Collector Development Guide
EVENT CONSTRUCTION
In previous topics we've covered the general process of creating and building a Collector, and even delved into some aspects of parsing the input record to extract data to put into the output event. In this section we'll assume that you've already parsed the input, and describe the methods by which you then construct a proper output Sentinel Event.
To provide a little more detail on our assumptions:
- You should be familiar with the Sentinel Event Schema, namely the fields that it provides and how they are defined. The specific fields that Collectors set are listed in the Rec2Evt.map file. Note that the field documentation contains notes about how the fields should be populated with individual pieces of data.
- You should have gone through the exercise of examining your input data, identifying the important information included in the event record, and picking the appropriate Sentinel fields to put that data in. We'll discuss below what to do when there does not appear to be a simple, natural match in the schema.
- Of course, you should also have created a new Collector, written parsing logic, and captured some sample data to test against, as described in Initial Build.
General Event Construction Concepts
To help clarify the way in which the output Sentinel event is constructed, let's walk through the different phases in the basic Collector execution template and discuss what happens with the output Event object in each phase. Recall our flow diagram:
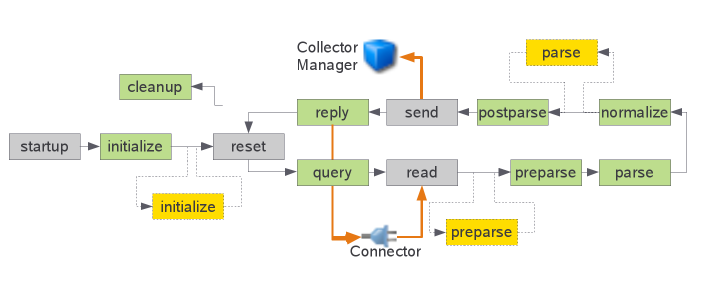
- Starting with the reset stage, the Collector is reset and variables are set to default values. One such variable is
the
curEvtglobal variable, which is destroyed and replaced with a new instance of anEventobject. This new object is not empty, however, it is pre-initialized with some default values, particularly those defined as part of the prototype event which are defined in the fileprotoEvt.map. - Next, during the
readstage, a global objectrecis created of classRecordthat represents the log record returned from the data source. - During
preparse,parse, andnormalizedata is parsed out of therecobject and stored in other temporary variables and/orrecattributes. In some cases extracted values are immediately set directly in the current event objectcurEvt, but see below. - In the
sendstage, thecurEvtobject pulls all those temporaryrecattributes into the appropriate event fields, fills in a lot of other information, and then sends itself to Sentinel. - It should also be noted that after the Collector sends the event, the Collector Manager and other Sentinel services may inject additional information, such as the UUIDs of processing components and contextual data from the Mapping Service.
There are a couple important points to remember here. First, note that the current event is created as a global object called
curEvt, and the input record as a global called rec. But the various parsing methods are called as prototypes on the
Record class and are passed the current event as a parameter — as a result, most of the code you actually write will
refer to rec as this and curEvt as e (the name given to the passed-in parameter). Second,
although in the template these methods are called in a very predictable order and in most cases there would be no difference between
referring to rec or curEvt directly, it's good practice to think about these parsing methodologies in object-oriented
terms, e.g. to think of a call to rec.parse(curEvt) as a request to the rec object to parse itself. In theory, one
could construct a completely different Record object, perhaps called myRec, and then call the parse() method on that.
In that case one would have to be very careful to always refer to the Record object that is being parsed as this within the
parsing methods, or you will get inconsistent results.
There are a couple implications to using this object-oriented approach. In many cases, event sources will have several different classes of events
that they produce, and it's quite common to have the first few lines of parse() be dedicated to identifying which class of event the Collector
is dealing with. Then, instead of putting all the code for all the possible classes into a large parse() method, one might construct
several modular methods, one for each class, and call the appropriate one from the parse() method. If the class name or ID can come directly from the
event data, then you can use some tricks within JavaScript to name the actual parsing method after the class name/ID, like this:
Record.prototype.parse = function(e) {
// Extract class name
this.class = this.s_RXBufferString.someMethod();
this["parse-" + this.class](e);
}
Record.prototype["parse-class1"] = function(e) {
// Parsing code for class1
}
Record.prototype["parse-class2"] = function(e) {
// Parsing code for class2
}
Note that we've created these subparsers as prototypes on the Record object, again so they can be called against any object of type Record,
and note that we pass the current event into them, in case it's needed. Doing this consistently can make your code more modular and reusable.
