) this Collector knows how to handle should be documented.
- The docs directory contains the embedded plug-in documentation template (see Documentation). This is a simple LibreOffice document template that you edit to fill in common information like how to set up the source device and so forth.
- In some cases a particular product will produce event records that share many features with other products. To handle this situation, on occasion we extract common code, attribute maps, and other resources and place them in a common location. The files.include file lists any files that should be copied from the common location and added to the plug-in during the build to support those common features.
- The pack directory contains the Collector Pack for this Collector (see Collector Pack). The Collector Pack contains a set of content in a control structure that can be used to support operational and security analysis for this particular Collector. Some of this content is custom for this particular Collector, some comes from a central template and when it is copied into this Collector's Pack, filtering for Collector-specific data is injected. The controls.exclude file above determines which templatized controls are excluded during Collector Pack creation.
- The parameters directory contains the plug-in parameters (see Parameters) which control run-time configuration of the Collector.
- The privlevel.map file contains a list of user accounts with native elevated privileges for the product, like 'root' for SUSE Linux and 'Administrator' for Windows.
- The protoEvt.map file contains the static Event fields that are preset for data from this Collector (see Event Construction).
- The Rec2Evt.map contains the Record to Event conversion DataMap (see Event Construction).
- The release.js file contains the actual methods that are run when the plug-in is executed. As described previously, you don't have to worry about the overall control flow of the Collector; the base template will call the methods defined in this file to set up the Collector environment and parse the event data. You just have to define how the Collector will parse the data.
- The sqlquery.base file contains the template SQL query used by this Collector (if it gets data from a DB) (see Connector Interaction).
- The taxonomy.map file contains a KeyMap used to generate taxonomy for each event (see Event Construction).
- The sample directory is a place to put sample input or output files - in general these should be Connector Dumps
Note that what's shown here represents only the default set of resources provided in the template. A given Collector may not contain one or more of these resources (for example, Collectors that do not query databases can eliminate the sqlquery.base file), or may contain additional custom resources such as JavaScript files and map files.
The Plug-in SDK provides a suite of editors and utilities to help you edit and manage the resources that make up the Collector source. During the succeeding sections, we'll walk you through how these are used.
- Forward to Data Parsing
- Back up to Develop to Sentinel
Collector Development Guide
- Overview
- Getting Started
- Initial Build
- Plug-in Contents
- Data Parsing
- Build Process
- Event Construction
- Taxonomy
- Connector Interaction
- Common Code
- Parameters
- Additional Information