The other important implication here is that since the current event is a class (Event), it is in general not best practice to directly
assume a particular implementation of that class. Although the current implementation is set up so that each attribute of Event corresponds to
the standard English label within the Sentinel Event Schema, and one can simply set such fields directly
(as in curEvt.InitiatorUserName = "text"), it is generally bad practice to do so. By using the member access methods of the Event class
and the abstractions provided by the mapping classes (see below), you make your code safer for use in future iterations of the SDK.
Methods for Setting Output Event Fields
Now that we've provided the general background above and described how the output event object is handled by the template, let's cover how you as a developer can make changes to what the output event looks like. First, there are five basic ways to do this:
- Prototype Event
- The prototype event is used to construct the initial event object before the Collector does anything to it. You can think of fields set by the prototype event as defaults that can be overridden by later code.
- Explicit Field Assignment
- This method should only be used in very specific circumstances and should generally be avoided, as mentioned above. But one can if necessary explicitly assign values to event fields directly.
- Event Member Functions
- The
Eventclass includes several special methods to set fields that have complex types or special meaning in the schema. These methods should be used for setting timestamps, the taxonomy, etc. - Record-to-Event Conversion
- This conversion map specifies how the parsed input Record will be converted into the output Sentinel Event.
- Framework Field Injection
- This last method is not part of the Collector at all, but covers fields that are set by the base Collector template, by the Event Source Management/Collector Manager framework, and by the Mapping Service.
We'll cover each of these methods in detail below.
Prototype Event
The standard Collector template includes a file, protoEvt.map, which contains the static Event fields that are preset for output
from this Collector. Data that is configured in this file will be hard-coded to appear in every event that passes through this Collector unless
overridden by later code. In essence, the file contains a list of the fields that should be set in the output event along with the static values
that they should be set to. The prototype event is used by the framework to set some standard fields automatically, such as the field that contains
the name of this Collector, but can also be used to set other fields that the developer wants defaulted to a particular value.
If you would like to use this method to set some of the output event fields in your Collector, simply move the relevant field name
from the Rec2Evt.map file into the protoEvt.map file, then set the static value you want on the right-hand side.
You can't use any of the event data for this purpose, or any JavaScript variables at all. You can, however, use the
build-time replacement variables that describe attributes of the plug-in.
Please note that it is a very bad idea to modify the pre-existing lines in the file as those are set to Sentinel Plug-in defaults, and may be used by downstream components in various ways.
Explicit Field Assignment
It is also possible, in the context of the template parsing methods, to directly set field attributes in the output event. For example:
Record.prototype.parse = function(e) {
// Parse out the username
this.username = this.s_RXBufferString.someMethod();
e.InitiatorUserName = this.username;
};
In this scenario, you simply use the Event object that was passed in to the parsing method, e, and set an
attribute on that object that has the same name as one of the standard English-language field labels as documented as part of the
Event Schema (note that different versions of the SDK might have slightly different field names).
Having said this, however, you should in general not use this method for setting output fields. Doing so can easily break the Collector, especially if you later try to repackage the Collector using a newer version of the SDK.
There are a few exceptions to this rule, for example you will notice that in some of our template example code we do this, but the reason we do this in our example code is that we can't predict what you as the developer will do later on (particularly with the Record-to-Event conversion) and hence we can't rely on the normal methodology. It's probably a good idea to replace our example code with your own code that uses the correct approach.
Event Member Functions
There are a few special methods used to set complex output fields in the output Event, which need to be applied directly to the output Event
object. In most circumstances this is the e object, but in some scenarios (Events that are constructed using Sessions or other
advanced techniques) you may need to use a different object. Examples include setting the timestamps of the event, and the taxonomy.
Refer to the API documentation for the Event class for the full list of supported methods,
and how to use them.
Separate chapters in the Guide will discuss details on handling time and taxonomy.
Record-to-Event Conversion
The most common method for setting output fields is the Record-to-Event conversion map, Rec2Evt.map. This file contains a
DataMap that maps which fields in the input Record get
placed into which fields in the output Event.
This file is extremely useful for event sources that have regular output formats like databases, name-value pair formats, or delimited text formats where the meanings of event fields are relatively fixed. You can do a minimal amount of parsing of data to extract each data element, and then simply specify where to put that data in the output event.
For event sources with variable output formats or where the meaning of a given field changes, you might need to do some additional manipulation to the input data before you can apply this map. This will be a balancing act for each Collector you develop.
As you implement your preParse(), parse(), and normalize() methods, for the most part you will be chopping up the
input Record object and storing parts of the input data back into attributes of that same object. You may need to apply conditional logic in
some cases to determine which Record attribute to store a particular piece of data in. Then you simply list the source fields in the Record object
on the corresponding lines of this map file.
The format of the file is:
<field name of event object>,<attribute in Record object>
The field names of the output Event are pre-assigned and should not be edited. When specifying the source fields, do not include
the object name itself, i.e. if you want to copy rec.object[0].username into the Event field InitUserName, then the file
will look like:
InitUserName,object[0].username
The initial template for Rec2Evt.map includes all the fields that are typically set by a Collector using this method. After you are done specifying all the fields you want to capture, you can delete any lines that have nothing in the second column. The exception are Reserved and Customer variables, which have to be manually added to this map.
Framework Field Injection
There are a number of Event fields that are not settable by the Collector itself, but instead are set by the template or the underlying framework.
This includes fields like SentinelProcessTime, which describes when Sentinel processed the event, various IDs of objects that the event data
flowed through, TenantName which is set by a Collector parameter, and various Asset/Identity/Vulnerability fields that are set by
the Mapping Service.
The Notes section of the Event Schema documentation explains which fields are set by the Collector and which
are set by other components. As a general rule, if the field is not listed in the Rec2Evt.map file, then it should not be set by the Collector.
The exceptions to this rule are the Reserved variables and the Customer variables, see below.
Rules for Field Usage
In many cases it is obvious which field in the output event should be used to hold a particular piece of information from the input record. In other cases you will find that there is no natural match, that you have some data that you think is important but can't decide where to put it.
The decision tree for how to decide where to put a particular piece of information is usually something like this:
- Research the information and figure out what it represents. See if you can find an explicit match in the normal Sentinel Event Schema. Pay particular attention to the Notes that describe how each field should be used.
- If the data doesn't quite match the intended purpose of a single field, consider normalizing the data in some way - perhaps you can create a KeyMap to map to normalized Sentinel data, or perhaps you can split the data up into subcomponents that match more explicitly.
- If the data still doesn't match, decide whether the data needs to be placed in its own field (this is typically true if consumers will need
to correlate on that field separately from all other data), or whether it's more informational. If the latter, you can use the
Event.add2EI()method to add your data to theExtendedInformationfield as part of a JSON structure. - If you decide that the data is indeed important enough that it needs to be placed in its own separate field, then review the list of Reserved variables
and find an unused variable of the correct type. Then add that variable to the
Rec2Evt.mapfile and use it like any other field. You should also clearly document your use of that field. If you believe that similar data would be generally useful to have in its own field, feel free to suggest so on the Forum and we'll take your ideas into consideration.
If you have any questions, post your questions to the Forum and we will try to help you.
- Forward to Taxonomy
- Back up to Develop to Sentinel
Collector Development Guide
- Overview
- Getting Started
- Initial Build
- Plug-in Contents
- Data Parsing
- Build Process
- Event Construction
- Taxonomy
- Connector Interaction
- Common Code
- Parameters
- Additional Information